 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speaker Recognition with Transformers Using wav2vec 2.0
Paper and Code
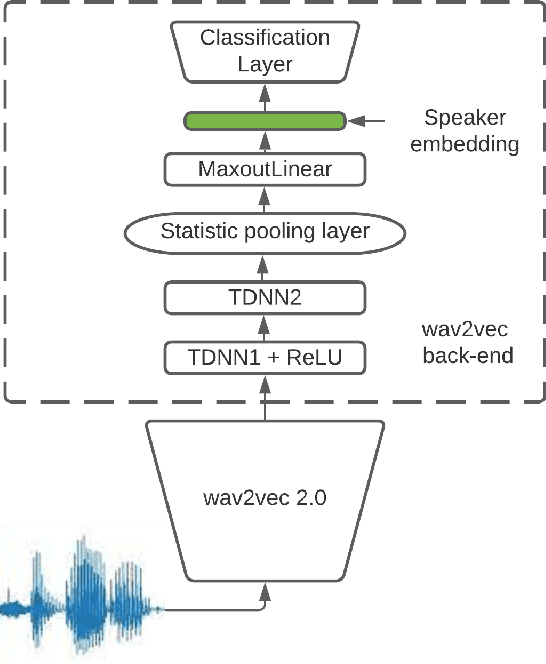

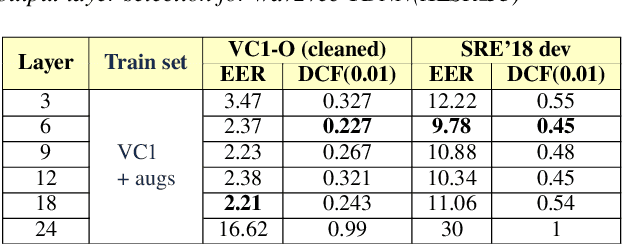
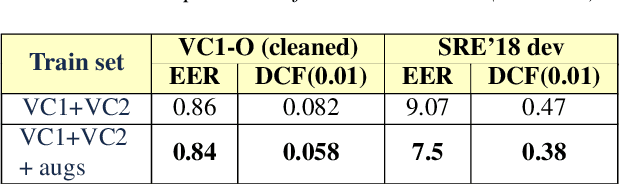
Recent advances in unsupervised speech representation learning discover new approaches and provide new state-of-the-art for diverse types of speech processing tasks. This paper presents an investigation of using wav2vec 2.0 deep speech representations for the speaker recognition task. The proposed fine-tuning procedure of wav2vec 2.0 with simple TDNN and statistic pooling back-end using additive angular margin loss allows to obtain deep speaker embedding extractor that is well-generalized across different domains. It is concluded that Contrastive Predictive Coding pretraining scheme efficiently utilizes the power of unlabeled data, and thus opens the door to powerful transformer-based speaker recognition systems. The experimental results obtained in this study demonstrate that fine-tuning can be done on relatively small sets and a clean version of data. Using data augmentation during fine-tuning provides additional performance gains in speaker verification. In this study speaker recognition systems were analyzed on a wide range of well-known verification protocols: VoxCeleb1 cleaned test set, NIST SRE 18 development set, NIST SRE 2016 and NIST SRE 2019 evaluation set, VOiCES evaluation set, NIST 2021 SRE, and CTS challenges sets.