 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing between the Cross Entropy and the Expectation Loss Terms
Paper and Code
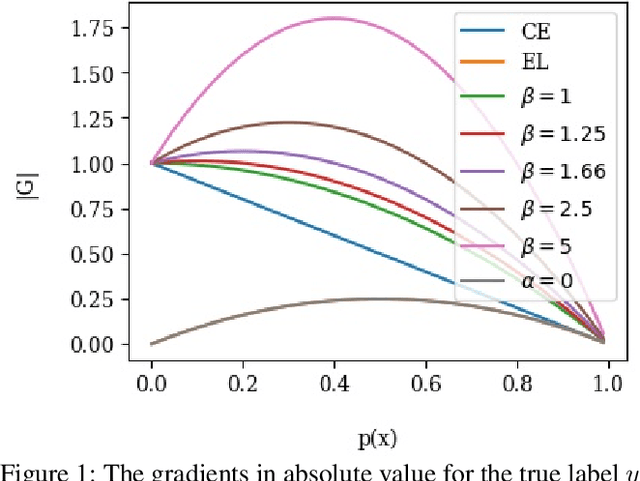
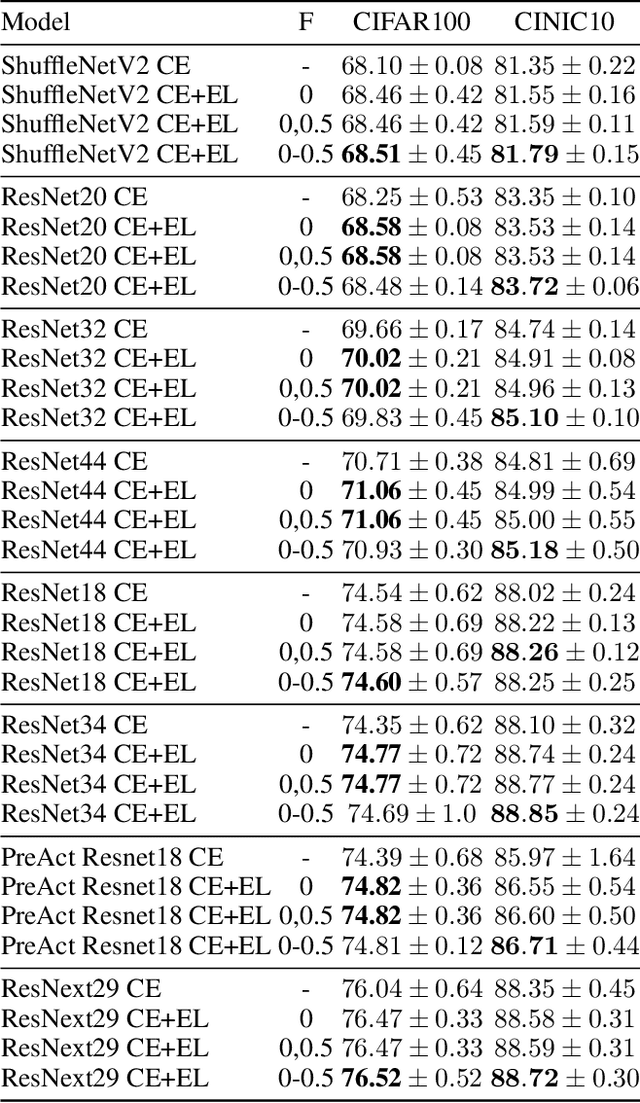
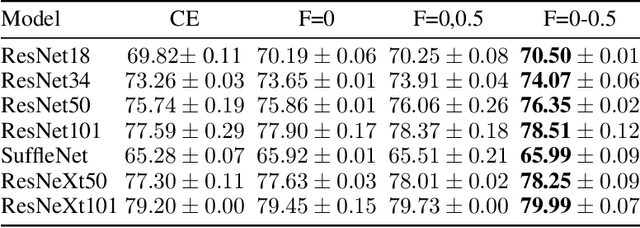
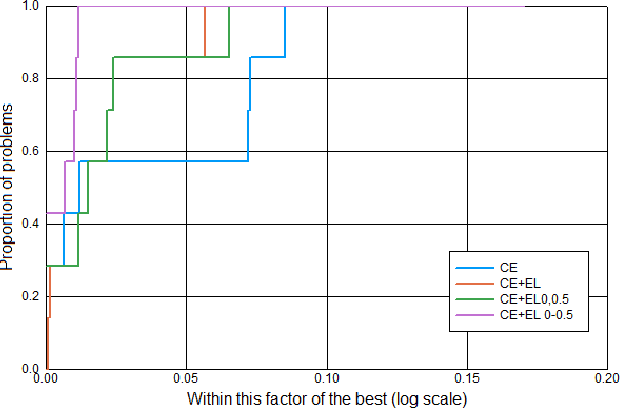
The cross entropy loss is widely used due to its effectiveness and solid theoretical grounding. However, as training progresses, the loss tends to focus on hard to classify samples, which may prevent the network from obtaining gains in performance. While most work in the field suggest ways to classify hard negatives, we suggest to strategically leave hard negatives behind, in order to focus on misclassified samples with higher probabilities. We show that adding to the optimization goal the expectation loss, which is a better approximation of the zero-one loss, helps the network to achieve better accuracy. We, therefore, propose to shift between the two losses during training, focusing more on the expectation loss gradually during the later stages of training. Our experiments show that the new training protocol improves performance across a diverse set of classification domains, including computer vision, natural language processing, tabular data, and sequences. Our code and scripts are available at supplementary.