 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Speculative Sampling and KV-Cache Optimizations Together for Generative AI using OpenVINO
Nov 08, 2023Inference optimizations are critical for improving user experience and reducing infrastructure costs and power consumption. In this article, we illustrate a form of dynamic execution known as speculative sampling to reduce the overall latency of text generation and compare it with standard autoregressive sampling. This can be used together with model-based optimizations (e.g. quantization) to provide an optimized solution. Both sampling methods make use of KV caching. A Jupyter notebook and some sample executions are provided.
Neural Network Compression Framework for fast model inference
Mar 12, 2020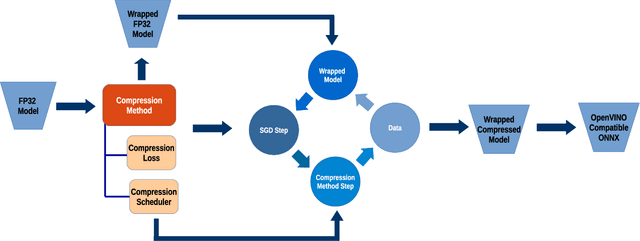
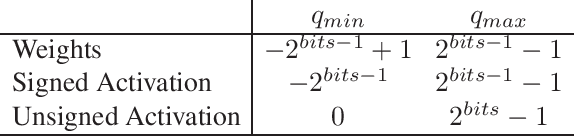

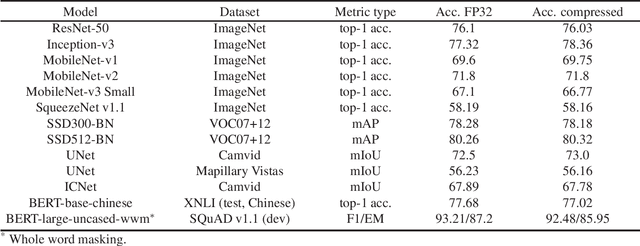
In this work we present a new framework for neural networks compression with fine-tuning, which we called Neural Network Compression Framework (NNCF). It leverages recent advances of various network compression methods and implements some of them, such as sparsity, quantization, and binarization. These methods allow getting more hardware-friendly models which can be efficiently run on general-purpose hardware computation units (CPU, GPU) or special Deep Learning accelerators. We show that the developed methods can be successfully applied to a wide range of models to accelerate the inference time while keeping the original accuracy. The framework can be used within the training samples, which are supplied with it, or as a standalone package that can be seamlessly integrated into the existing training code with minimal adaptations. Currently, a PyTorch version of NNCF is available as a part of OpenVINO Training Extensions at https://github.com/opencv/openvino_training_extensions/tree/develop/pytorch_toolkit/nncf