 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Normalizing Flows
Jun 26, 2025Explicit density learners are becoming an increasingly popular technique for generative models because of their ability to better model probability distributions. They have advantages over Generative Adversarial Networks due to their ability to perform density estimation and having exact latent-variable inference. This has many advantages, including: being able to simply interpolate, calculate sample likelihood, and analyze the probability distribution. The downside of these models is that they are often more difficult to train and have lower sampling quality. Normalizing flows are explicit density models, that use composable bijective functions to turn an intractable probability function into a tractable one. In this work, we present novel knowledge distillation techniques to increase sampling quality and density estimation of smaller student normalizing flows. We seek to study the capacity of knowledge distillation in Compositional Normalizing Flows to understand the benefits and weaknesses provided by these architectures. Normalizing flows have unique properties that allow for a non-traditional forms of knowledge transfer, where we can transfer that knowledge within intermediate layers. We find that through this distillation, we can make students significantly smaller while making substantial performance gains over a non-distilled student. With smaller models there is a proportionally increased throughput as this is dependent upon the number of bijectors, and thus parameters, in the network.
CompactFlowNet: Efficient Real-time Optical Flow Estimation on Mobile Devices
Dec 17, 2024



We present CompactFlowNet, the first real-time mobile neural network for optical flow prediction, which involves determining the displacement of each pixel in an initial frame relative to the corresponding pixel in a subsequent frame. Optical flow serves as a fundamental building block for various video-related tasks, such as video restoration, motion estimation, video stabilization, object tracking, action recognition, and video generation. While current state-of-the-art methods prioritize accuracy, they often overlook constraints regarding speed and memory usage. Existing light models typically focus on reducing size but still exhibit high latency, compromise significantly on quality, or are optimized for high-performance GPUs, resulting in sub-optimal performance on mobile devices. This study aims to develop a mobile-optimized optical flow model by proposing a novel mobile device-compatible architecture, as well as enhancements to the training pipeline, which optimize the model for reduced weight, low memory utilization, and increased speed while maintaining minimal error. Our approach demonstrates superior or comparable performance to the state-of-the-art lightweight models on the challenging KITTI and Sintel benchmarks. Furthermore, it attains a significantly accelerated inference speed, thereby yielding real-time operational efficiency on the iPhone 8, while surpassing real-time performance levels on more advanced mobile devices.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
OneFormer: One Transformer to Rule Universal Image Segmentation
Nov 10, 2022



Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible. To support further research, we open-source our code and models at https://github.com/SHI-Labs/OneFormer
AdaFocusV3: On Unified Spatial-temporal Dynamic Video Recognition
Sep 27, 2022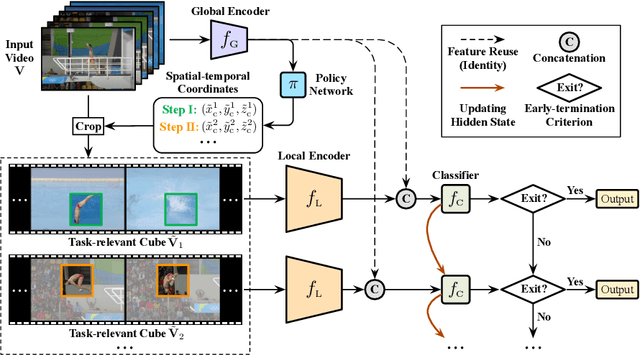
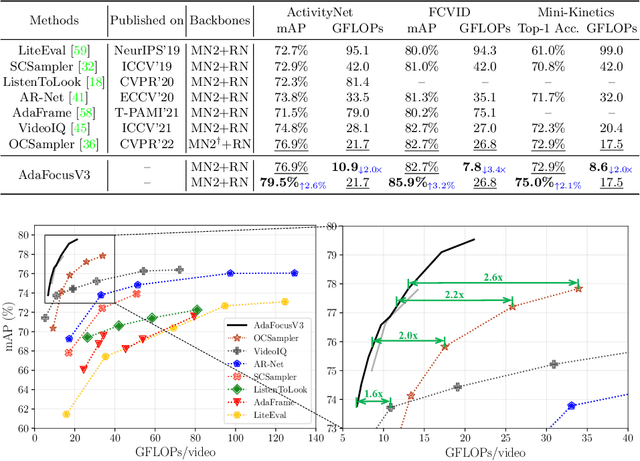
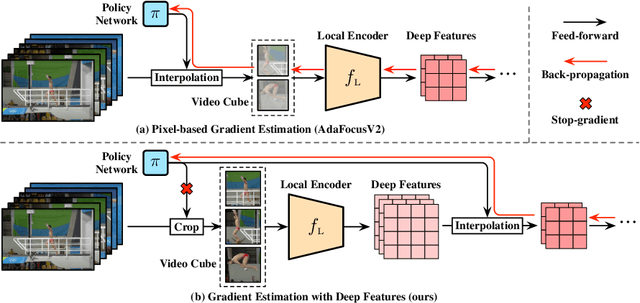
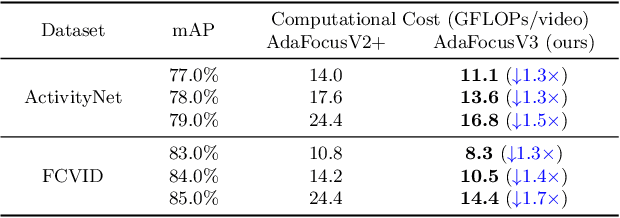
Recent research has revealed that reducing the temporal and spatial redundancy are both effective approaches towards efficient video recognition, e.g., allocating the majority of computation to a task-relevant subset of frames or the most valuable image regions of each frame. However, in most existing works, either type of redundancy is typically modeled with another absent. This paper explores the unified formulation of spatial-temporal dynamic computation on top of the recently proposed AdaFocusV2 algorithm, contributing to an improved AdaFocusV3 framework. Our method reduces the computational cost by activating the expensive high-capacity network only on some small but informative 3D video cubes. These cubes are cropped from the space formed by frame height, width, and video duration, while their locations are adaptively determined with a light-weighted policy network on a per-sample basis. At test time, the number of the cubes corresponding to each video is dynamically configured, i.e., video cubes are processed sequentially until a sufficiently reliable prediction is produced. Notably, AdaFocusV3 can be effectively trained by approximating the non-differentiable cropping operation with the interpolation of deep features. Extensive empirical results on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2 and Diving48) demonstrate that our model is considerably more efficient than competitive baselines.
Towards Layer-wise Image Vectorization
Jun 09, 2022



Image rasterization is a mature technique in computer graphics, while image vectorization, the reverse path of rasterization, remains a major challenge. Recent advanced deep learning-based models achieve vectorization and semantic interpolation of vector graphs and demonstrate a better topology of generating new figures. However, deep models cannot be easily generalized to out-of-domain testing data. The generated SVGs also contain complex and redundant shapes that are not quite convenient for further editing. Specifically, the crucial layer-wise topology and fundamental semantics in images are still not well understood and thus not fully explored. In this work, we propose Layer-wise Image Vectorization, namely LIVE, to convert raster images to SVGs and simultaneously maintain its image topology. LIVE can generate compact SVG forms with layer-wise structures that are semantically consistent with human perspective. We progressively add new bezier paths and optimize these paths with the layer-wise framework, newly designed loss functions, and component-wise path initialization technique. Our experiments demonstrate that LIVE presents more plausible vectorized forms than prior works and can be generalized to new images. With the help of this newly learned topology, LIVE initiates human editable SVGs for both designers and other downstream applications. Codes are made available at https://github.com/Picsart-AI-Research/LIVE-Layerwise-Image-Vectorization.
AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
Dec 28, 2021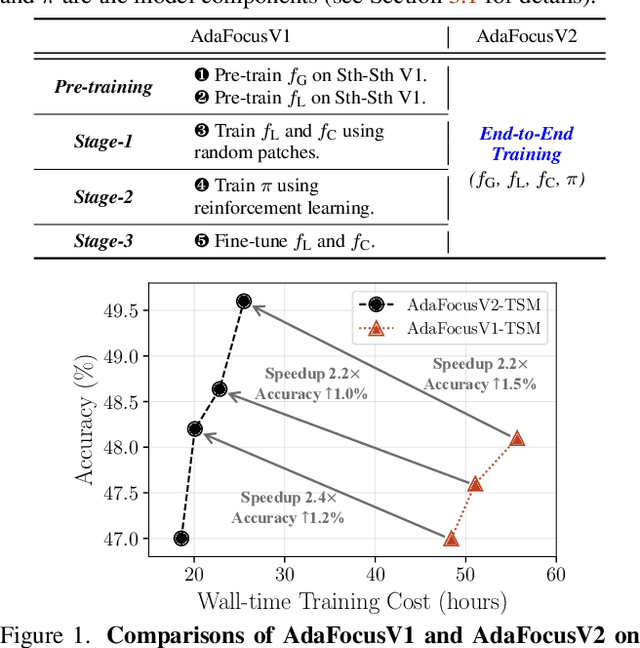
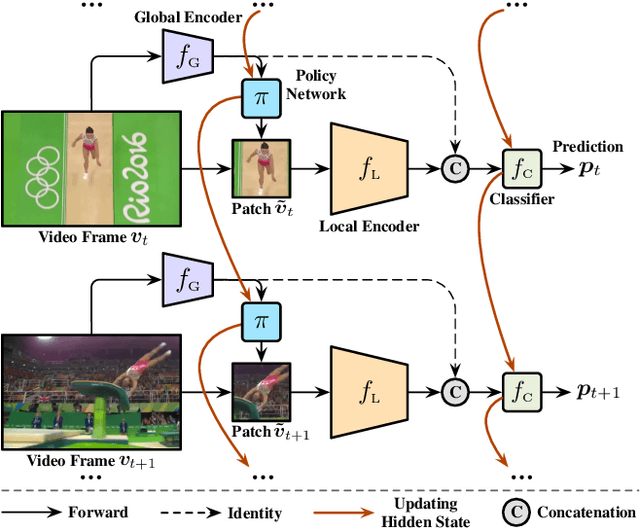

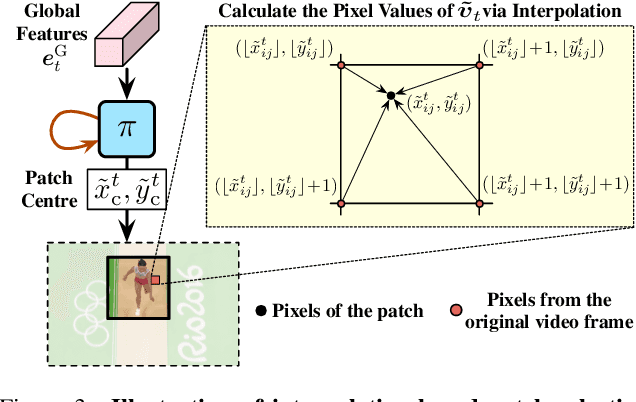
Recent works have shown that the computational efficiency of video recognition can be significantly improved by reducing the spatial redundancy. As a representative work, the adaptive focus method (AdaFocus) has achieved a favorable trade-off between accuracy and inference speed by dynamically identifying and attending to the informative regions in each video frame. However, AdaFocus requires a complicated three-stage training pipeline (involving reinforcement learning), leading to slow convergence and is unfriendly to practitioners. This work reformulates the training of AdaFocus as a simple one-stage algorithm by introducing a differentiable interpolation-based patch selection operation, enabling efficient end-to-end optimization. We further present an improved training scheme to address the issues introduced by the one-stage formulation, including the lack of supervision, input diversity and training stability. Moreover, a conditional-exit technique is proposed to perform temporal adaptive computation on top of AdaFocus without additional training. Extensive experiments on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, and Jester) demonstrate that our model significantly outperforms the original AdaFocus and other competitive baselines, while being considerably more simple and efficient to train. Code is available at https://github.com/LeapLabTHU/AdaFocusV2.
SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 23, 2021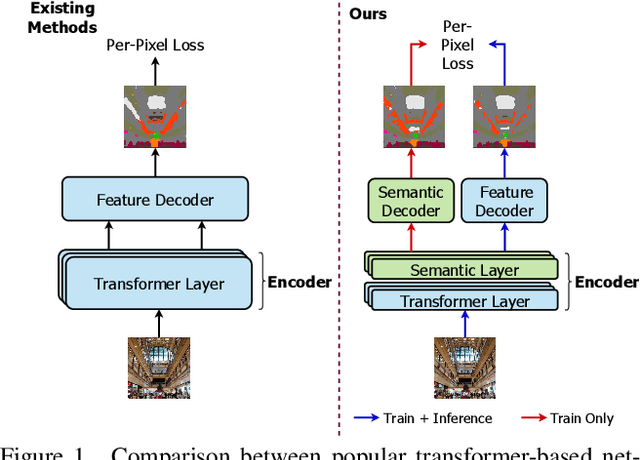
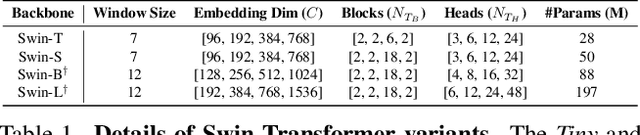
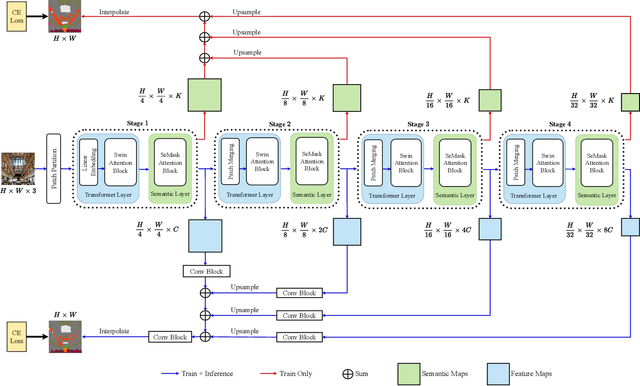
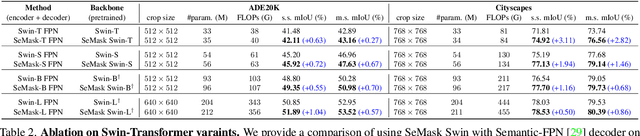
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at https://github.com/Picsart-AI-Research/SeMask-Segmentation .
Fast Glare Detection in Document Images
Oct 24, 2019
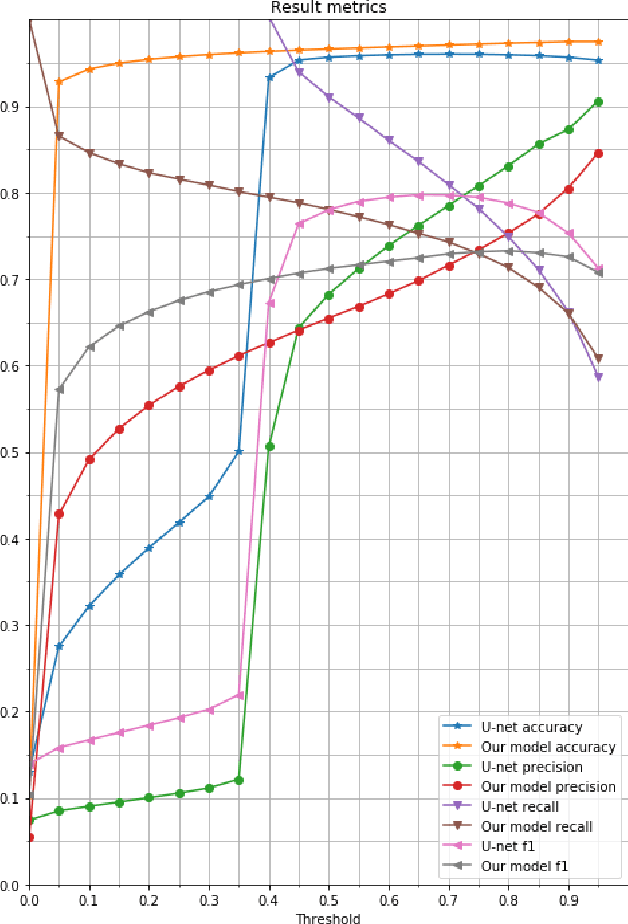
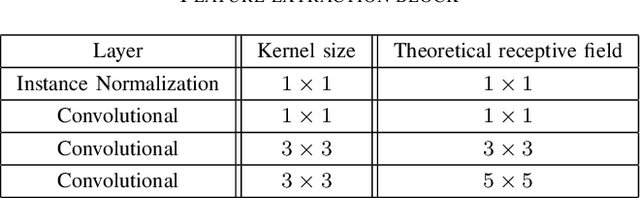
Glare is a phenomenon that occurs when the scene has a reflection of a light source or has one in it. This luminescence can hide useful information from the image, making text recognition virtually impossible. In this paper, we propose an approach to detect glare in images taken by users via mobile devices. Our method divides the document into blocks and collects luminance features from the original image and black-white strokes histograms of the binarized image. Finally, glare is detected using a convolutional neural network on the aforementioned histograms and luminance features. The network consists of several feature extraction blocks, one for each type of input, and the detection block, which calculates the resulting glare heatmap based on the output of the extraction part. The proposed solution detects glare with high recall and f-score.
FaSTExt: Fast and Small Text Extractor
Aug 14, 2019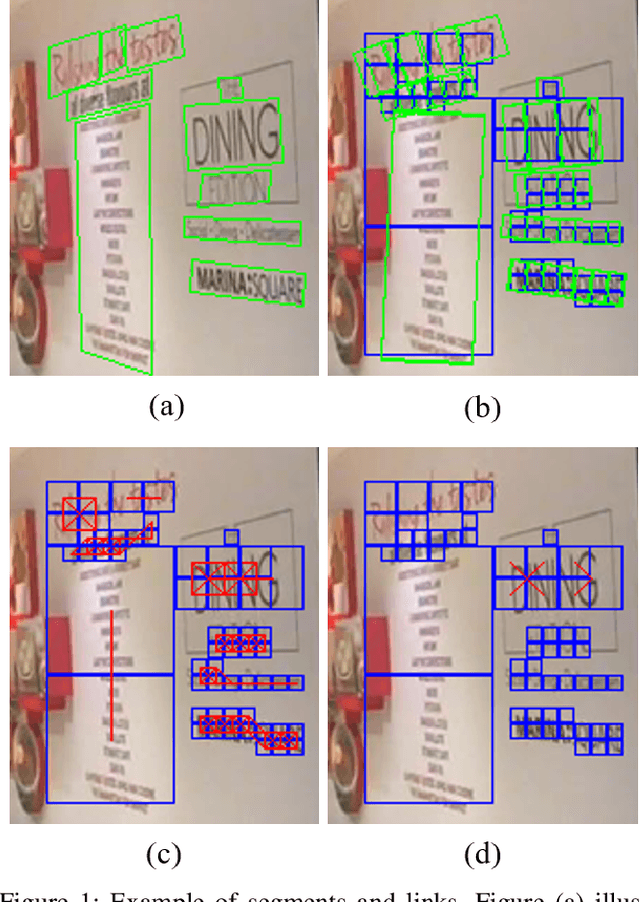

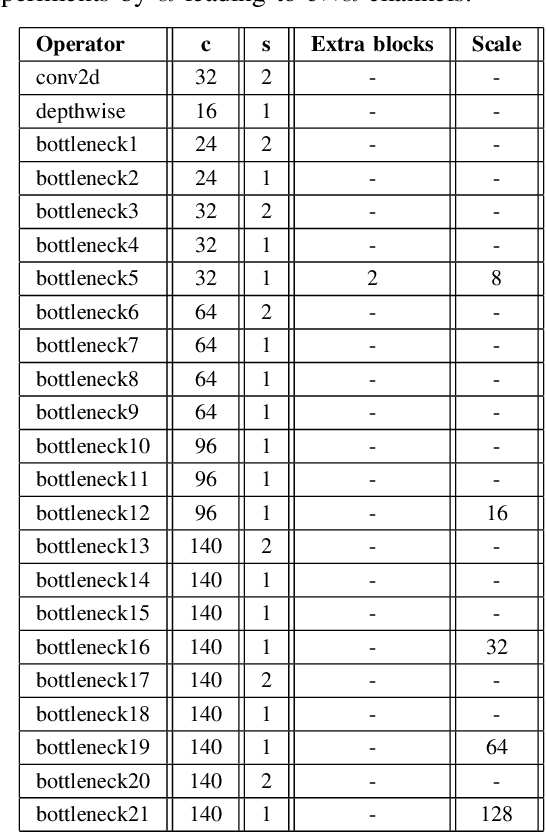
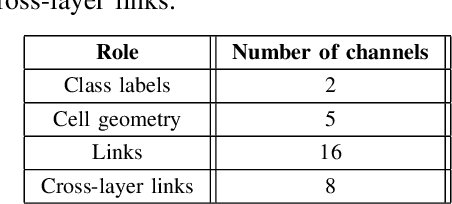
Text detection in natural images is a challenging but necessary task for many applications. Existing approaches utilize large deep convolutional neural networks making it difficult to use them in real-world tasks. We propose a small yet relatively precise text extraction method. The basic component of it is a convolutional neural network which works in a fully-convolutional manner and produces results at multiple scales. Each scale output predicts whether a pixel is a part of some word, its geometry, and its relation to neighbors at the same scale and between scales. The key factor of reducing the complexity of the model was the utilization of depthwise separable convolution, linear bottlenecks, and inverted residuals. Experiments on public datasets show that the proposed network can effectively detect text while keeping the number of parameters in the range of 1.58 to 10.59 million in different configurations.