 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-SpecQD: Multi-Level Speculative Decoding with Quantized Drafts
Mar 17, 2025Speculative decoding (SD) has emerged as a method to accelerate LLM inference without sacrificing any accuracy over the 16-bit model inference. In a typical SD setup, the idea is to use a full-precision, small, fast model as "draft" to generate the next few tokens and use the "target" large model to verify the draft-generated tokens. The efficacy of this method heavily relies on the acceptance ratio of the draft-generated tokens and the relative token throughput of the draft versus the target model. Nevertheless, an efficient SD pipeline requires pre-training and aligning the draft model to the target model, making it impractical for LLM inference in a plug-and-play fashion. In this work, we propose using MXFP4 models as drafts in a plug-and-play fashion since the MXFP4 Weight-Only-Quantization (WOQ) merely direct-casts the BF16 target model weights to MXFP4. In practice, our plug-and-play solution gives speedups up to 2x over the BF16 baseline. Then we pursue an opportunity for further acceleration: the MXFP4 draft token generation itself can be accelerated via speculative decoding by using yet another smaller draft. We call our method ML-SpecQD: Multi-Level Speculative Decoding with Quantized Drafts since it recursively applies speculation for accelerating the draft-token generation. Combining Multi-Level Speculative Decoding with MXFP4 Quantized Drafts we outperform state-of-the-art speculative decoding, yielding speedups up to 2.72x over the BF16 baseline.
Post-training Model Quantization Using GANs for Synthetic Data Generation
May 10, 2023Quantization is a widely adopted technique for deep neural networks to reduce the memory and computational resources required. However, when quantized, most models would need a suitable calibration process to keep their performance intact, which requires data from the target domain, such as a fraction of the dataset used in model training and model validation (i.e. calibration dataset). In this study, we investigate the use of synthetic data as a substitute for the calibration with real data for the quantization method. We propose a data generation method based on Generative Adversarial Networks that are trained prior to the model quantization step. We compare the performance of models quantized using data generated by StyleGAN2-ADA and our pre-trained DiStyleGAN, with quantization using real data and an alternative data generation method based on fractal images. Overall, the results of our experiments demonstrate the potential of leveraging synthetic data for calibration during the quantization process. In our experiments, the percentage of accuracy degradation of the selected models was less than 0.6%, with our best performance achieved on MobileNetV2 (0.05%). The code is available at: https://github.com/ThanosM97/gsoc2022-openvino
Enabling NAS with Automated Super-Network Generation
Dec 20, 2021
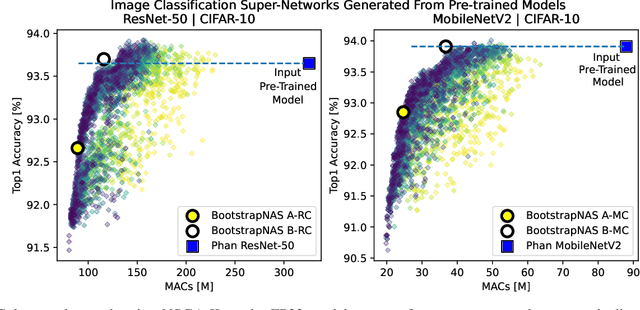
Recent Neural Architecture Search (NAS) solutions have produced impressive results training super-networks and then deriving subnetworks, a.k.a. child models that outperform expert-crafted models from a pre-defined search space. Efficient and robust subnetworks can be selected for resource-constrained edge devices, allowing them to perform well in the wild. However, constructing super-networks for arbitrary architectures is still a challenge that often prevents the adoption of these approaches. To address this challenge, we present BootstrapNAS, a software framework for automatic generation of super-networks for NAS. BootstrapNAS takes a pre-trained model from a popular architecture, e.g., ResNet- 50, or from a valid custom design, and automatically creates a super-network out of it, then uses state-of-the-art NAS techniques to train the super-network, resulting in subnetworks that significantly outperform the given pre-trained model. We demonstrate the solution by generating super-networks from arbitrary model repositories and make available the resulting super-networks for reproducibility of the results.
STC speaker recognition systems for the NIST SRE 2021
Nov 03, 2021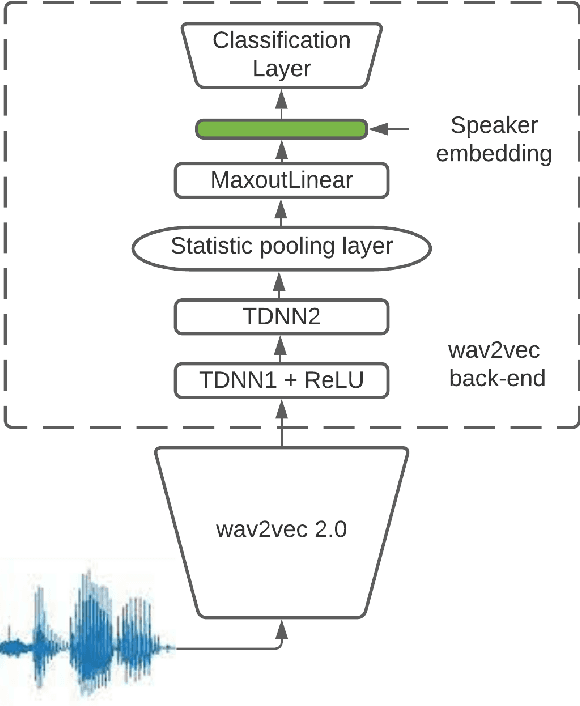
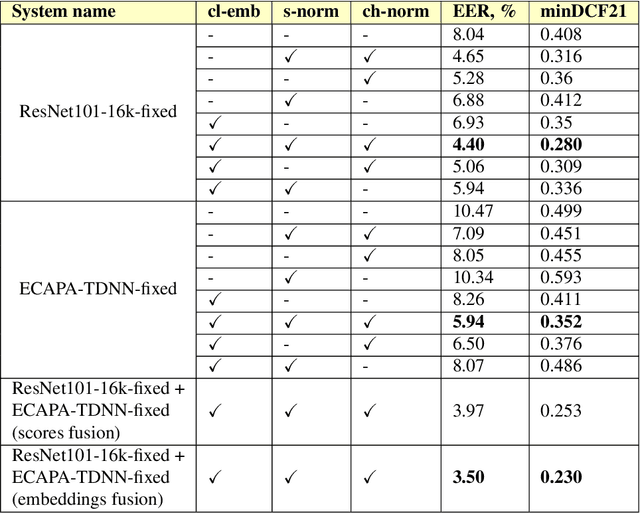
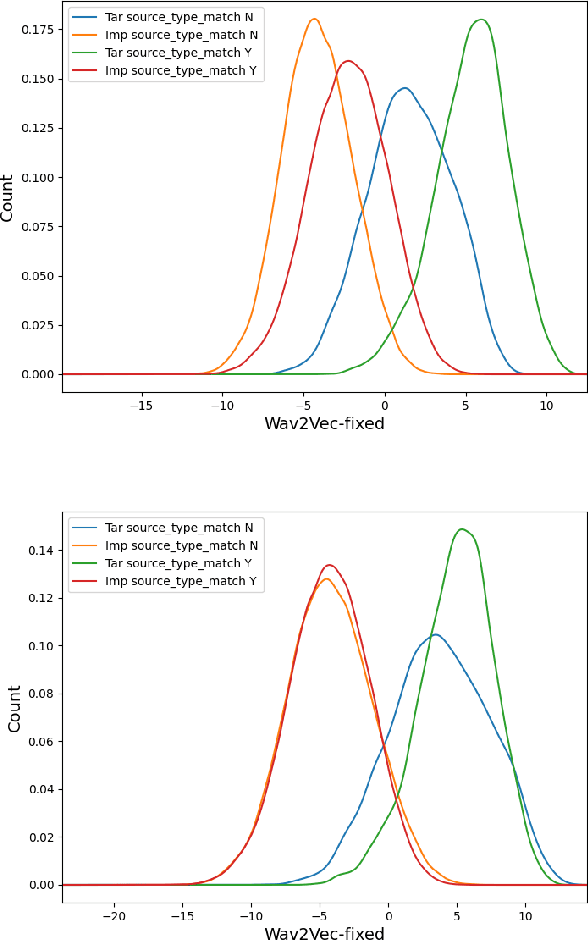

This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.
Post-training deep neural network pruning via layer-wise calibration
Apr 30, 2021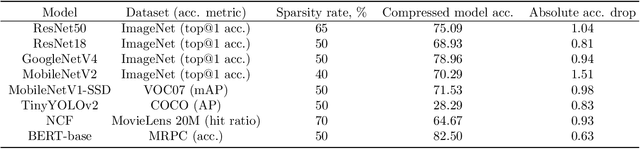
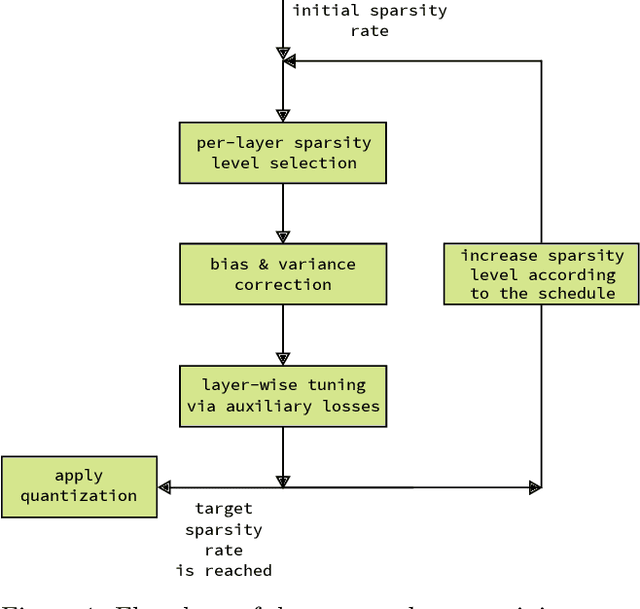


We present a post-training weight pruning method for deep neural networks that achieves accuracy levels tolerable for the production setting and that is sufficiently fast to be run on commodity hardware such as desktop CPUs or edge devices. We propose a data-free extension of the approach for computer vision models based on automatically-generated synthetic fractal images. We obtain state-of-the-art results for data-free neural network pruning, with ~1.5% top@1 accuracy drop for a ResNet50 on ImageNet at 50% sparsity rate. When using real data, we are able to get a ResNet50 model on ImageNet with 65% sparsity rate in 8-bit precision in a post-training setting with a ~1% top@1 accuracy drop. We release the code as a part of the OpenVINO(TM) Post-Training Optimization tool.
Neural Network Compression Framework for fast model inference
Mar 12, 2020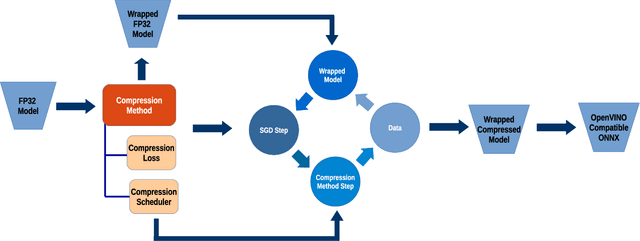
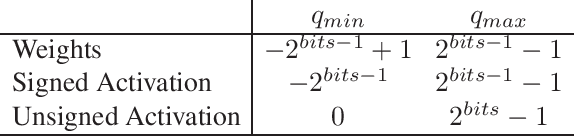

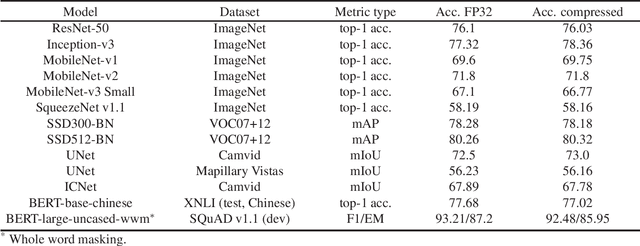
In this work we present a new framework for neural networks compression with fine-tuning, which we called Neural Network Compression Framework (NNCF). It leverages recent advances of various network compression methods and implements some of them, such as sparsity, quantization, and binarization. These methods allow getting more hardware-friendly models which can be efficiently run on general-purpose hardware computation units (CPU, GPU) or special Deep Learning accelerators. We show that the developed methods can be successfully applied to a wide range of models to accelerate the inference time while keeping the original accuracy. The framework can be used within the training samples, which are supplied with it, or as a standalone package that can be seamlessly integrated into the existing training code with minimal adaptations. Currently, a PyTorch version of NNCF is available as a part of OpenVINO Training Extensions at https://github.com/opencv/openvino_training_extensions/tree/develop/pytorch_toolkit/nncf
Deep Speaker Embeddings for Far-Field Speaker Recognition on Short Utterances
Feb 14, 2020
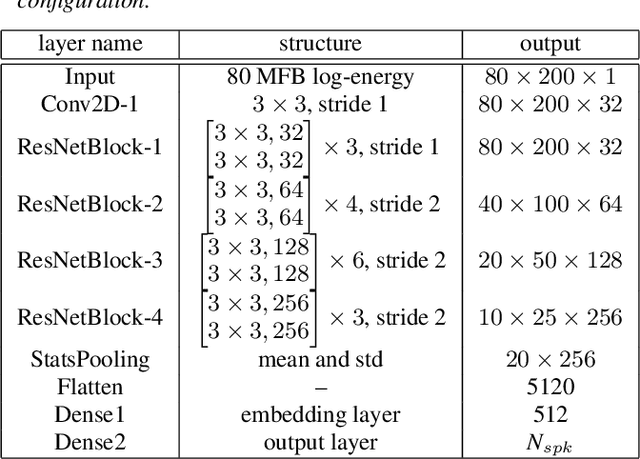
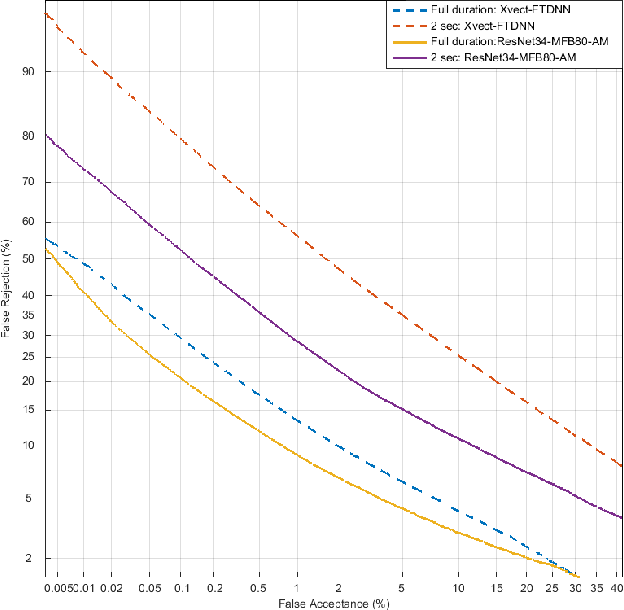
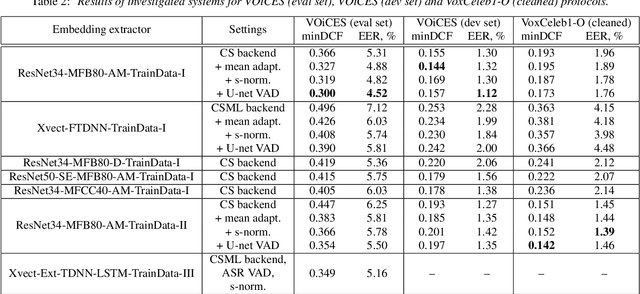
Speaker recognition systems based on deep speaker embeddings have achieved significant performance in controlled conditions according to the results obtained for early NIST SRE (Speaker Recognition Evaluation) datasets. From the practical point of view, taking into account the increased interest in virtual assistants (such as Amazon Alexa, Google Home, AppleSiri, etc.), speaker verification on short utterances in uncontrolled noisy environment conditions is one of the most challenging and highly demanded tasks. This paper presents approaches aimed to achieve two goals: a) improve the quality of far-field speaker verification systems in the presence of environmental noise, reverberation and b) reduce the system qualitydegradation for short utterances. For these purposes, we considered deep neural network architectures based on TDNN (TimeDelay Neural Network) and ResNet (Residual Neural Network) blocks. We experimented with state-of-the-art embedding extractors and their training procedures. Obtained results confirm that ResNet architectures outperform the standard x-vector approach in terms of speaker verification quality for both long-duration and short-duration utterances. We also investigate the impact of speech activity detector, different scoring models, adaptation and score normalization techniques. The experimental results are presented for publicly available data and verification protocols for the VoxCeleb1, VoxCeleb2, and VOiCES datasets.
Lightweight Network Architecture for Real-Time Action Recognition
May 21, 2019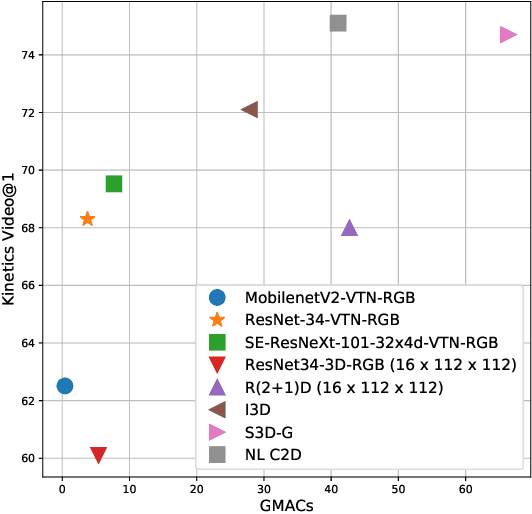


In this work we present a new efficient approach to Human Action Recognition called Video Transformer Network (VTN). It leverages the latest advances in Computer Vision and Natural Language Processing and applies them to video understanding. The proposed method allows us to create lightweight CNN models that achieve high accuracy and real-time speed using just an RGB mono camera and general purpose CPU. Furthermore, we explain how to improve accuracy by distilling from multiple models with different modalities into a single model. We conduct a comparison with state-of-the-art methods and show that our approach performs on par with most of them on famous Action Recognition datasets. We benchmark the inference time of the models using the modern inference framework and argue that our approach compares favorably with other methods in terms of speed/accuracy trade-off, running at 56 FPS on CPU. The models and the training code are available.
Development of Real-time ADAS Object Detector for Deployment on CPU
Nov 14, 2018
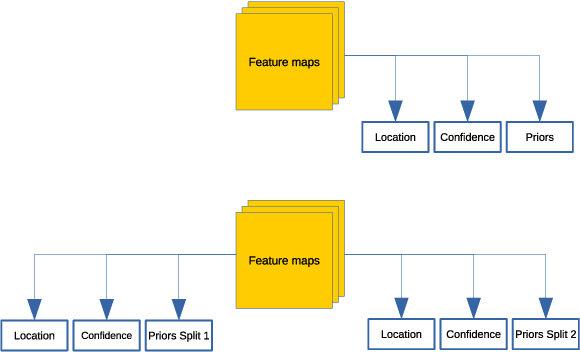


In this work, we outline the set of problems, which any Object Detection CNN faces when its development comes to the deployment stage and propose methods to deal with such difficulties. We show that these practices allow one to get Object Detection network, which can recognize two classes: vehicles and pedestrians and achieves more than 60 frames per second inference speed on Core$^{TM}$ i5-6500 CPU. The proposed model is built on top of the popular Single Shot MultiBox Object Detection framework but with substantial improvements, which were inspired by the discovered problems. The network has just 1.96 GMAC complexity and less than 7 MB model size. It is publicly available as a part of Intel$\circledR$ OpenVINO$^{TM}$ Toolkit.
Audio-replay attack detection countermeasures
May 24, 2017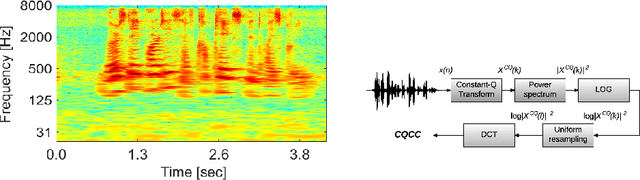


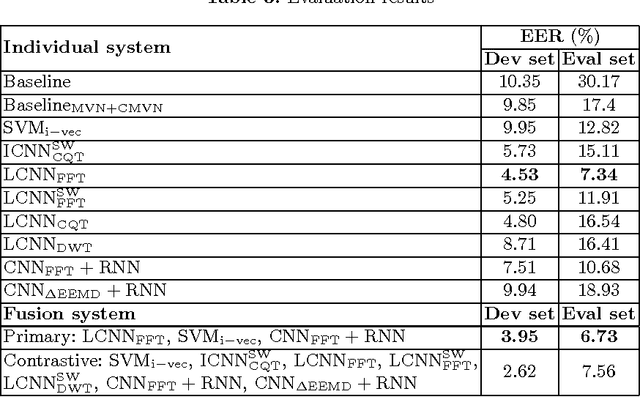
This paper presents the Speech Technology Center (STC) replay attack detection systems proposed for Automatic Speaker Verification Spoofing and Countermeasures Challenge 2017. In this study we focused on comparison of different spoofing detection approaches. These were GMM based methods, high level features extraction with simple classifier and deep learning frameworks. Experiments performed on the development and evaluation parts of the challenge dataset demonstrated stable efficiency of deep learning approaches in case of changing acoustic conditions. At the same time SVM classifier with high level features provided a substantial input in the efficiency of the resulting STC systems according to the fusion systems results.