 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTC Speaker Recognition Systems for the VOiCES From a Distance Challenge
Paper and Code
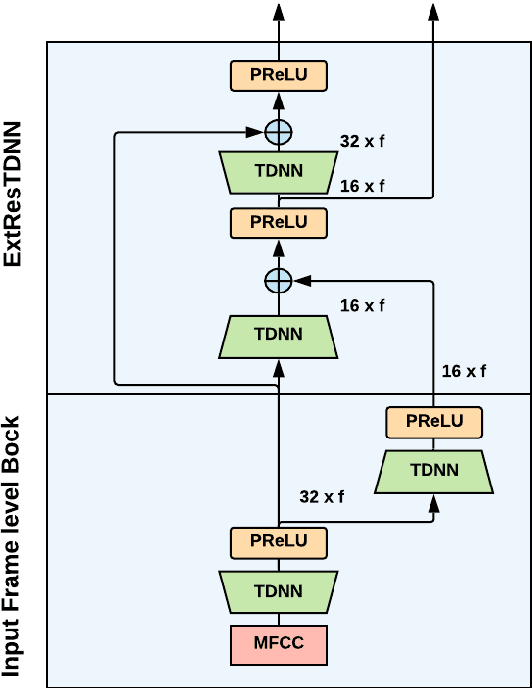



This paper presents the Speech Technology Center (STC) speaker recognition (SR) systems submitted to the VOiCES From a Distance challenge 2019. The challenge's SR task is focused on the problem of speaker recognition in single channel distant/far-field audio under noisy conditions. In this work we investigate different deep neural networks architectures for speaker embedding extraction to solve the task. We show that deep networks with residual frame level connections outperform more shallow architectures. Simple energy based speech activity detector (SAD) and automatic speech recognition (ASR) based SAD are investigated in this work. We also address the problem of data preparation for robust embedding extractors training. The reverberation for the data augmentation was performed using automatic room impulse response generator. In our systems we used discriminatively trained cosine similarity metric learning model as embedding backend. Scores normalization procedure was applied for each individual subsystem we used. Our final submitted systems were based on the fusion of different subsystems. The results obtained on the VOiCES development and evaluation sets demonstrate effectiveness and robustness of the proposed systems when dealing with distant/far-field audio under noisy conditions.