 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Different Calibration Methods for Deep Speaker Embedding based Verification Systems
Mar 28, 2022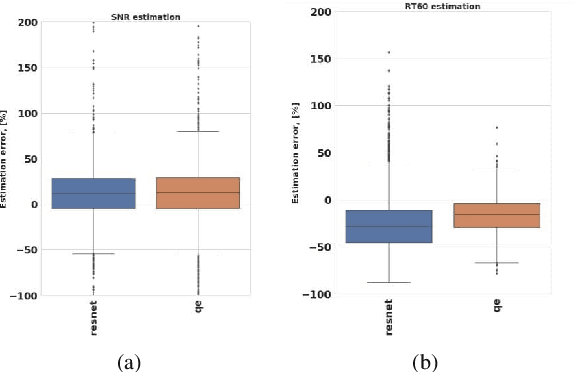
Deep speaker embedding extractors have already become new state-of-the-art systems in the speaker verification field. However, the problem of verification score calibration for such systems often remains out of focus. An irrelevant score calibration leads to serious issues, especially in the case of unknown acoustic conditions, even if we use a strong speaker verification system in terms of threshold-free metrics. This paper presents an investigation over several methods of score calibration: a classical approach based on the logistic regression model; the recently presented magnitude estimation network MagnetO that uses activations from the pooling layer of the trained deep speaker extractor and generalization of such approach based on separate scale and offset prediction neural networks. An additional focus of this research is to estimate the impact of score normalization on the calibration performance of the system. The obtained results demonstrate that there are no serious problems if in-domain development data are used for calibration tuning. Otherwise, a trade-off between good calibration performance and threshold-free system quality arises. In most cases using adaptive s-norm helps to stabilize score distributions and to improve system performance. Meanwhile, some experiments demonstrate that novel approaches have their limits in score stabilization on several datasets.
STC speaker recognition systems for the NIST SRE 2021
Nov 03, 2021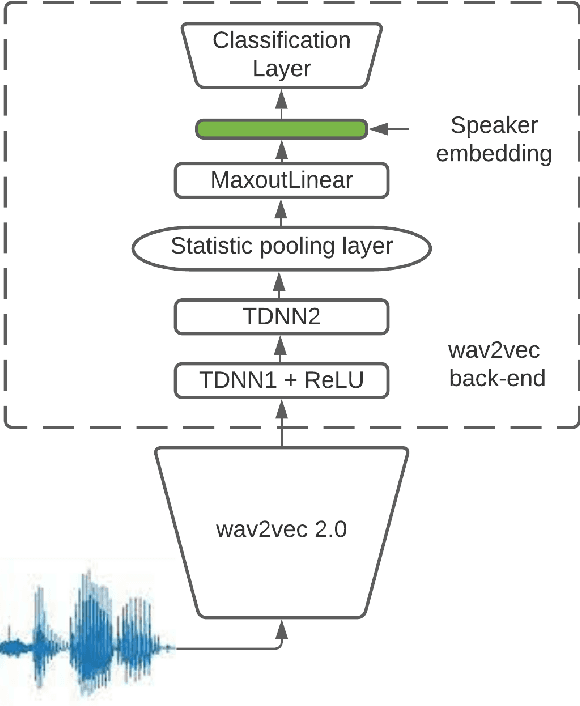
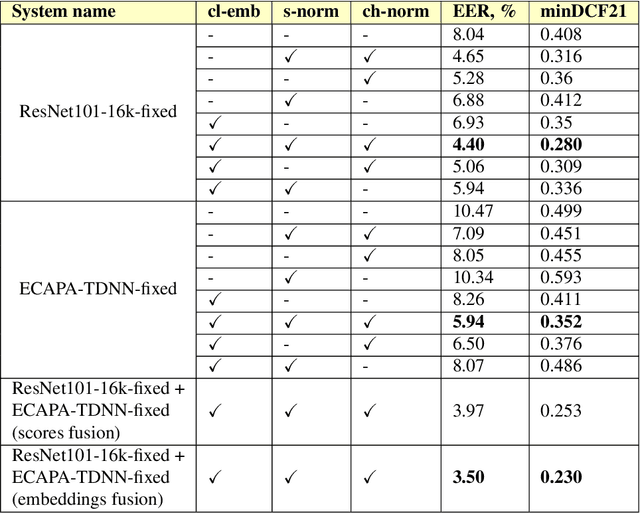
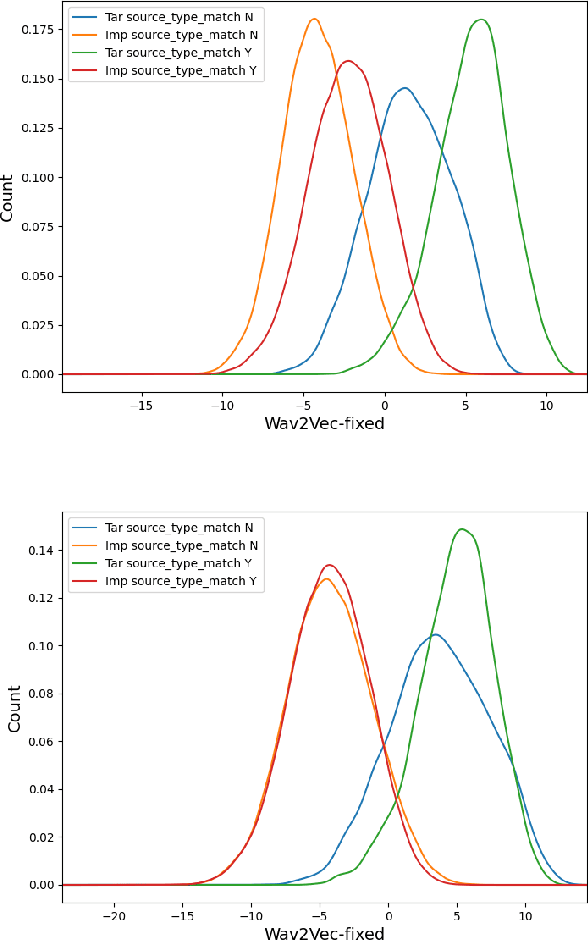

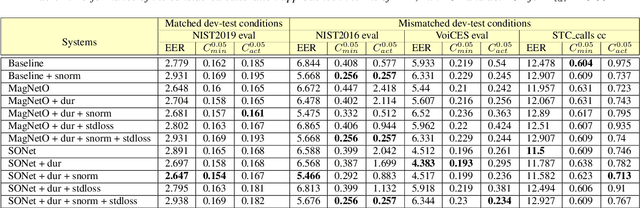
This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.
Deep Speaker Embeddings for Far-Field Speaker Recognition on Short Utterances
Feb 14, 2020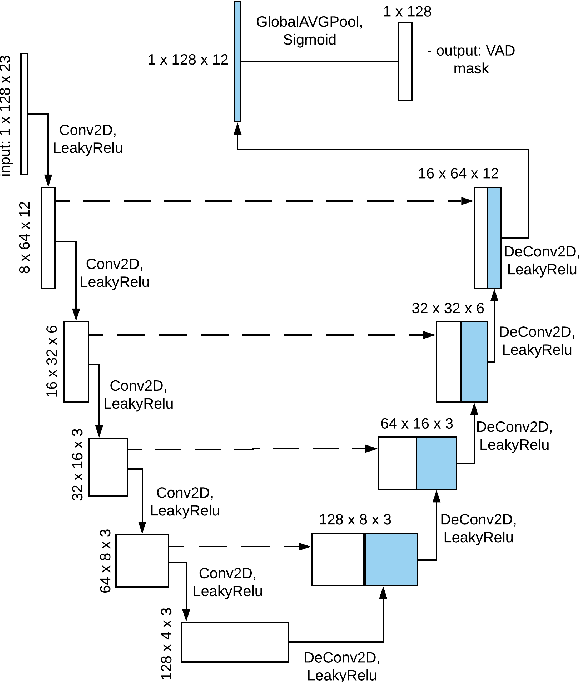
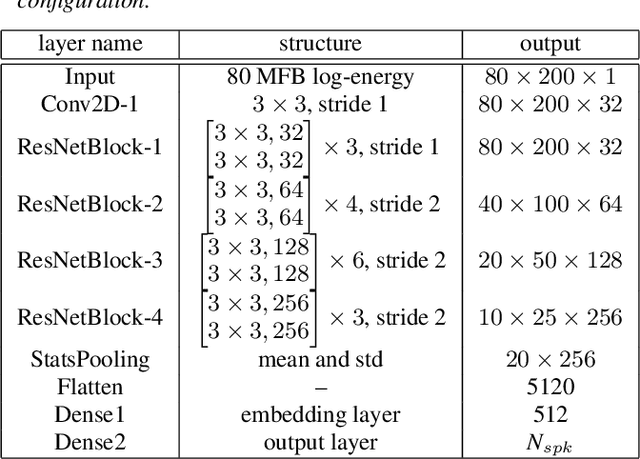
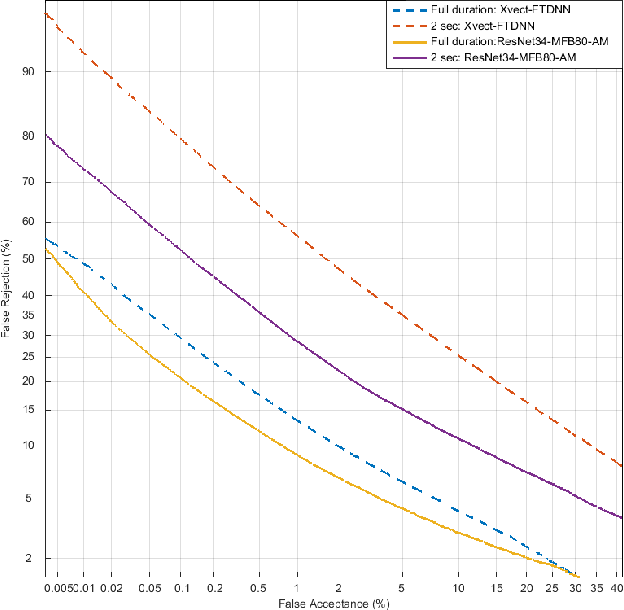
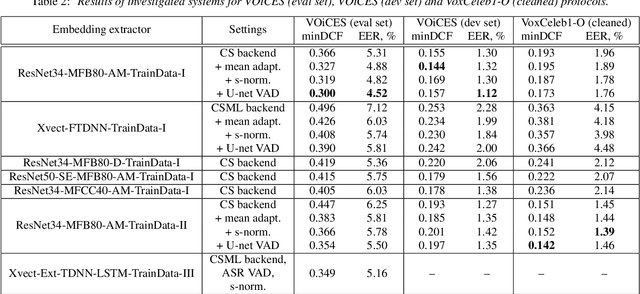
Speaker recognition systems based on deep speaker embeddings have achieved significant performance in controlled conditions according to the results obtained for early NIST SRE (Speaker Recognition Evaluation) datasets. From the practical point of view, taking into account the increased interest in virtual assistants (such as Amazon Alexa, Google Home, AppleSiri, etc.), speaker verification on short utterances in uncontrolled noisy environment conditions is one of the most challenging and highly demanded tasks. This paper presents approaches aimed to achieve two goals: a) improve the quality of far-field speaker verification systems in the presence of environmental noise, reverberation and b) reduce the system qualitydegradation for short utterances. For these purposes, we considered deep neural network architectures based on TDNN (TimeDelay Neural Network) and ResNet (Residual Neural Network) blocks. We experimented with state-of-the-art embedding extractors and their training procedures. Obtained results confirm that ResNet architectures outperform the standard x-vector approach in terms of speaker verification quality for both long-duration and short-duration utterances. We also investigate the impact of speech activity detector, different scoring models, adaptation and score normalization techniques. The experimental results are presented for publicly available data and verification protocols for the VoxCeleb1, VoxCeleb2, and VOiCES datasets.
STC Speaker Recognition Systems for the VOiCES From a Distance Challenge
Apr 12, 2019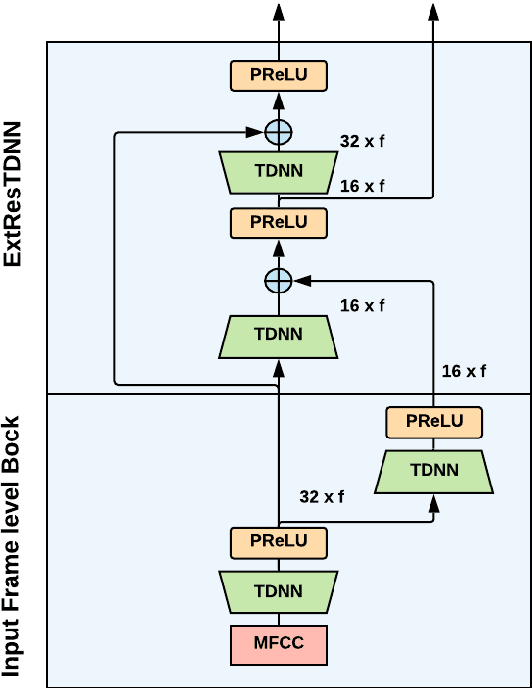



This paper presents the Speech Technology Center (STC) speaker recognition (SR) systems submitted to the VOiCES From a Distance challenge 2019. The challenge's SR task is focused on the problem of speaker recognition in single channel distant/far-field audio under noisy conditions. In this work we investigate different deep neural networks architectures for speaker embedding extraction to solve the task. We show that deep networks with residual frame level connections outperform more shallow architectures. Simple energy based speech activity detector (SAD) and automatic speech recognition (ASR) based SAD are investigated in this work. We also address the problem of data preparation for robust embedding extractors training. The reverberation for the data augmentation was performed using automatic room impulse response generator. In our systems we used discriminatively trained cosine similarity metric learning model as embedding backend. Scores normalization procedure was applied for each individual subsystem we used. Our final submitted systems were based on the fusion of different subsystems. The results obtained on the VOiCES development and evaluation sets demonstrate effectiveness and robustness of the proposed systems when dealing with distant/far-field audio under noisy conditions.
On deep speaker embeddings for text-independent speaker recognition
Apr 26, 2018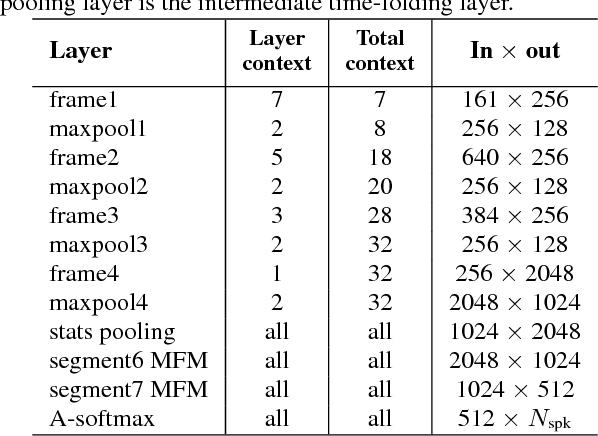

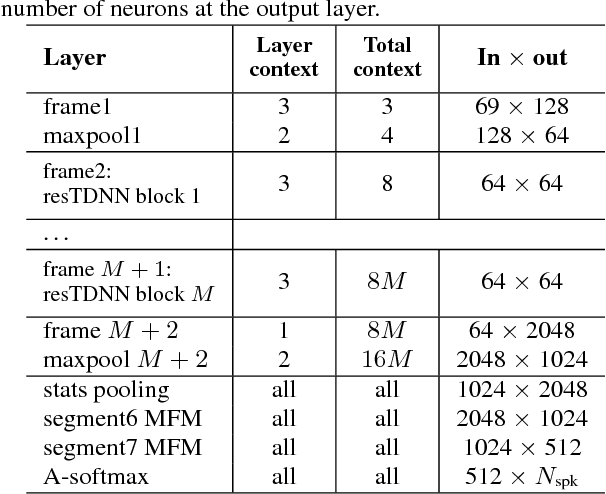
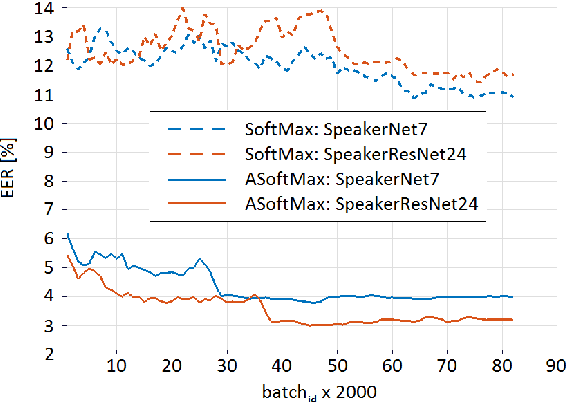
We investigate deep neural network performance in the textindependent speaker recognition task. We demonstrate that using angular softmax activation at the last classification layer of a classification neural network instead of a simple softmax activation allows to train a more generalized discriminative speaker embedding extractor. Cosine similarity is an effective metric for speaker verification in this embedding space. We also address the problem of choosing an architecture for the extractor. We found that deep networks with residual frame level connections outperform wide but relatively shallow architectures. This paper also proposes several improvements for previous DNN-based extractor systems to increase the speaker recognition accuracy. We show that the discriminatively trained similarity metric learning approach outperforms the standard LDA-PLDA method as an embedding backend. The results obtained on Speakers in the Wild and NIST SRE 2016 evaluation sets demonstrate robustness of the proposed systems when dealing with close to real-life conditions.