 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecSys Arena: Pair-wise Recommender System Evaluation with Large Language Models
Dec 15, 2024Evaluating the quality of recommender systems is critical for algorithm design and optimization. Most evaluation methods are computed based on offline metrics for quick algorithm evolution, since online experiments are usually risky and time-consuming. However, offline evaluation usually cannot fully reflect users' preference for the outcome of different recommendation algorithms, and the results may not be consistent with online A/B test. Moreover, many offline metrics such as AUC do not offer sufficient information for comparing the subtle differences between two competitive recommender systems in different aspects, which may lead to substantial performance differences in long-term online serving. Fortunately, due to the strong commonsense knowledge and role-play capability of large language models (LLMs), it is possible to obtain simulated user feedback on offline recommendation results. Motivated by the idea of LLM Chatbot Arena, in this paper we present the idea of RecSys Arena, where the recommendation results given by two different recommender systems in each session are evaluated by an LLM judger to obtain fine-grained evaluation feedback. More specifically, for each sample we use LLM to generate a user profile description based on user behavior history or off-the-shelf profile features, which is used to guide LLM to play the role of this user and evaluate the relative preference for two recommendation results generated by different models. Through extensive experiments on two recommendation datasets in different scenarios, we demonstrate that many different LLMs not only provide general evaluation results that are highly consistent with canonical offline metrics, but also provide rich insight in many subjective aspects. Moreover, it can better distinguish different algorithms with comparable performance in terms of AUC and nDCG.
Post-training Model Quantization Using GANs for Synthetic Data Generation
May 10, 2023Quantization is a widely adopted technique for deep neural networks to reduce the memory and computational resources required. However, when quantized, most models would need a suitable calibration process to keep their performance intact, which requires data from the target domain, such as a fraction of the dataset used in model training and model validation (i.e. calibration dataset). In this study, we investigate the use of synthetic data as a substitute for the calibration with real data for the quantization method. We propose a data generation method based on Generative Adversarial Networks that are trained prior to the model quantization step. We compare the performance of models quantized using data generated by StyleGAN2-ADA and our pre-trained DiStyleGAN, with quantization using real data and an alternative data generation method based on fractal images. Overall, the results of our experiments demonstrate the potential of leveraging synthetic data for calibration during the quantization process. In our experiments, the percentage of accuracy degradation of the selected models was less than 0.6%, with our best performance achieved on MobileNetV2 (0.05%). The code is available at: https://github.com/ThanosM97/gsoc2022-openvino
CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
Apr 04, 2019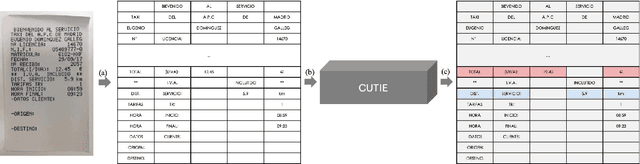
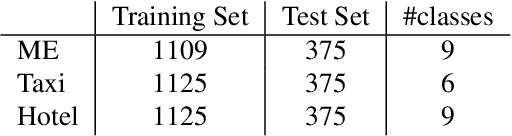
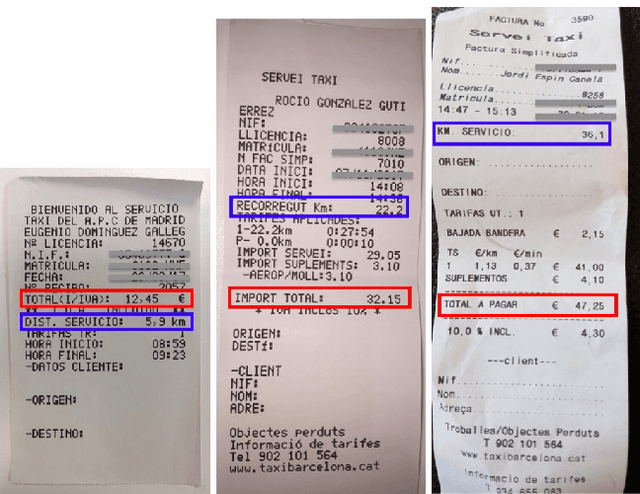

Extracting key information from documents, such as receipts or invoices, and preserving the interested texts to structured data is crucial in the document-intensive streamline processes of office automation in areas that includes but not limited to accounting, financial, and taxation areas. To avoid designing expert rules for each specific type of document, some published works attempt to tackle the problem by learning a model to explore the semantic context in text sequences based on the Named Entity Recognition (NER) method in the NLP field. In this paper, we propose to harness the effective information from both semantic meaning and spatial distribution of texts in documents. Specifically, our proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations. We further explore the effect of employing different structures of convolutional neural network and propose a fast and portable structure. We demonstrate the effectiveness of the proposed method on a dataset with up to $4,484$ labelled receipts, without any pre-training or post-processing, achieving state of the art performance that is much higher than BERT but with only $1/10$ parameters and without requiring the $3,300$M word dataset for pre-training. Experimental results also demonstrate that the CUTIE being able to achieve state of the art performance with much smaller amount of training data.