 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement Speaker Similarity for Zero-Shot Any-to-Any Voice Conversion of Whispered and Regular Speech
Paper and Code
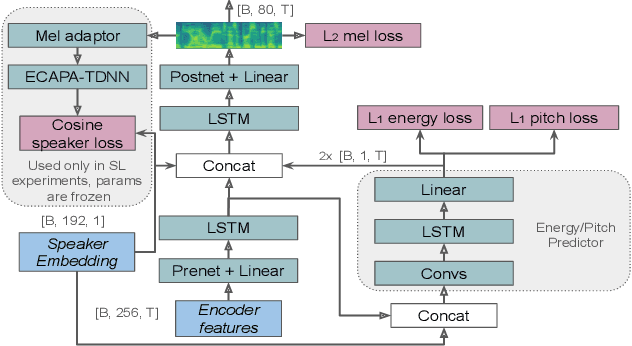

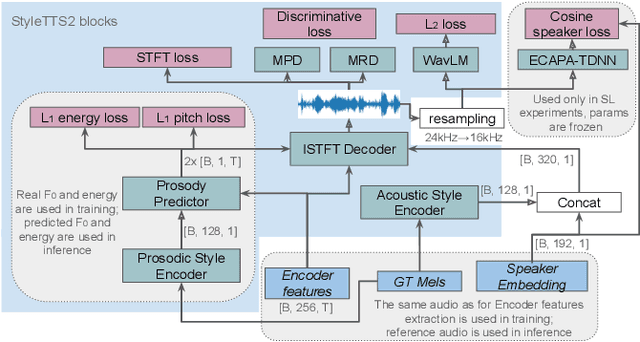
Zero-shot voice conversion aims to transfer the voice of a source speaker to that of a speaker unseen during training, while preserving the content information. Although various methods have been proposed to reconstruct speaker information in generated speech, there is still room for improvement in achieving high similarity between generated and ground truth recordings. Furthermore, zero-shot voice conversion for speech in specific domains, such as whispered, remains an unexplored area. To address this problem, we propose a SpeakerVC model that can effectively perform zero-shot speech conversion in both voiced and whispered domains, while being lightweight and capable of running in streaming mode without significant quality degradation. In addition, we explore methods to improve the quality of speaker identity transfer and demonstrate their effectiveness for a variety of voice conversion systems.