 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement Speaker Similarity for Zero-Shot Any-to-Any Voice Conversion of Whispered and Regular Speech
Aug 21, 2024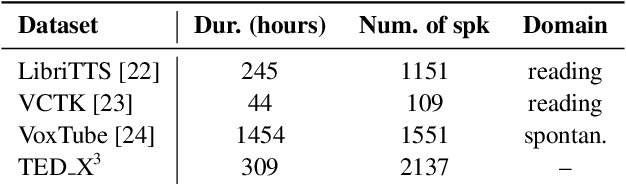
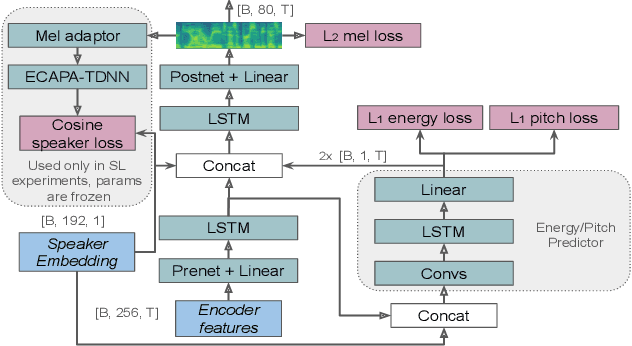

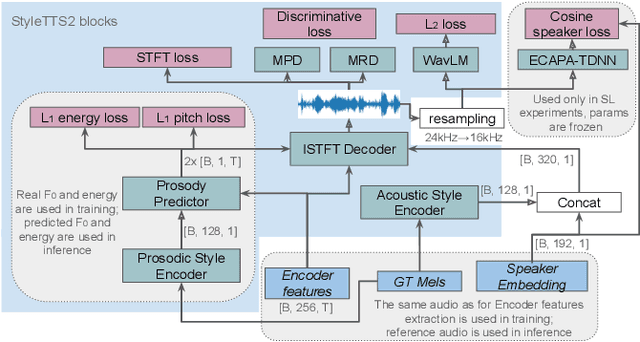
Zero-shot voice conversion aims to transfer the voice of a source speaker to that of a speaker unseen during training, while preserving the content information. Although various methods have been proposed to reconstruct speaker information in generated speech, there is still room for improvement in achieving high similarity between generated and ground truth recordings. Furthermore, zero-shot voice conversion for speech in specific domains, such as whispered, remains an unexplored area. To address this problem, we propose a SpeakerVC model that can effectively perform zero-shot speech conversion in both voiced and whispered domains, while being lightweight and capable of running in streaming mode without significant quality degradation. In addition, we explore methods to improve the quality of speaker identity transfer and demonstrate their effectiveness for a variety of voice conversion systems.
Robust Speaker Recognition with Transformers Using wav2vec 2.0
Mar 28, 2022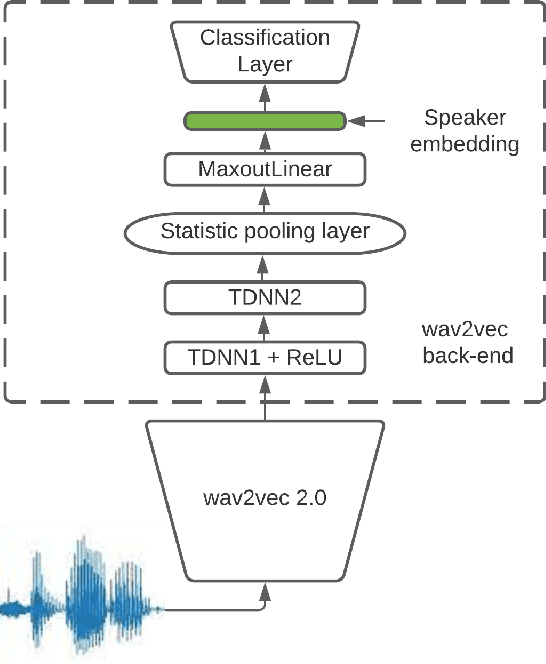

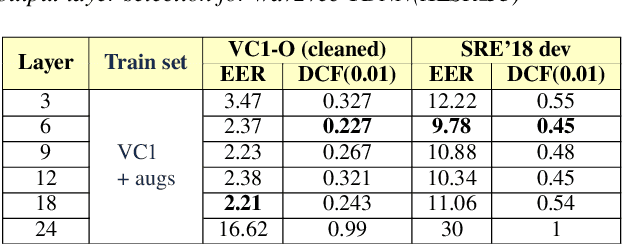
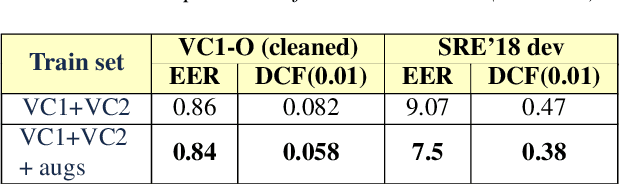
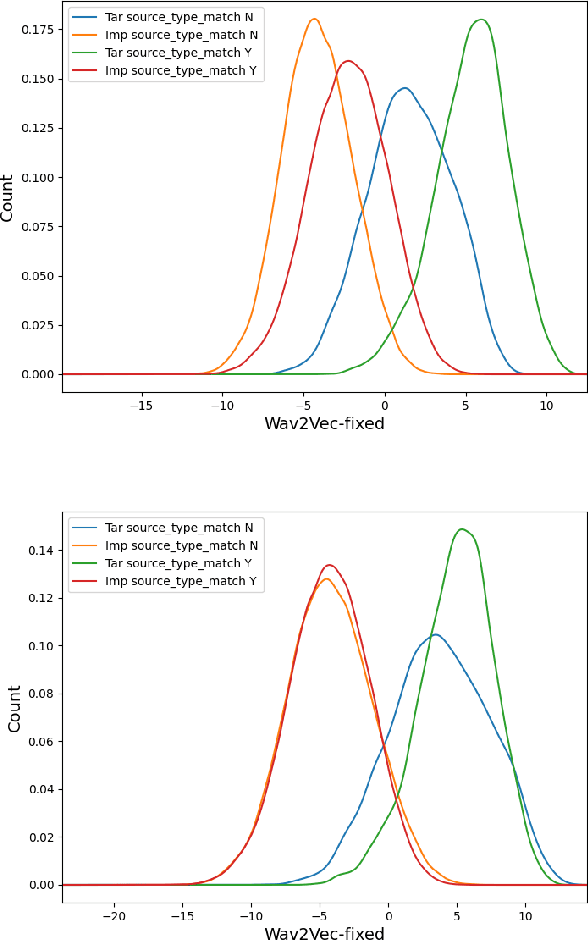
Recent advances in unsupervised speech representation learning discover new approaches and provide new state-of-the-art for diverse types of speech processing tasks. This paper presents an investigation of using wav2vec 2.0 deep speech representations for the speaker recognition task. The proposed fine-tuning procedure of wav2vec 2.0 with simple TDNN and statistic pooling back-end using additive angular margin loss allows to obtain deep speaker embedding extractor that is well-generalized across different domains. It is concluded that Contrastive Predictive Coding pretraining scheme efficiently utilizes the power of unlabeled data, and thus opens the door to powerful transformer-based speaker recognition systems. The experimental results obtained in this study demonstrate that fine-tuning can be done on relatively small sets and a clean version of data. Using data augmentation during fine-tuning provides additional performance gains in speaker verification. In this study speaker recognition systems were analyzed on a wide range of well-known verification protocols: VoxCeleb1 cleaned test set, NIST SRE 18 development set, NIST SRE 2016 and NIST SRE 2019 evaluation set, VOiCES evaluation set, NIST 2021 SRE, and CTS challenges sets.
STC speaker recognition systems for the NIST SRE 2021
Nov 03, 2021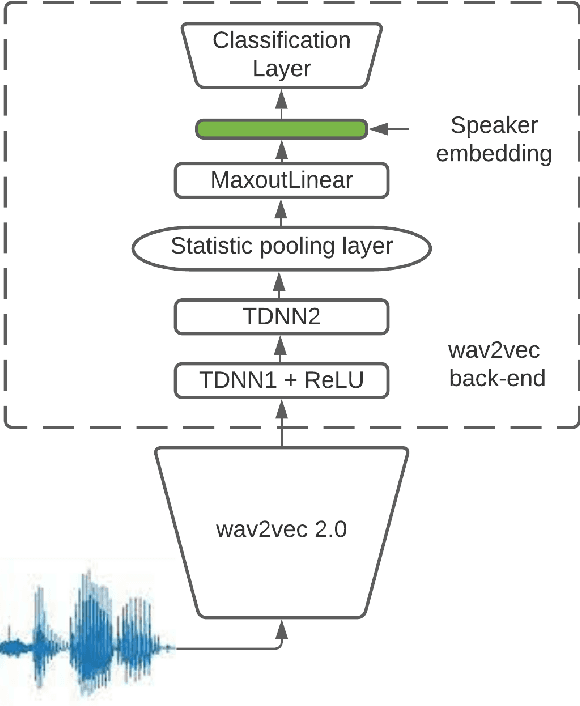
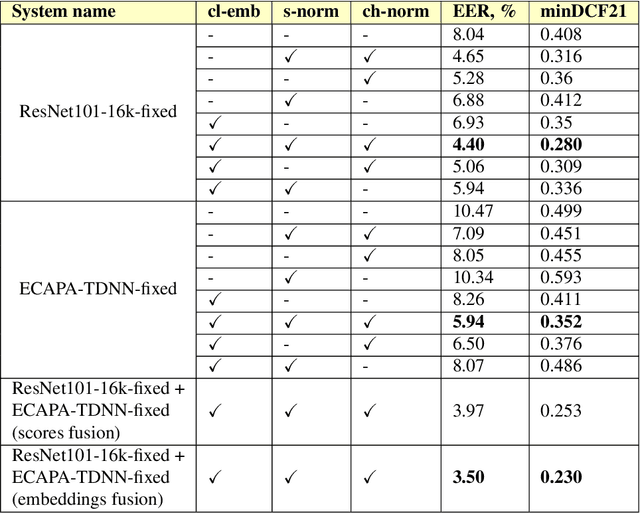

This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.
Deep Speaker Embeddings for Far-Field Speaker Recognition on Short Utterances
Feb 14, 2020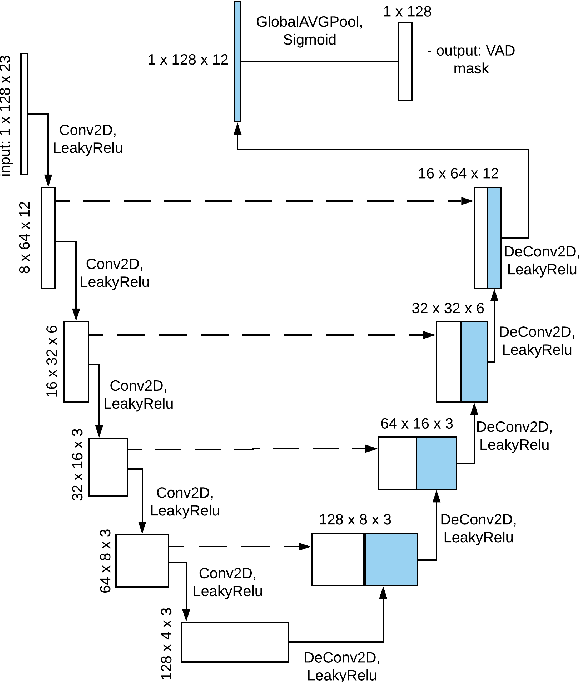
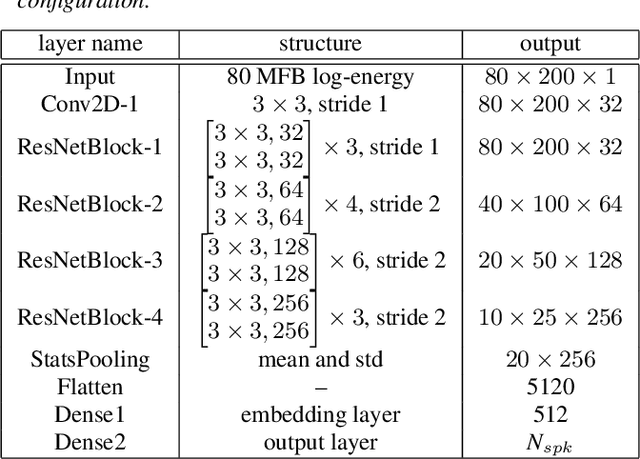
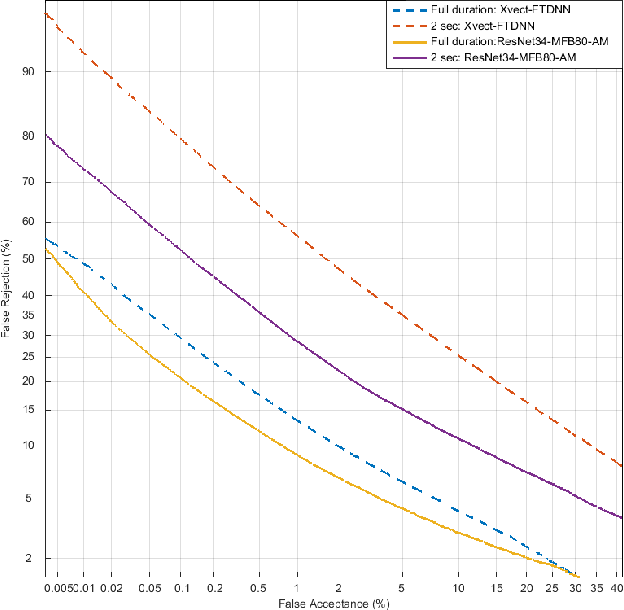
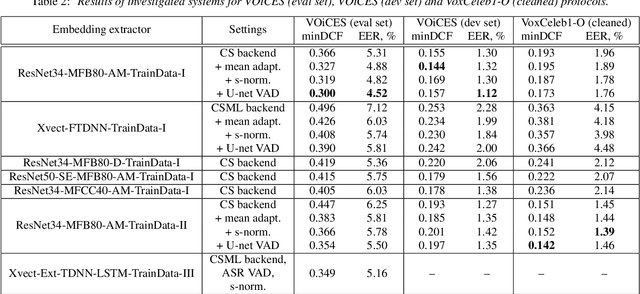
Speaker recognition systems based on deep speaker embeddings have achieved significant performance in controlled conditions according to the results obtained for early NIST SRE (Speaker Recognition Evaluation) datasets. From the practical point of view, taking into account the increased interest in virtual assistants (such as Amazon Alexa, Google Home, AppleSiri, etc.), speaker verification on short utterances in uncontrolled noisy environment conditions is one of the most challenging and highly demanded tasks. This paper presents approaches aimed to achieve two goals: a) improve the quality of far-field speaker verification systems in the presence of environmental noise, reverberation and b) reduce the system qualitydegradation for short utterances. For these purposes, we considered deep neural network architectures based on TDNN (TimeDelay Neural Network) and ResNet (Residual Neural Network) blocks. We experimented with state-of-the-art embedding extractors and their training procedures. Obtained results confirm that ResNet architectures outperform the standard x-vector approach in terms of speaker verification quality for both long-duration and short-duration utterances. We also investigate the impact of speech activity detector, different scoring models, adaptation and score normalization techniques. The experimental results are presented for publicly available data and verification protocols for the VoxCeleb1, VoxCeleb2, and VOiCES datasets.