 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Network Architecture for Real-Time Action Recognition
May 21, 2019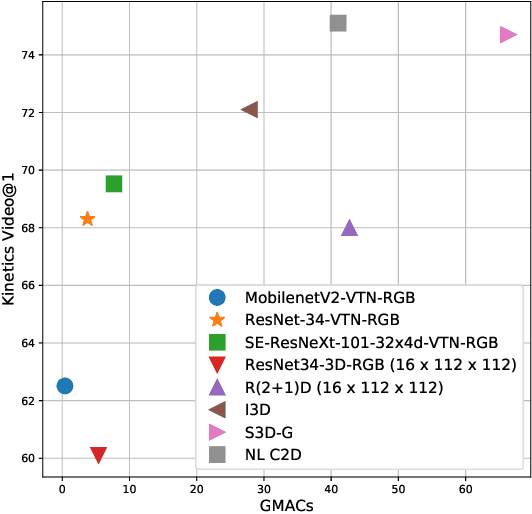

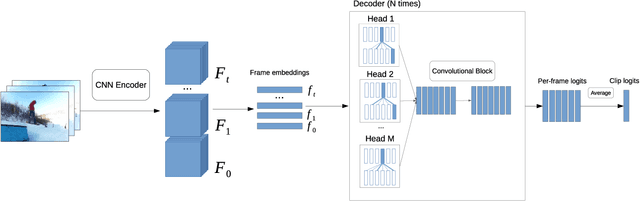

In this work we present a new efficient approach to Human Action Recognition called Video Transformer Network (VTN). It leverages the latest advances in Computer Vision and Natural Language Processing and applies them to video understanding. The proposed method allows us to create lightweight CNN models that achieve high accuracy and real-time speed using just an RGB mono camera and general purpose CPU. Furthermore, we explain how to improve accuracy by distilling from multiple models with different modalities into a single model. We conduct a comparison with state-of-the-art methods and show that our approach performs on par with most of them on famous Action Recognition datasets. We benchmark the inference time of the models using the modern inference framework and argue that our approach compares favorably with other methods in terms of speed/accuracy trade-off, running at 56 FPS on CPU. The models and the training code are available.