 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Hidden Temporal Structure of HubertSoft Embeddings based on the Russian Phonetic Corpus
Jul 09, 2025



Self-supervised learning (SSL) models such as Wav2Vec 2.0 and HuBERT have shown remarkable success in extracting phonetic information from raw audio without labelled data. While prior work has demonstrated that SSL embeddings encode phonetic features at the frame level, it remains unclear whether these models preserve temporal structure, specifically, whether embeddings at phoneme boundaries reflect the identity and order of adjacent phonemes. This study investigates the extent to which boundary-sensitive embeddings from HubertSoft, a soft-clustering variant of HuBERT, encode phoneme transitions. Using the CORPRES Russian speech corpus, we labelled 20 ms embedding windows with triplets of phonemes corresponding to their start, centre, and end segments. A neural network was trained to predict these positions separately, and multiple evaluation metrics, such as ordered, unordered accuracy and a flexible centre accuracy, were used to assess temporal sensitivity. Results show that embeddings extracted at phoneme boundaries capture both phoneme identity and temporal order, with especially high accuracy at segment boundaries. Confusion patterns further suggest that the model encodes articulatory detail and coarticulatory effects. These findings contribute to our understanding of the internal structure of SSL speech representations and their potential for phonological analysis and fine-grained transcription tasks.
Investigation of Different Calibration Methods for Deep Speaker Embedding based Verification Systems
Mar 28, 2022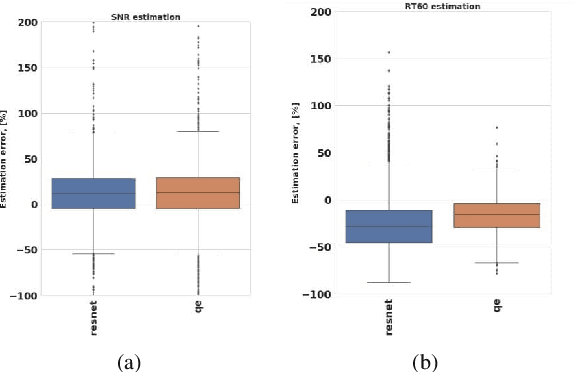
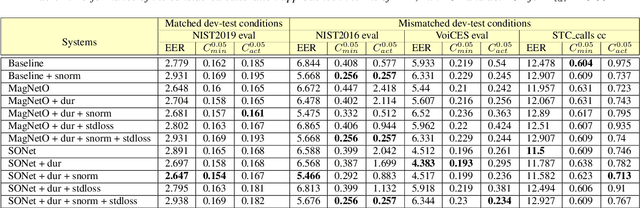
Deep speaker embedding extractors have already become new state-of-the-art systems in the speaker verification field. However, the problem of verification score calibration for such systems often remains out of focus. An irrelevant score calibration leads to serious issues, especially in the case of unknown acoustic conditions, even if we use a strong speaker verification system in terms of threshold-free metrics. This paper presents an investigation over several methods of score calibration: a classical approach based on the logistic regression model; the recently presented magnitude estimation network MagnetO that uses activations from the pooling layer of the trained deep speaker extractor and generalization of such approach based on separate scale and offset prediction neural networks. An additional focus of this research is to estimate the impact of score normalization on the calibration performance of the system. The obtained results demonstrate that there are no serious problems if in-domain development data are used for calibration tuning. Otherwise, a trade-off between good calibration performance and threshold-free system quality arises. In most cases using adaptive s-norm helps to stabilize score distributions and to improve system performance. Meanwhile, some experiments demonstrate that novel approaches have their limits in score stabilization on several datasets.
Deep Speaker Embeddings for Far-Field Speaker Recognition on Short Utterances
Feb 14, 2020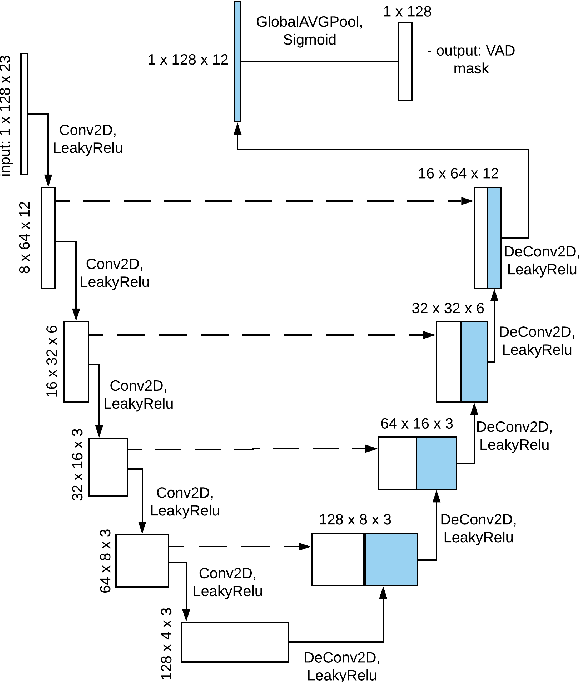
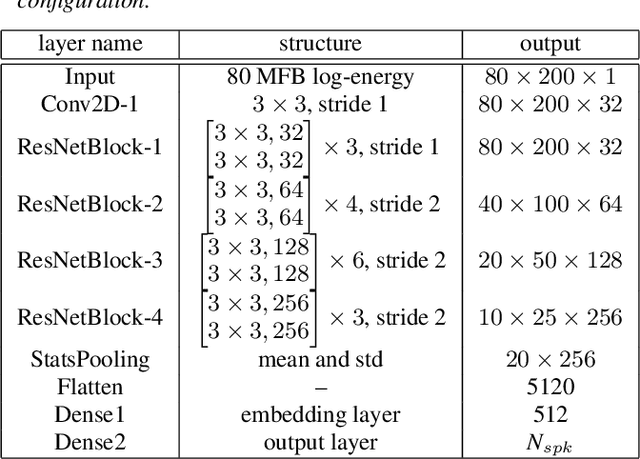
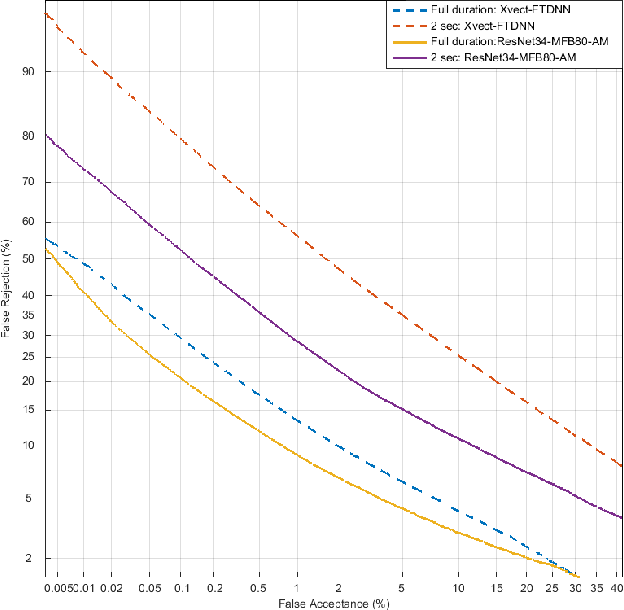
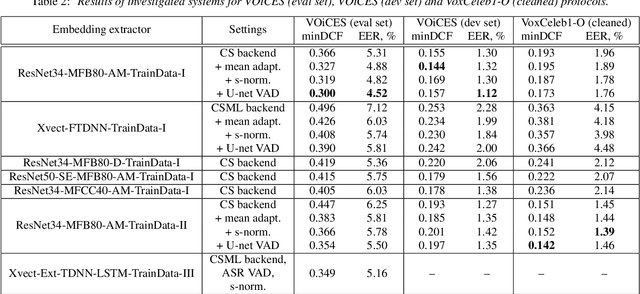
Speaker recognition systems based on deep speaker embeddings have achieved significant performance in controlled conditions according to the results obtained for early NIST SRE (Speaker Recognition Evaluation) datasets. From the practical point of view, taking into account the increased interest in virtual assistants (such as Amazon Alexa, Google Home, AppleSiri, etc.), speaker verification on short utterances in uncontrolled noisy environment conditions is one of the most challenging and highly demanded tasks. This paper presents approaches aimed to achieve two goals: a) improve the quality of far-field speaker verification systems in the presence of environmental noise, reverberation and b) reduce the system qualitydegradation for short utterances. For these purposes, we considered deep neural network architectures based on TDNN (TimeDelay Neural Network) and ResNet (Residual Neural Network) blocks. We experimented with state-of-the-art embedding extractors and their training procedures. Obtained results confirm that ResNet architectures outperform the standard x-vector approach in terms of speaker verification quality for both long-duration and short-duration utterances. We also investigate the impact of speech activity detector, different scoring models, adaptation and score normalization techniques. The experimental results are presented for publicly available data and verification protocols for the VoxCeleb1, VoxCeleb2, and VOiCES datasets.
STC Antispoofing Systems for the ASVspoof2019 Challenge
Apr 11, 2019

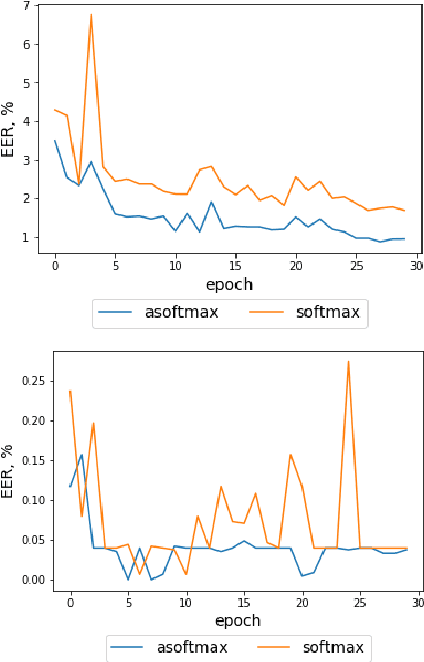

This paper describes the Speech Technology Center (STC) antispoofing systems submitted to the ASVspoof 2019 challenge. The ASVspoof2019 is the extended version of the previous challenges and includes 2 evaluation conditions: logical access use-case scenario with speech synthesis and voice conversion attack types and physical access use-case scenario with replay attacks. During the challenge we developed anti-spoofing solutions for both scenarios. The proposed systems are implemented using deep learning approach and are based on different types of acoustic features. We enhanced Light CNN architecture previously considered by the authors for replay attacks detection and which performed high spoofing detection quality during the ASVspoof2017 challenge. In particular here we investigate the efficiency of angular margin based softmax activation for training robust deep Light CNN classifier to solve the mentioned-above tasks. Submitted systems achieved EER of 1.86% in logical access scenario and 0.54% in physical access scenario on the evaluation part of the Challenge corpora. High performance obtained for the unknown types of spoofing attacks demonstrates the stability of the offered approach in both evaluation conditions.