 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompactFlowNet: Efficient Real-time Optical Flow Estimation on Mobile Devices
Dec 17, 2024



We present CompactFlowNet, the first real-time mobile neural network for optical flow prediction, which involves determining the displacement of each pixel in an initial frame relative to the corresponding pixel in a subsequent frame. Optical flow serves as a fundamental building block for various video-related tasks, such as video restoration, motion estimation, video stabilization, object tracking, action recognition, and video generation. While current state-of-the-art methods prioritize accuracy, they often overlook constraints regarding speed and memory usage. Existing light models typically focus on reducing size but still exhibit high latency, compromise significantly on quality, or are optimized for high-performance GPUs, resulting in sub-optimal performance on mobile devices. This study aims to develop a mobile-optimized optical flow model by proposing a novel mobile device-compatible architecture, as well as enhancements to the training pipeline, which optimize the model for reduced weight, low memory utilization, and increased speed while maintaining minimal error. Our approach demonstrates superior or comparable performance to the state-of-the-art lightweight models on the challenging KITTI and Sintel benchmarks. Furthermore, it attains a significantly accelerated inference speed, thereby yielding real-time operational efficiency on the iPhone 8, while surpassing real-time performance levels on more advanced mobile devices.
Deep CNN based feature extractor for text-prompted speaker recognition
Mar 13, 2018
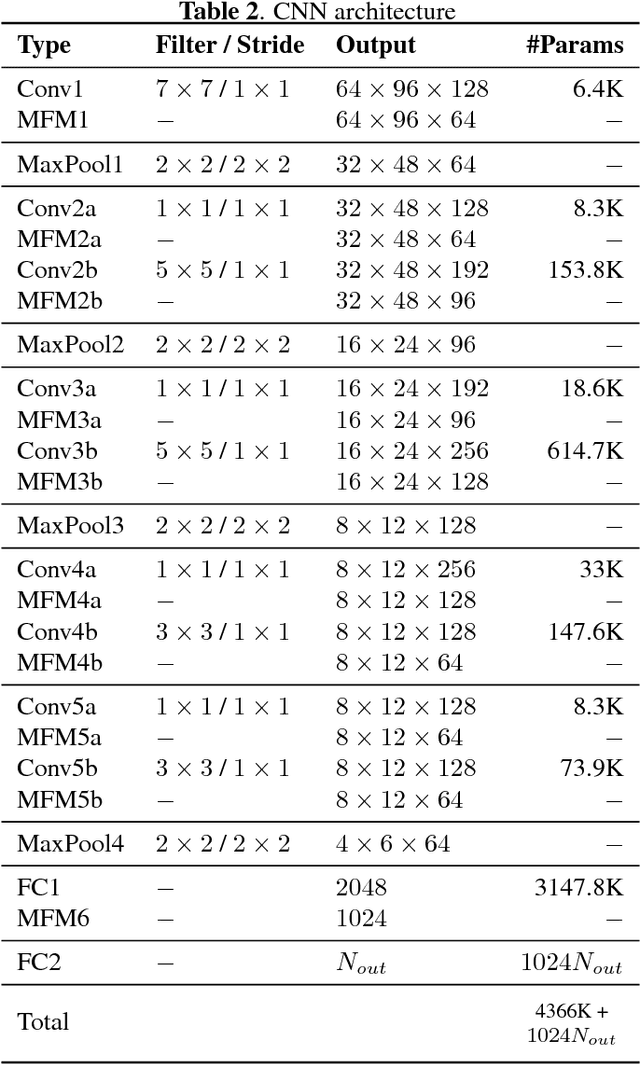
Deep learning is still not a very common tool in speaker verification field. We study deep convolutional neural network performance in the text-prompted speaker verification task. The prompted passphrase is segmented into word states - i.e. digits -to test each digit utterance separately. We train a single high-level feature extractor for all states and use cosine similarity metric for scoring. The key feature of our network is the Max-Feature-Map activation function, which acts as an embedded feature selector. By using multitask learning scheme to train the high-level feature extractor we were able to surpass the classic baseline systems in terms of quality and achieved impressive results for such a novice approach, getting 2.85% EER on the RSR2015 evaluation set. Fusion of the proposed and the baseline systems improves this result.
On Residual CNN in text-dependent speaker verification task
May 30, 2017
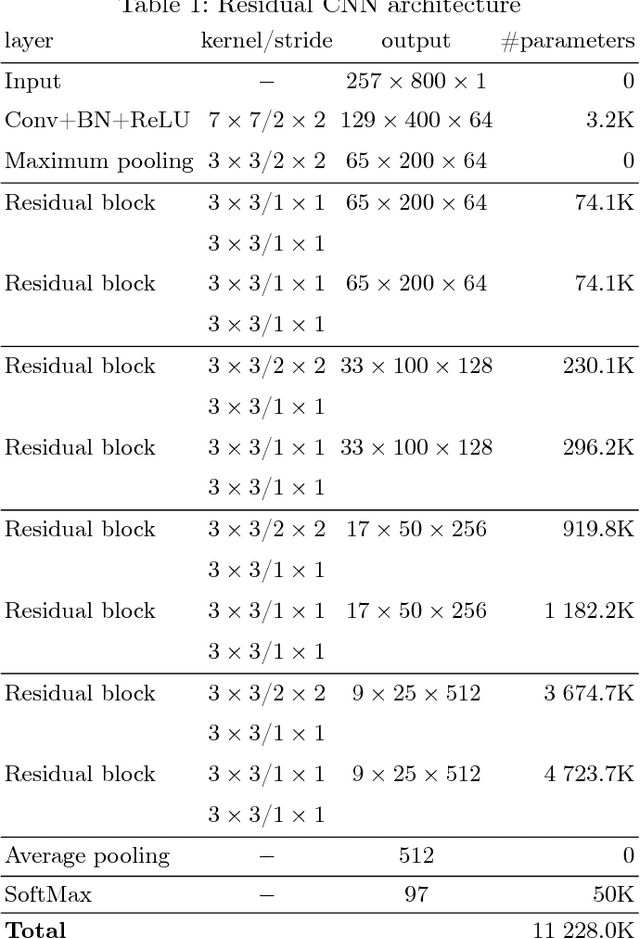

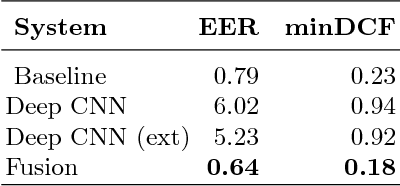
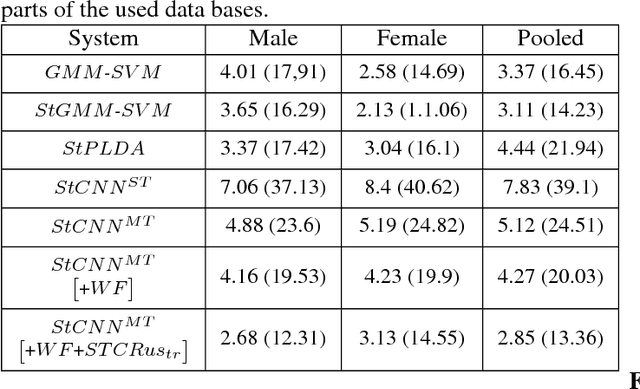
Deep learning approaches are still not very common in the speaker verification field. We investigate the possibility of using deep residual convolutional neural network with spectrograms as an input features in the text-dependent speaker verification task. Despite the fact that we were not able to surpass the baseline system in quality, we achieved a quite good results for such a new approach getting an 5.23% ERR on the RSR2015 evaluation part. Fusion of the baseline and proposed systems outperformed the best individual system by 18% relatively.
Audio-replay attack detection countermeasures
May 24, 2017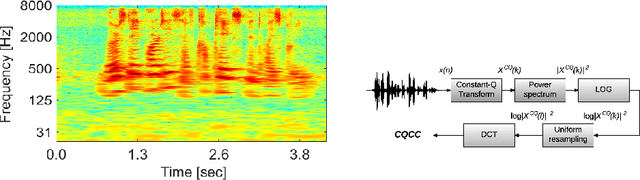


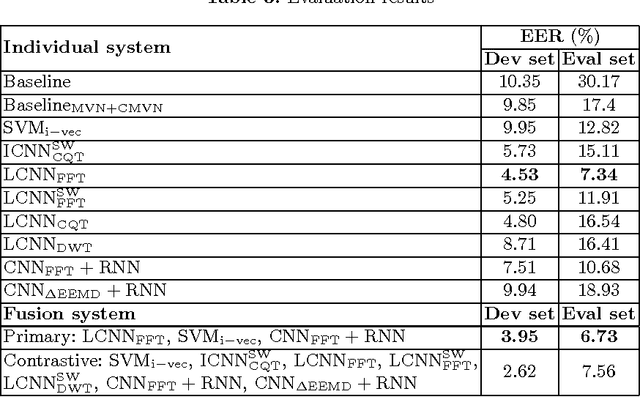
This paper presents the Speech Technology Center (STC) replay attack detection systems proposed for Automatic Speaker Verification Spoofing and Countermeasures Challenge 2017. In this study we focused on comparison of different spoofing detection approaches. These were GMM based methods, high level features extraction with simple classifier and deep learning frameworks. Experiments performed on the development and evaluation parts of the challenge dataset demonstrated stable efficiency of deep learning approaches in case of changing acoustic conditions. At the same time SVM classifier with high level features provided a substantial input in the efficiency of the resulting STC systems according to the fusion systems results.