 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated AI Inference via Dynamic Execution Methods
Oct 30, 2024

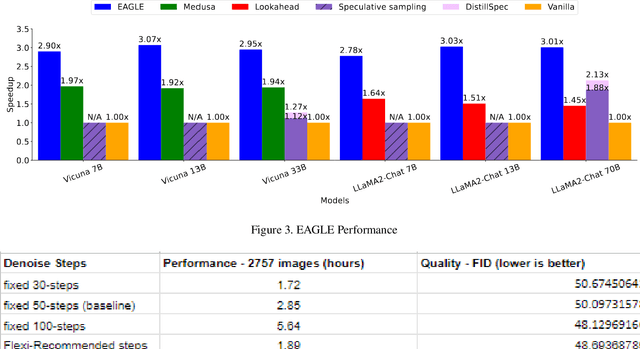
In this paper, we focus on Dynamic Execution techniques that optimize the computation flow based on input. This aims to identify simpler problems that can be solved using fewer resources, similar to human cognition. The techniques discussed include early exit from deep networks, speculative sampling for language models, and adaptive steps for diffusion models. Experimental results demonstrate that these dynamic approaches can significantly improve latency and throughput without compromising quality. When combined with model-based optimizations, such as quantization, dynamic execution provides a powerful multi-pronged strategy to optimize AI inference. Generative AI requires a large amount of compute resources. This is expected to grow, and demand for resources in data centers through to the edge is expected to continue to increase at high rates. We take advantage of existing research and provide additional innovations for some generative optimizations. In the case of LLMs, we provide more efficient sampling methods that depend on the complexity of the data. In the case of diffusion model generation, we provide a new method that also leverages the difficulty of the input prompt to predict an optimal early stopping point. Therefore, dynamic execution methods are relevant because they add another dimension of performance optimizations. Performance is critical from a competitive point of view, but increasing capacity can result in significant power savings and cost savings. We have provided several integrations of these techniques into several Intel performance libraries and Huggingface Optimum. These integrations will make them easier to use and increase the adoption of these techniques.
Step Saver: Predicting Minimum Denoising Steps for Diffusion Model Image Generation
Aug 04, 2024



In this paper, we introduce an innovative NLP model specifically fine-tuned to determine the minimal number of denoising steps required for any given text prompt. This advanced model serves as a real-time tool that recommends the ideal denoise steps for generating high-quality images efficiently. It is designed to work seamlessly with the Diffusion model, ensuring that images are produced with superior quality in the shortest possible time. Although our explanation focuses on the DDIM scheduler, the methodology is adaptable and can be applied to various other schedulers like Euler, Euler Ancestral, Heun, DPM2 Karras, UniPC, and more. This model allows our customers to conserve costly computing resources by executing the fewest necessary denoising steps to achieve optimal quality in the produced images.
Leveraging Speculative Sampling and KV-Cache Optimizations Together for Generative AI using OpenVINO
Nov 08, 2023Inference optimizations are critical for improving user experience and reducing infrastructure costs and power consumption. In this article, we illustrate a form of dynamic execution known as speculative sampling to reduce the overall latency of text generation and compare it with standard autoregressive sampling. This can be used together with model-based optimizations (e.g. quantization) to provide an optimized solution. Both sampling methods make use of KV caching. A Jupyter notebook and some sample executions are provided.
Mimic The Raw Domain: Accelerating Action Recognition in the Compressed Domain
Nov 20, 2019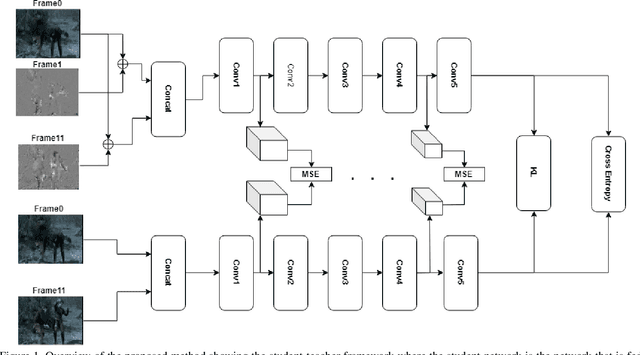
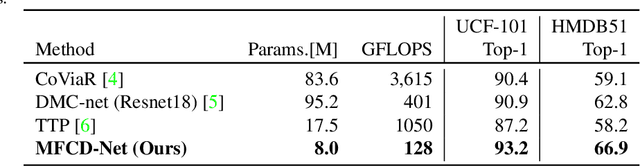


Video understanding usually requires expensive computation that prohibits its deployment, yet videos contain significant spatiotemporal redundancy that can be exploited. In particular, operating directly on the motion vectors and residuals in the compressed video domain can significantly accelerate the compute, by not using the raw videos which demand colossal storage capacity. Existing methods approach this task as a multiple modalities problem. In this paper we are approaching the task in a completely different way; we are looking at the data from the compressed stream as a one unit clip and propose that the residual frames can replace the original RGB frames from the raw domain. Furthermore, we are using teacher-student method to aid the network in the compressed domain to mimic the teacher network in the raw domain. We show experiments on three leading datasets (HMDB51, UCF1, and Kinetics) that approach state-of-the-art accuracy on raw video data by using compressed data. Our model MFCD-Net outperforms prior methods in the compressed domain and more importantly, our model has 11X fewer parameters and 3X fewer Flops, dramatically improving the efficiency of video recognition inference. This approach enables applying neural networks exclusively in the compressed domain without compromising accuracy while accelerating performance.