 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Visual Autoregressive Models
Jun 04, 2026Autoregressive (AR) image generation models are highly expressive but computationally intensive, motivating effective model compression. Knowledge distillation (KD) is a natural approach for model compression and has been widely studied in language modeling, yet its behavior in visual AR generation remains underexplored. In this work, we present the first systematic study of distillation strategies for AR image models. Our analysis shows that while standard distillation can yield meaningful gains, recent methods developed for language do not directly transfer to images: long decoding horizons and visual token ambiguity make teacher supervision unreliable especially under student-conditioned contexts. To address this, we propose VarKD, a distillation framework for visual autoregressive models that distills on student samples while selectively applying teacher supervision and reducing token-level ambiguity. Experiments on ImageNet across multiple AR backbones show that VarKD consistently outperforms prior distillation baselines, narrowing the gap to large-scale models.
Multi-Scale Local Speculative Decoding for Image Generation
Jan 08, 2026Autoregressive (AR) models have achieved remarkable success in image synthesis, yet their sequential nature imposes significant latency constraints. Speculative Decoding offers a promising avenue for acceleration, but existing approaches are limited by token-level ambiguity and lack of spatial awareness. In this work, we introduce Multi-Scale Local Speculative Decoding (MuLo-SD), a novel framework that combines multi-resolution drafting with spatially informed verification to accelerate AR image generation. Our method leverages a low-resolution drafter paired with learned up-samplers to propose candidate image tokens, which are then verified in parallel by a high-resolution target model. Crucially, we incorporate a local rejection and resampling mechanism, enabling efficient correction of draft errors by focusing on spatial neighborhoods rather than raster-scan resampling after the first rejection. We demonstrate that MuLo-SD achieves substantial speedups - up to $\mathbf{1.7\times}$ - outperforming strong speculative decoding baselines such as EAGLE-2 and LANTERN in terms of acceleration, while maintaining comparable semantic alignment and perceptual quality. These results are validated using GenEval, DPG-Bench, and FID/HPSv2 on the MS-COCO 5k validation split. Extensive ablations highlight the impact of up-sampling design, probability pooling, and local rejection and resampling with neighborhood expansion. Our approach sets a new state-of-the-art in speculative decoding for image synthesis, bridging the gap between efficiency and fidelity.
RAGME: Retrieval Augmented Video Generation for Enhanced Motion Realism
Apr 09, 2025



Video generation is experiencing rapid growth, driven by advances in diffusion models and the development of better and larger datasets. However, producing high-quality videos remains challenging due to the high-dimensional data and the complexity of the task. Recent efforts have primarily focused on enhancing visual quality and addressing temporal inconsistencies, such as flickering. Despite progress in these areas, the generated videos often fall short in terms of motion complexity and physical plausibility, with many outputs either appearing static or exhibiting unrealistic motion. In this work, we propose a framework to improve the realism of motion in generated videos, exploring a complementary direction to much of the existing literature. Specifically, we advocate for the incorporation of a retrieval mechanism during the generation phase. The retrieved videos act as grounding signals, providing the model with demonstrations of how the objects move. Our pipeline is designed to apply to any text-to-video diffusion model, conditioning a pretrained model on the retrieved samples with minimal fine-tuning. We demonstrate the superiority of our approach through established metrics, recently proposed benchmarks, and qualitative results, and we highlight additional applications of the framework.
Safe Vision-Language Models via Unsafe Weights Manipulation
Mar 14, 2025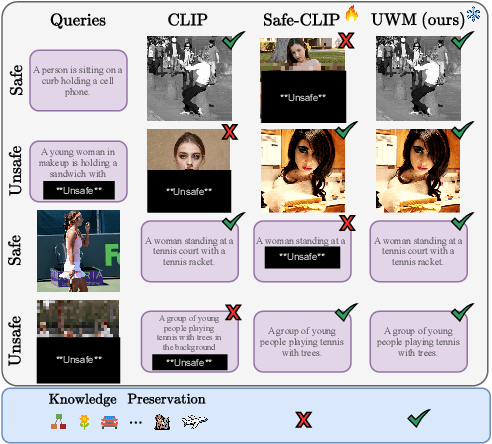



Vision-language models (VLMs) often inherit the biases and unsafe associations present within their large-scale training dataset. While recent approaches mitigate unsafe behaviors, their evaluation focuses on how safe the model is on unsafe inputs, ignoring potential shortcomings on safe ones. In this paper, we first revise safety evaluation by introducing SafeGround, a new set of metrics that evaluate safety at different levels of granularity. With this metric, we uncover a surprising issue of training-based methods: they make the model less safe on safe inputs. From this finding, we take a different direction and explore whether it is possible to make a model safer without training, introducing Unsafe Weights Manipulation (UWM). UWM uses a calibration set of safe and unsafe instances to compare activations between safe and unsafe content, identifying the most important parameters for processing the latter. Their values are then manipulated via negation. Experiments show that UWM achieves the best tradeoff between safety and knowledge preservation, consistently improving VLMs on unsafe queries while outperforming even training-based state-of-the-art methods on safe ones.
GradBias: Unveiling Word Influence on Bias in Text-to-Image Generative Models
Aug 29, 2024



Recent progress in Text-to-Image (T2I) generative models has enabled high-quality image generation. As performance and accessibility increase, these models are gaining significant attraction and popularity: ensuring their fairness and safety is a priority to prevent the dissemination and perpetuation of biases. However, existing studies in bias detection focus on closed sets of predefined biases (e.g., gender, ethnicity). In this paper, we propose a general framework to identify, quantify, and explain biases in an open set setting, i.e. without requiring a predefined set. This pipeline leverages a Large Language Model (LLM) to propose biases starting from a set of captions. Next, these captions are used by the target generative model for generating a set of images. Finally, Vision Question Answering (VQA) is leveraged for bias evaluation. We show two variations of this framework: OpenBias and GradBias. OpenBias detects and quantifies biases, while GradBias determines the contribution of individual prompt words on biases. OpenBias effectively detects both well-known and novel biases related to people, objects, and animals and highly aligns with existing closed-set bias detection methods and human judgment. GradBias shows that neutral words can significantly influence biases and it outperforms several baselines, including state-of-the-art foundation models. Code available here: https://github.com/Moreno98/GradBias.
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024



Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Collaborative Neural Painting
Dec 04, 2023The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users' modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
PAIR-Diffusion: Object-Level Image Editing with Structure-and-Appearance Paired Diffusion Models
Mar 30, 2023Image editing using diffusion models has witnessed extremely fast-paced growth recently. There are various ways in which previous works enable controlling and editing images. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we consider an image as a composition of multiple objects, each defined by various properties. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose Structure-and-Appearance Paired Diffusion model (PAIR-Diffusion), which is trained using structure and appearance information explicitly extracted from the images. The proposed model enables users to inject a reference image's appearance into the input image at both the object and global levels. Additionally, PAIR-Diffusion allows editing the structure while maintaining the style of individual components of the image unchanged. We extensively evaluate our method on LSUN datasets and the CelebA-HQ face dataset, and we demonstrate fine-grained control over both structure and appearance at the object level. We also applied the method to Stable Diffusion to edit any real image at the object level.