 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context for Convolutional Pose Machines
Jun 10, 2019
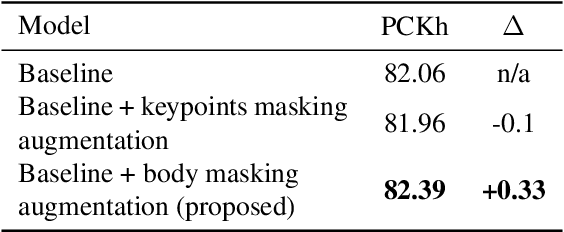

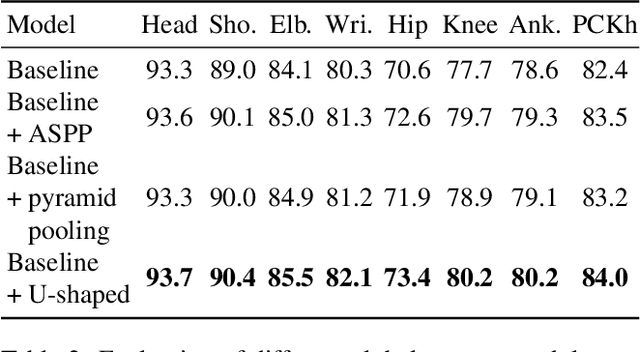
Convolutional Pose Machine is a popular neural network architecture for articulated pose estimation. In this work we explore its empirical receptive field and realize, that it can be enhanced with integration of a global context. To do so U-shaped context module is proposed and compared with the pyramid pooling and atrous spatial pyramid pooling modules, which are often used in semantic segmentation domain. The proposed neural network achieves state-of-the-art accuracy with 87.9% PCKh for single-person pose estimation on the Look Into Person dataset. A smaller version of this network runs more than 160 frames per second while being just 2.9% less accurate. Generalization of the proposed approach is tested on the MPII benchmark and shown, that it faster than hourglass-based networks, while provides similar accuracy. The code is available at https://github.com/opencv/openvino_training_extensions/tree/develop/pytorch_toolkit/human_pose_estimation .
Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose
Nov 29, 2018
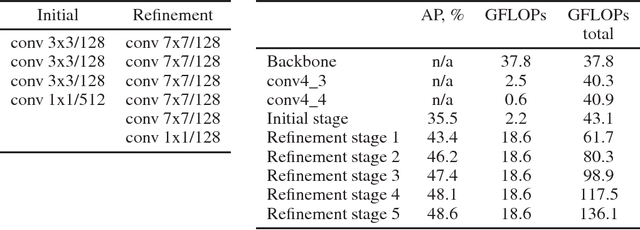


In this work we adapt multi-person pose estimation architecture to use it on edge devices. We follow the bottom-up approach from OpenPose, the winner of COCO 2016 Keypoints Challenge, because of its decent quality and robustness to number of people inside the frame. With proposed network design and optimized post-processing code the full solution runs at 28 frames per second (fps) on Intel$\unicode{xAE}$ NUC 6i7KYB mini PC and 26 fps on Core$^{TM}$ i7-6850K CPU. The network model has 4.1M parameters and 9 billions floating-point operations (GFLOPs) complexity, which is just ~15% of the baseline 2-stage OpenPose with almost the same quality. The code and model are available as a part of Intel$\unicode{xAE}$ OpenVINO$^{TM}$ Toolkit.
Development of Real-time ADAS Object Detector for Deployment on CPU
Nov 14, 2018
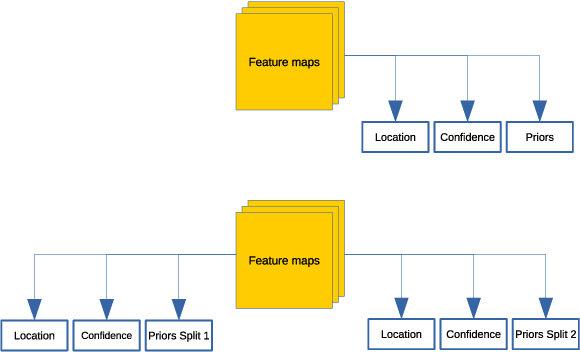


In this work, we outline the set of problems, which any Object Detection CNN faces when its development comes to the deployment stage and propose methods to deal with such difficulties. We show that these practices allow one to get Object Detection network, which can recognize two classes: vehicles and pedestrians and achieves more than 60 frames per second inference speed on Core$^{TM}$ i5-6500 CPU. The proposed model is built on top of the popular Single Shot MultiBox Object Detection framework but with substantial improvements, which were inspired by the discovered problems. The network has just 1.96 GMAC complexity and less than 7 MB model size. It is publicly available as a part of Intel$\circledR$ OpenVINO$^{TM}$ Toolkit.