 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated AI Inference via Dynamic Execution Methods
Paper and Code
Oct 30, 2024

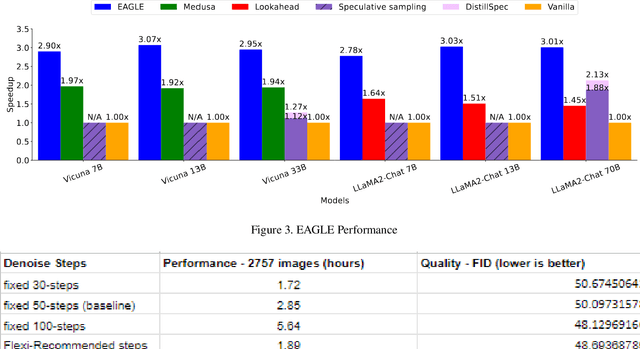
In this paper, we focus on Dynamic Execution techniques that optimize the computation flow based on input. This aims to identify simpler problems that can be solved using fewer resources, similar to human cognition. The techniques discussed include early exit from deep networks, speculative sampling for language models, and adaptive steps for diffusion models. Experimental results demonstrate that these dynamic approaches can significantly improve latency and throughput without compromising quality. When combined with model-based optimizations, such as quantization, dynamic execution provides a powerful multi-pronged strategy to optimize AI inference. Generative AI requires a large amount of compute resources. This is expected to grow, and demand for resources in data centers through to the edge is expected to continue to increase at high rates. We take advantage of existing research and provide additional innovations for some generative optimizations. In the case of LLMs, we provide more efficient sampling methods that depend on the complexity of the data. In the case of diffusion model generation, we provide a new method that also leverages the difficulty of the input prompt to predict an optimal early stopping point. Therefore, dynamic execution methods are relevant because they add another dimension of performance optimizations. Performance is critical from a competitive point of view, but increasing capacity can result in significant power savings and cost savings. We have provided several integrations of these techniques into several Intel performance libraries and Huggingface Optimum. These integrations will make them easier to use and increase the adoption of these techniques.