 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Online Multi-Modal Social Interaction Understanding
Paper and Code
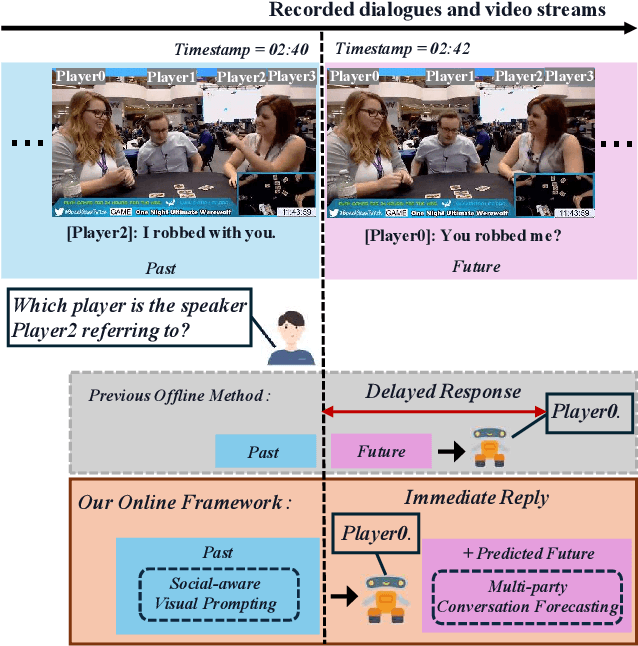
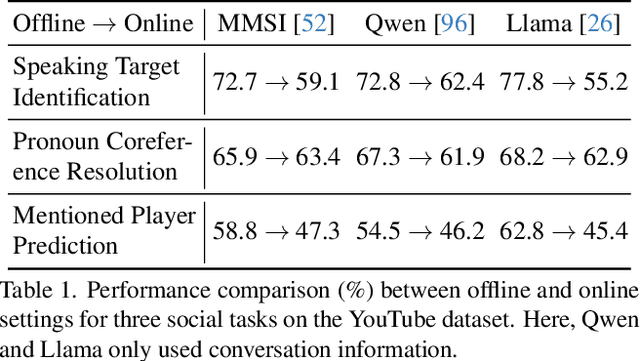
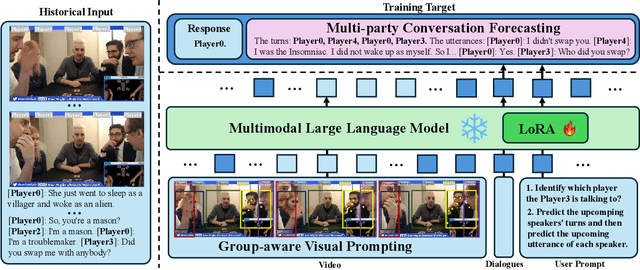
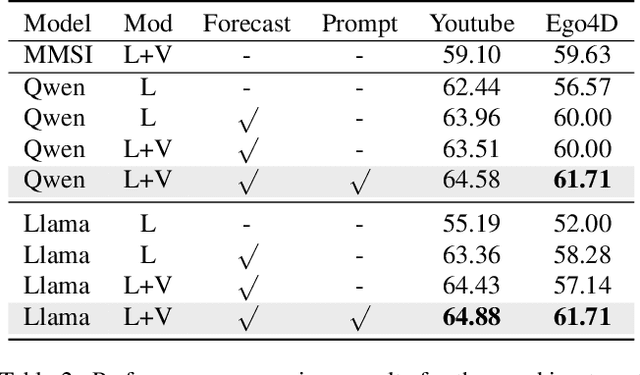
Multimodal social interaction understanding (MMSI) is critical in human-robot interaction systems. In real-world scenarios, AI agents are required to provide real-time feedback. However, existing models often depend on both past and future contexts, which hinders them from applying to real-world problems. To bridge this gap, we propose an online MMSI setting, where the model must resolve MMSI tasks using only historical information, such as recorded dialogues and video streams. To address the challenges of missing the useful future context, we develop a novel framework, named Online-MMSI-VLM, that leverages two complementary strategies: multi-party conversation forecasting and social-aware visual prompting with multi-modal large language models. First, to enrich linguistic context, the multi-party conversation forecasting simulates potential future utterances in a coarse-to-fine manner, anticipating upcoming speaker turns and then generating fine-grained conversational details. Second, to effectively incorporate visual social cues like gaze and gesture, social-aware visual prompting highlights the social dynamics in video with bounding boxes and body keypoints for each person and frame. Extensive experiments on three tasks and two datasets demonstrate that our method achieves state-of-the-art performance and significantly outperforms baseline models, indicating its effectiveness on Online-MMSI. The code and pre-trained models will be publicly released at: https://github.com/Sampson-Lee/OnlineMMSI.