 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNICON: A unified framework for behavior-based consumer segmentation in e-commerce
Sep 18, 2023



Data-driven personalization is a key practice in fashion e-commerce, improving the way businesses serve their consumers needs with more relevant content. While hyper-personalization offers highly targeted experiences to each consumer, it requires a significant amount of private data to create an individualized journey. To alleviate this, group-based personalization provides a moderate level of personalization built on broader common preferences of a consumer segment, while still being able to personalize the results. We introduce UNICON, a unified deep learning consumer segmentation framework that leverages rich consumer behavior data to learn long-term latent representations and utilizes them to extract two pivotal types of segmentation catering various personalization use-cases: lookalike, expanding a predefined target seed segment with consumers of similar behavior, and data-driven, revealing non-obvious consumer segments with similar affinities. We demonstrate through extensive experimentation our framework effectiveness in fashion to identify lookalike Designer audience and data-driven style segments. Furthermore, we present experiments that showcase how segment information can be incorporated in a hybrid recommender system combining hyper and group-based personalization to exploit the advantages of both alternatives and provide improvements on consumer experience.
On Residual CNN in text-dependent speaker verification task
May 30, 2017
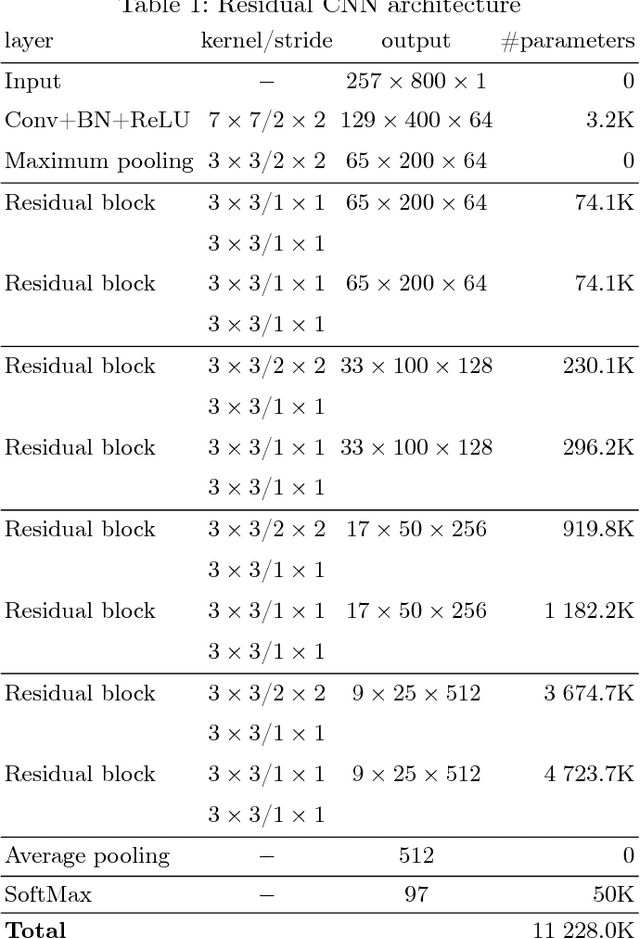

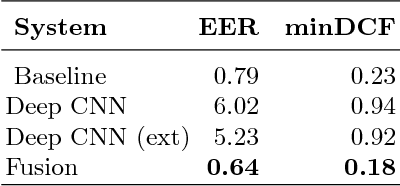
Deep learning approaches are still not very common in the speaker verification field. We investigate the possibility of using deep residual convolutional neural network with spectrograms as an input features in the text-dependent speaker verification task. Despite the fact that we were not able to surpass the baseline system in quality, we achieved a quite good results for such a new approach getting an 5.23% ERR on the RSR2015 evaluation part. Fusion of the baseline and proposed systems outperformed the best individual system by 18% relatively.
Audio-replay attack detection countermeasures
May 24, 2017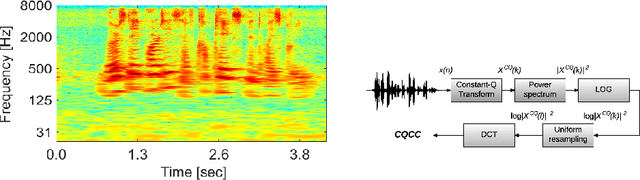


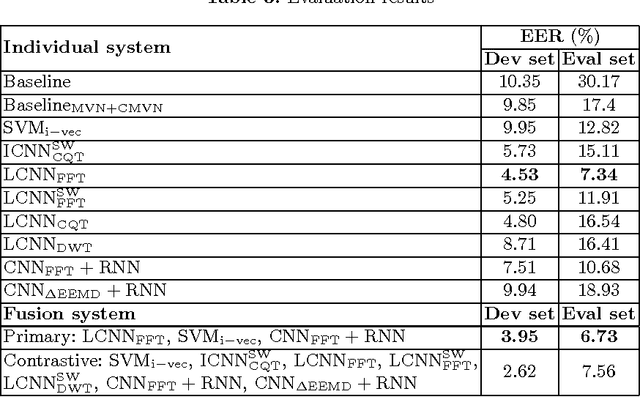
This paper presents the Speech Technology Center (STC) replay attack detection systems proposed for Automatic Speaker Verification Spoofing and Countermeasures Challenge 2017. In this study we focused on comparison of different spoofing detection approaches. These were GMM based methods, high level features extraction with simple classifier and deep learning frameworks. Experiments performed on the development and evaluation parts of the challenge dataset demonstrated stable efficiency of deep learning approaches in case of changing acoustic conditions. At the same time SVM classifier with high level features provided a substantial input in the efficiency of the resulting STC systems according to the fusion systems results.