 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill the Carbon Border Adjustment Mechanism Impact European Electricity Prices? A GNN-Based Network Analysis
May 05, 2026The European Union's Carbon Border Adjustment Mechanism (CBAM) creates a complex challenge for the interconnected European electricity market. Traditional static analyses often miss the cross-border spillover effects that are vital for understanding this policy. This paper addresses this gap by developing a spatio-temporal Graph Neural Network (GNN) framework. It quantifies how CBAM affects electricity prices and carbon intensity (CI) at the same time. We modeled a subgraph of eight European countries. Our results suggest that CBAM is not just a uniform tax. Instead, it acts as a tool that transforms the market and creates structural differences. In our simulated scenarios, we observe that low-carbon countries like France and Switzerland can gain a competitive advantage. This suggests a potential decrease in their domestic electricity prices. Meanwhile, high-carbon countries like Poland face a double burden of rising costs. We identify the primary driver as a fundamental shift in the market's merit order.
RedVLA: Physical Red Teaming for Vision-Language-Action Models
Apr 24, 2026The real-world deployment of Vision-Language-Action (VLA) models remains limited by the risk of unpredictable and irreversible physical harm. However, we currently lack effective mechanisms to proactively detect these physical safety risks before deployment. To address this gap, we propose \textbf{RedVLA}, the first red teaming framework for physical safety in VLA models. We systematically uncover unsafe behaviors through a two-stage process: (I) \textbf{Risk Scenario Synthesis} constructs a valid and task-feasible initial risk scene. Specifically, it identifies critical interaction regions from benign trajectories and positions the risk factor within these regions, aiming to entangle it with the VLA's execution flow and elicit a target unsafe behavior. (II) \textbf{Risk Amplification} ensures stable elicitation across heterogeneous models. It iteratively refines the risk factor state through gradient-free optimization guided by trajectory features. Experiments on six representative VLA models show that RedVLA uncovers diverse unsafe behaviors and achieves the ASR up to 95.5\% within 10 optimization iterations. To mitigate these risks, we further propose SimpleVLA-Guard, a lightweight safety guard built from RedVLA-generated data. Our data, assets, and code are available \href{https://redvla.github.io}{here}.
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
Strategic Decision-Making Under Uncertainty through Bi-Level Game Theory and Distributionally Robust Optimization
Nov 07, 2025In strategic scenarios where decision-makers operate at different hierarchical levels, traditional optimization methods are often inadequate for handling uncertainties from incomplete information or unpredictable external factors. To fill this gap, we introduce a mathematical framework that integrates bi-level game theory with distributionally robust optimization (DRO), particularly suited for complex network systems. Our approach leverages the hierarchical structure of bi-level games to model leader-follower interactions while incorporating distributional robustness to guard against worst-case probability distributions. To ensure computational tractability, the Karush-Kuhn-Tucker (KKT) conditions are used to transform the bi-level challenge into a more manageable single-level model, and the infinite-dimensional DRO problem is reformulated into a finite equivalent. We propose a generalized algorithm to solve this integrated model. Simulation results validate our framework's efficacy, demonstrating that under high uncertainty, the proposed model achieves up to a 22\% cost reduction compared to traditional stochastic methods while maintaining a service level of over 90\%. This highlights its potential to significantly improve decision quality and robustness in networked systems such as transportation and communication networks.
Rejoining fragmented ancient bamboo slips with physics-driven deep learning
May 13, 2025



Bamboo slips are a crucial medium for recording ancient civilizations in East Asia, and offers invaluable archaeological insights for reconstructing the Silk Road, studying material culture exchanges, and global history. However, many excavated bamboo slips have been fragmented into thousands of irregular pieces, making their rejoining a vital yet challenging step for understanding their content. Here we introduce WisePanda, a physics-driven deep learning framework designed to rejoin fragmented bamboo slips. Based on the physics of fracture and material deterioration, WisePanda automatically generates synthetic training data that captures the physical properties of bamboo fragmentations. This approach enables the training of a matching network without requiring manually paired samples, providing ranked suggestions to facilitate the rejoining process. Compared to the leading curve matching method, WisePanda increases Top-50 matching accuracy from 36\% to 52\%. Archaeologists using WisePanda have experienced substantial efficiency improvements (approximately 20 times faster) when rejoining fragmented bamboo slips. This research demonstrates that incorporating physical principles into deep learning models can significantly enhance their performance, transforming how archaeologists restore and study fragmented artifacts. WisePanda provides a new paradigm for addressing data scarcity in ancient artifact restoration through physics-driven machine learning.
CM-MaskSD: Cross-Modality Masked Self-Distillation for Referring Image Segmentation
May 22, 2023Referring image segmentation (RIS) is a fundamental vision-language task that intends to segment a desired object from an image based on a given natural language expression. Due to the essentially distinct data properties between image and text, most of existing methods either introduce complex designs towards fine-grained vision-language alignment or lack required dense alignment, resulting in scalability issues or mis-segmentation problems such as over- or under-segmentation. To achieve effective and efficient fine-grained feature alignment in the RIS task, we explore the potential of masked multimodal modeling coupled with self-distillation and propose a novel cross-modality masked self-distillation framework named CM-MaskSD, in which our method inherits the transferred knowledge of image-text semantic alignment from CLIP model to realize fine-grained patch-word feature alignment for better segmentation accuracy. Moreover, our CM-MaskSD framework can considerably boost model performance in a nearly parameter-free manner, since it shares weights between the main segmentation branch and the introduced masked self-distillation branches, and solely introduces negligible parameters for coordinating the multimodal features. Comprehensive experiments on three benchmark datasets (i.e. RefCOCO, RefCOCO+, G-Ref) for the RIS task convincingly demonstrate the superiority of our proposed framework over previous state-of-the-art methods.
Med-Tuning: Exploring Parameter-Efficient Transfer Learning for Medical Volumetric Segmentation
Apr 21, 2023Deep learning based medical volumetric segmentation methods either train the model from scratch or follow the standard "pre-training then finetuning" paradigm. Although finetuning a well pre-trained model on downstream tasks can harness its representation power, the standard full finetuning is costly in terms of computation and memory footprint. In this paper, we present the first study on parameter-efficient transfer learning for medical volumetric segmentation and propose a novel framework named Med-Tuning based on intra-stage feature enhancement and inter-stage feature interaction. Given a large-scale pre-trained model on 2D natural images, our method can exploit both the multi-scale spatial feature representations and temporal correlations along image slices, which are crucial for accurate medical volumetric segmentation. Extensive experiments on three benchmark datasets (including CT and MRI) show that our method can achieve better results than previous state-of-the-art parameter-efficient transfer learning methods and full finetuning for the segmentation task, with much less tuned parameter costs. Compared to full finetuning, our method reduces the finetuned model parameters by up to 4x, with even better segmentation performance.
Heterogeneous Information Network based Default Analysis on Banking Micro and Small Enterprise Users
May 02, 2022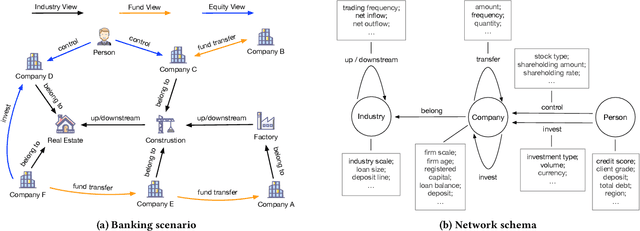
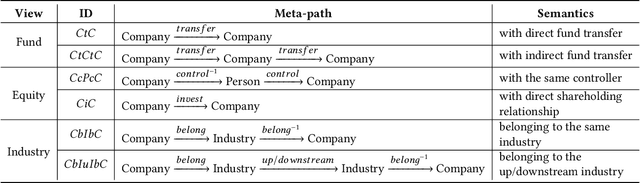
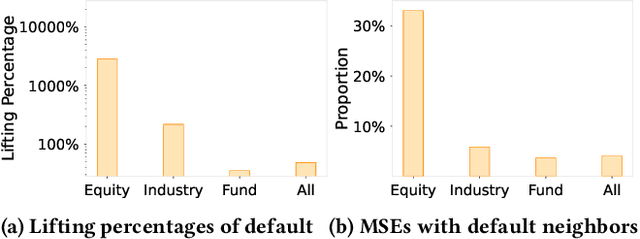

Risk assessment is a substantial problem for financial institutions that has been extensively studied both for its methodological richness and its various practical applications. With the expansion of inclusive finance, recent attentions are paid to micro and small-sized enterprises (MSEs). Compared with large companies, MSEs present a higher exposure rate to default owing to their insecure financial stability. Conventional efforts learn classifiers from historical data with elaborate feature engineering. However, the main obstacle for MSEs involves severe deficiency in credit-related information, which may degrade the performance of prediction. Besides, financial activities have diverse explicit and implicit relations, which have not been fully exploited for risk judgement in commercial banks. In particular, the observations on real data show that various relationships between company users have additional power in financial risk analysis. In this paper, we consider a graph of banking data, and propose a novel HIDAM model for the purpose. Specifically, we attempt to incorporate heterogeneous information network with rich attributes on multi-typed nodes and links for modeling the scenario of business banking service. To enhance feature representation of MSEs, we extract interactive information through meta-paths and fully exploit path information. Furthermore, we devise a hierarchical attention mechanism respectively to learn the importance of contents inside each meta-path and the importance of different metapahs. Experimental results verify that HIDAM outperforms state-of-the-art competitors on real-world banking data.