 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Editing in Language Models via Adapted Direct Preference Optimization
Jun 14, 2024Large Language Models (LLMs) can become outdated over time as they may lack updated world knowledge, leading to factual knowledge errors and gaps. Knowledge Editing (KE) aims to overcome this challenge using weight updates that do not require expensive retraining. We propose treating KE as an LLM alignment problem. Toward this goal, we introduce Knowledge Direct Preference Optimization (KDPO), a variation of the Direct Preference Optimization (DPO) that is more effective for knowledge modifications. Our method is based on an online approach that continually updates the knowledge stored in the model. We use the current knowledge as a negative sample and the new knowledge we want to introduce as a positive sample in a process called DPO. We also use teacher-forcing for negative sample generation and optimize using the positive sample, which helps maintain localized changes. We tested our KE method on various datasets and models, comparing it to several cutting-edge methods, with 100 and 500 sequential edits. Additionally, we conducted an ablation study comparing our method to the standard DPO approach. Our experimental results show that our modified DPO method allows for more refined KE, achieving similar or better performance compared to previous methods.
Obtaining Favorable Layouts for Multiple Object Generation
May 01, 2024



Large-scale text-to-image models that can generate high-quality and diverse images based on textual prompts have shown remarkable success. These models aim ultimately to create complex scenes, and addressing the challenge of multi-subject generation is a critical step towards this goal. However, the existing state-of-the-art diffusion models face difficulty when generating images that involve multiple subjects. When presented with a prompt containing more than one subject, these models may omit some subjects or merge them together. To address this challenge, we propose a novel approach based on a guiding principle. We allow the diffusion model to initially propose a layout, and then we rearrange the layout grid. This is achieved by enforcing cross-attention maps (XAMs) to adhere to proposed masks and by migrating pixels from latent maps to new locations determined by us. We introduce new loss terms aimed at reducing XAM entropy for clearer spatial definition of subjects, reduce the overlap between XAMs, and ensure that XAMs align with their respective masks. We contrast our approach with several alternative methods and show that it more faithfully captures the desired concepts across a variety of text prompts.
Efficient Verification-Based Face Identification
Dec 20, 2023



We study the problem of performing face verification with an efficient neural model $f$. The efficiency of $f$ stems from simplifying the face verification problem from an embedding nearest neighbor search into a binary problem; each user has its own neural network $f$. To allow information sharing between different individuals in the training set, we do not train $f$ directly but instead generate the model weights using a hypernetwork $h$. This leads to the generation of a compact personalized model for face identification that can be deployed on edge devices. Key to the method's success is a novel way of generating hard negatives and carefully scheduling the training objectives. Our model leads to a substantially small $f$ requiring only 23k parameters and 5M floating point operations (FLOPS). We use six face verification datasets to demonstrate that our method is on par or better than state-of-the-art models, with a significantly reduced number of parameters and computational burden. Furthermore, we perform an extensive ablation study to demonstrate the importance of each element in our method.
Anomaly Detection with Variance Stabilized Density Estimation
Jun 01, 2023Density estimation based anomaly detection schemes typically model anomalies as examples that reside in low-density regions. We propose a modified density estimation problem and demonstrate its effectiveness for anomaly detection. Specifically, we assume the density function of normal samples is uniform in some compact domain. This assumption implies the density function is more stable (with lower variance) around normal samples than anomalies. We first corroborate this assumption empirically using a wide range of real-world data. Then, we design a variance stabilized density estimation problem for maximizing the likelihood of the observed samples while minimizing the variance of the density around normal samples. We introduce an ensemble of autoregressive models to learn the variance stabilized distribution. Finally, we perform an extensive benchmark with 52 datasets demonstrating that our method leads to state-of-the-art results while alleviating the need for data-specific hyperparameter tuning.
Revisiting the Noise Model of Stochastic Gradient Descent
Mar 05, 2023The stochastic gradient noise (SGN) is a significant factor in the success of stochastic gradient descent (SGD). Following the central limit theorem, SGN was initially modeled as Gaussian, and lately, it has been suggested that stochastic gradient noise is better characterized using $S\alpha S$ L\'evy distribution. This claim was allegedly refuted and rebounded to the previously suggested Gaussian noise model. This paper presents solid, detailed empirical evidence that SGN is heavy-tailed and better depicted by the $S\alpha S$ distribution. Furthermore, we argue that different parameters in a deep neural network (DNN) hold distinct SGN characteristics throughout training. To more accurately approximate the dynamics of SGD near a local minimum, we construct a novel framework in $\mathbb{R}^N$, based on L\'evy-driven stochastic differential equation (SDE), where one-dimensional L\'evy processes model each parameter in the DNN. Next, we show that SGN jump intensity (frequency and amplitude) depends on the learning rate decay mechanism (LRdecay); furthermore, we demonstrate empirically that the LRdecay effect may stem from the reduction of the SGN and not the decrease in the step size. Based on our analysis, we examine the mean escape time, trapping probability, and more properties of DNNs near local minima. Finally, we prove that the training process will likely exit from the basin in the direction of parameters with heavier tail SGN. We will share our code for reproducibility.
Domain-Generalizable Multiple-Domain Clustering
Jan 31, 2023



Accurately clustering high-dimensional measurements is vital for adequately analyzing scientific data. Deep learning machinery has remarkably improved clustering capabilities in recent years due to its ability to extract meaningful representations. In this work, we are given unlabeled samples from multiple source domains, and we aim to learn a shared classifier that assigns the examples to various clusters. Evaluation is done by using the classifier for predicting cluster assignments in a previously unseen domain. This setting generalizes the problem of unsupervised domain generalization to the case in which no supervised learning samples are given (completely unsupervised). Towards this goal, we present an end-to-end model and evaluate its capabilities on several multi-domain image datasets. Specifically, we demonstrate that our model is more accurate than schemes that require fine-tuning using samples from the target domain or some level of supervision.
Mixing between the Cross Entropy and the Expectation Loss Terms
Sep 12, 2021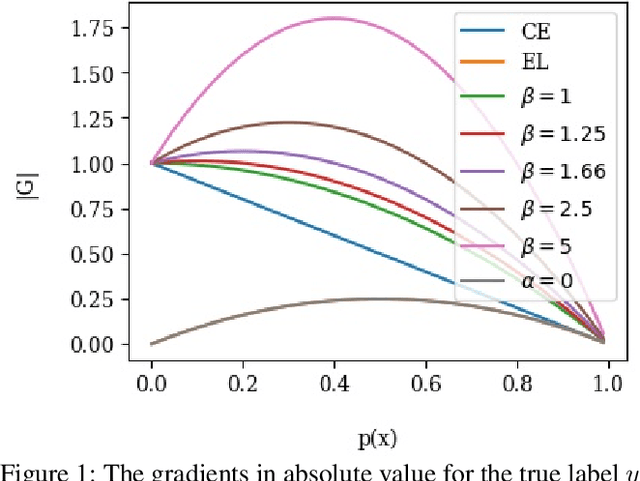
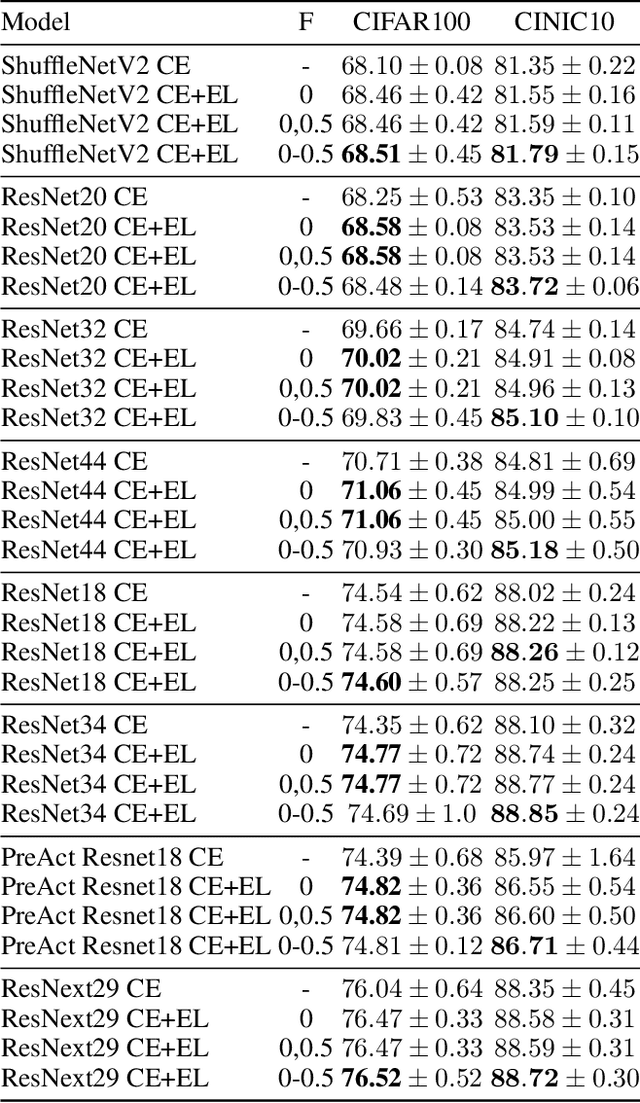
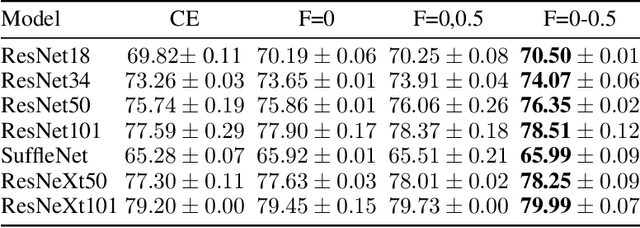
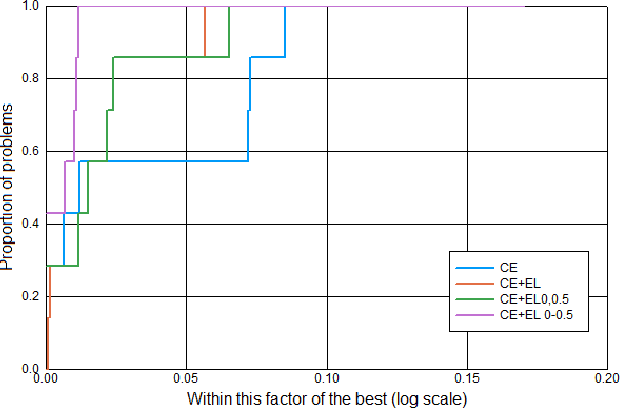
The cross entropy loss is widely used due to its effectiveness and solid theoretical grounding. However, as training progresses, the loss tends to focus on hard to classify samples, which may prevent the network from obtaining gains in performance. While most work in the field suggest ways to classify hard negatives, we suggest to strategically leave hard negatives behind, in order to focus on misclassified samples with higher probabilities. We show that adding to the optimization goal the expectation loss, which is a better approximation of the zero-one loss, helps the network to achieve better accuracy. We, therefore, propose to shift between the two losses during training, focusing more on the expectation loss gradually during the later stages of training. Our experiments show that the new training protocol improves performance across a diverse set of classification domains, including computer vision, natural language processing, tabular data, and sequences. Our code and scripts are available at supplementary.
Mimic The Raw Domain: Accelerating Action Recognition in the Compressed Domain
Nov 20, 2019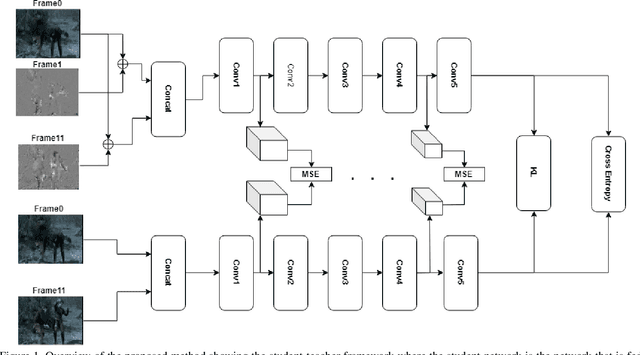
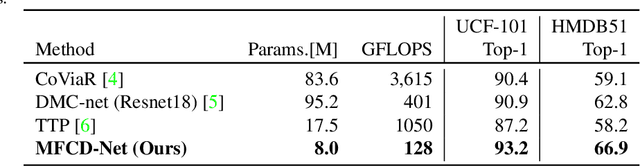


Video understanding usually requires expensive computation that prohibits its deployment, yet videos contain significant spatiotemporal redundancy that can be exploited. In particular, operating directly on the motion vectors and residuals in the compressed video domain can significantly accelerate the compute, by not using the raw videos which demand colossal storage capacity. Existing methods approach this task as a multiple modalities problem. In this paper we are approaching the task in a completely different way; we are looking at the data from the compressed stream as a one unit clip and propose that the residual frames can replace the original RGB frames from the raw domain. Furthermore, we are using teacher-student method to aid the network in the compressed domain to mimic the teacher network in the raw domain. We show experiments on three leading datasets (HMDB51, UCF1, and Kinetics) that approach state-of-the-art accuracy on raw video data by using compressed data. Our model MFCD-Net outperforms prior methods in the compressed domain and more importantly, our model has 11X fewer parameters and 3X fewer Flops, dramatically improving the efficiency of video recognition inference. This approach enables applying neural networks exclusively in the compressed domain without compromising accuracy while accelerating performance.
Adaptive and Iteratively Improving Recurrent Lateral Connections
Oct 16, 2019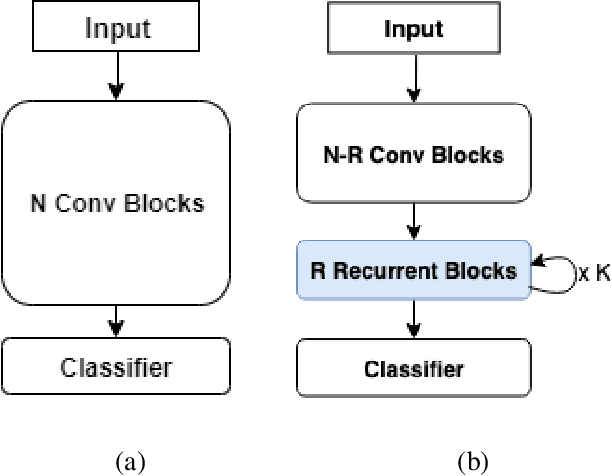

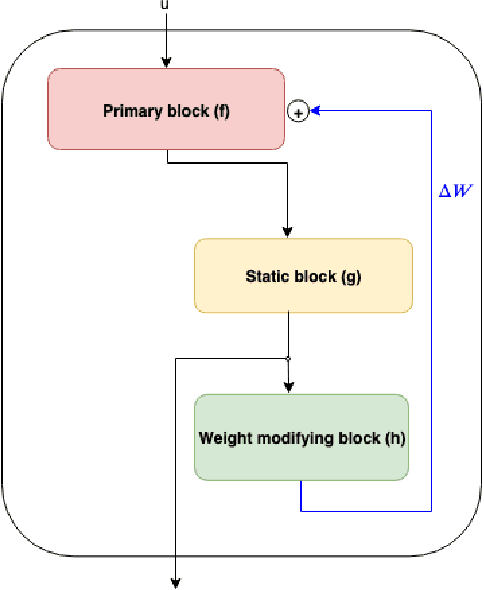
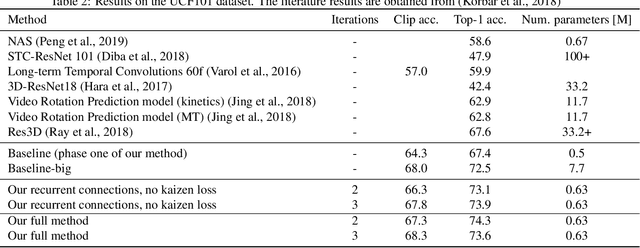
The current leading computer vision models are typically feed forward neural models, in which the output of one computational block is passed to the next one sequentially. This is in sharp contrast to the organization of the primate visual cortex, in which feedback and lateral connections are abundant. In this work, we propose a computational model for the role of lateral connections in a given block, in which the weights of the block vary dynamically as a function of its activations, and the input from the upstream blocks is iteratively reintroduced. We demonstrate how this novel architectural modification can lead to sizable gains in performance, when applied to visual action recognition without pretraining and that it outperforms the literature architectures with recurrent feedback processing on ImageNet.