 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive and Iteratively Improving Recurrent Lateral Connections
Paper and Code
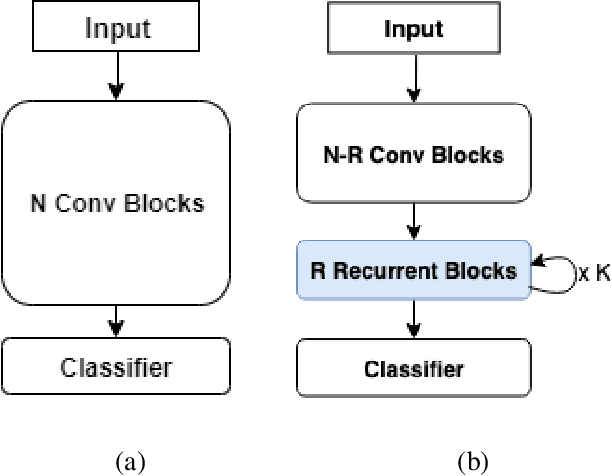

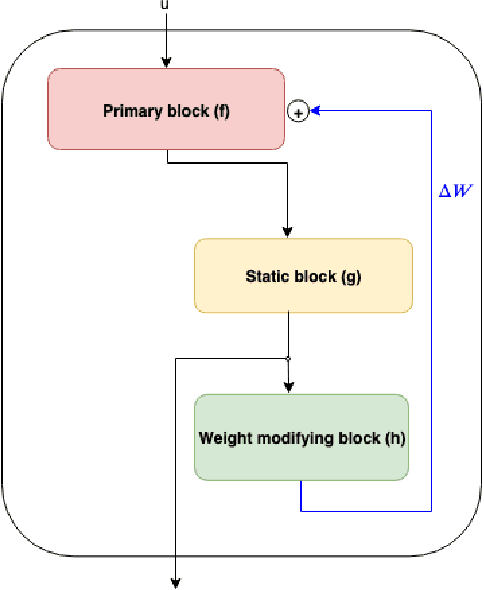
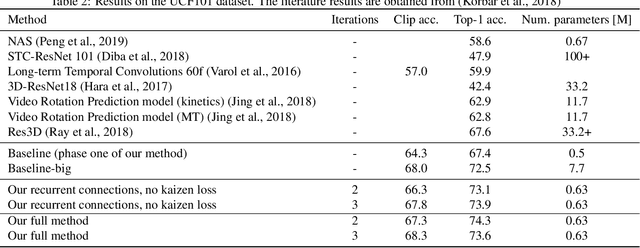
The current leading computer vision models are typically feed forward neural models, in which the output of one computational block is passed to the next one sequentially. This is in sharp contrast to the organization of the primate visual cortex, in which feedback and lateral connections are abundant. In this work, we propose a computational model for the role of lateral connections in a given block, in which the weights of the block vary dynamically as a function of its activations, and the input from the upstream blocks is iteratively reintroduced. We demonstrate how this novel architectural modification can lead to sizable gains in performance, when applied to visual action recognition without pretraining and that it outperforms the literature architectures with recurrent feedback processing on ImageNet.