 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
Paper and Code
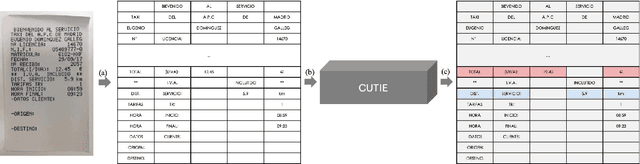
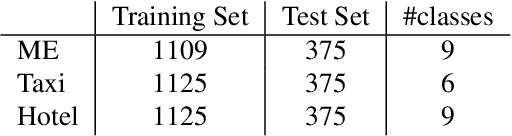
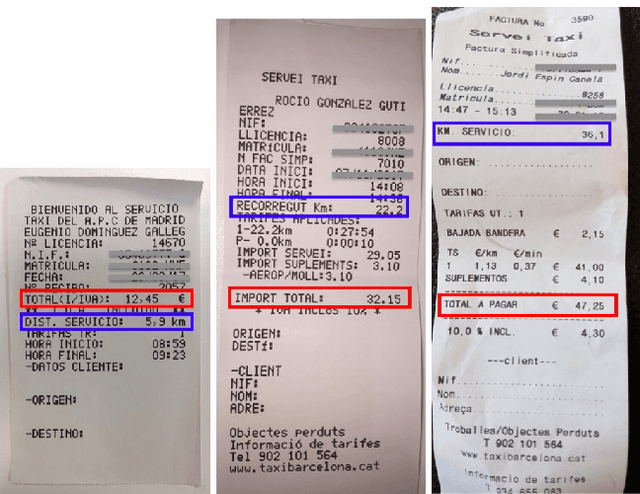

Extracting key information from documents, such as receipts or invoices, and preserving the interested texts to structured data is crucial in the document-intensive streamline processes of office automation in areas that includes but not limited to accounting, financial, and taxation areas. To avoid designing expert rules for each specific type of document, some published works attempt to tackle the problem by learning a model to explore the semantic context in text sequences based on the Named Entity Recognition (NER) method in the NLP field. In this paper, we propose to harness the effective information from both semantic meaning and spatial distribution of texts in documents. Specifically, our proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations. We further explore the effect of employing different structures of convolutional neural network and propose a fast and portable structure. We demonstrate the effectiveness of the proposed method on a dataset with up to $4,484$ labelled receipts, without any pre-training or post-processing, achieving state of the art performance that is much higher than BERT but with only $1/10$ parameters and without requiring the $3,300$M word dataset for pre-training. Experimental results also demonstrate that the CUTIE being able to achieve state of the art performance with much smaller amount of training data.