 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmolVLM: Redefining small and efficient multimodal models
Apr 07, 2025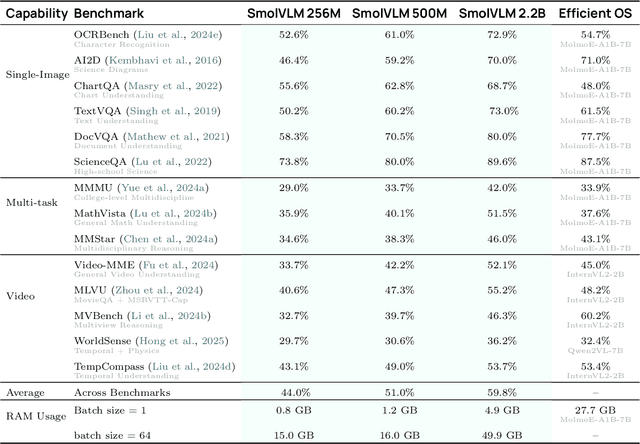
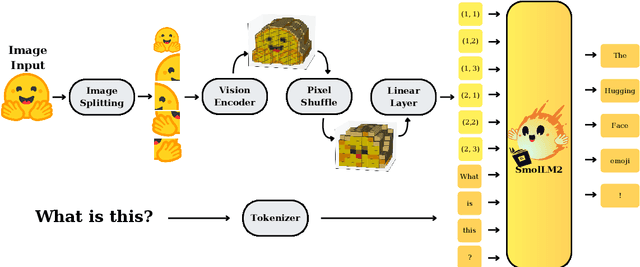
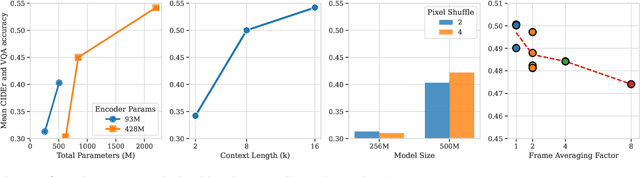

Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Jan 16, 2025



Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
Apollo: An Exploration of Video Understanding in Large Multimodal Models
Dec 13, 2024



Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood. Consequently, many design decisions in this domain are made without proper justification or analysis. The high computational cost of training and evaluating such models, coupled with limited open research, hinders the development of video-LMMs. To address this, we present a comprehensive study that helps uncover what effectively drives video understanding in LMMs. We begin by critically examining the primary contributors to the high computational requirements associated with video-LMM research and discover Scaling Consistency, wherein design and training decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models. Leveraging these insights, we explored many video-specific aspects of video-LMMs, including video sampling, architectures, data composition, training schedules, and more. For example, we demonstrated that fps sampling during training is vastly preferable to uniform frame sampling and which vision encoders are the best for video representation. Guided by these findings, we introduce Apollo, a state-of-the-art family of LMMs that achieve superior performance across different model sizes. Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing $7$B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MME.
Video-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision
Jul 08, 2024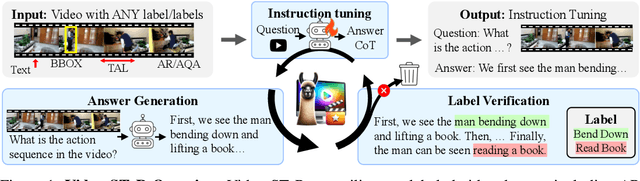



The performance of Large Vision Language Models (LVLMs) is dependent on the size and quality of their training datasets. Existing video instruction tuning datasets lack diversity as they are derived by prompting large language models with video captions to generate question-answer pairs, and are therefore mostly descriptive. Meanwhile, many labeled video datasets with diverse labels and supervision exist - however, we find that their integration into LVLMs is non-trivial. Herein, we present Video Self-Training with augmented Reasoning (Video-STaR), the first video self-training approach. Video-STaR allows the utilization of any labeled video dataset for video instruction tuning. In Video-STaR, an LVLM cycles between instruction generation and finetuning, which we show (I) improves general video understanding and (II) adapts LVLMs to novel downstream tasks with existing supervision. During generation, an LVLM is prompted to propose an answer. The answers are then filtered only to those that contain the original video labels, and the LVLM is then re-trained on the generated dataset. By only training on generated answers that contain the correct video labels, Video-STaR utilizes these existing video labels as weak supervision for video instruction tuning. Our results demonstrate that Video-STaR-enhanced LVLMs exhibit improved performance in (I) general video QA, where TempCompass performance improved by 10%, and (II) on downstream tasks, where Video-STaR improved Kinetics700-QA accuracy by 20% and action quality assessment on FineDiving by 15%.
VideoAgent: Long-form Video Understanding with Large Language Model as Agent
Mar 15, 2024Long-form video understanding represents a significant challenge within computer vision, demanding a model capable of reasoning over long multi-modal sequences. Motivated by the human cognitive process for long-form video understanding, we emphasize interactive reasoning and planning over the ability to process lengthy visual inputs. We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information. Evaluated on the challenging EgoSchema and NExT-QA benchmarks, VideoAgent achieves 54.1% and 71.3% zero-shot accuracy with only 8.4 and 8.2 frames used on average. These results demonstrate superior effectiveness and efficiency of our method over the current state-of-the-art methods, highlighting the potential of agent-based approaches in advancing long-form video understanding.
Open World Object Detection in the Era of Foundation Models
Dec 10, 2023Object detection is integral to a bevy of real-world applications, from robotics to medical image analysis. To be used reliably in such applications, models must be capable of handling unexpected - or novel - objects. The open world object detection (OWD) paradigm addresses this challenge by enabling models to detect unknown objects and learn discovered ones incrementally. However, OWD method development is hindered due to the stringent benchmark and task definitions. These definitions effectively prohibit foundation models. Here, we aim to relax these definitions and investigate the utilization of pre-trained foundation models in OWD. First, we show that existing benchmarks are insufficient in evaluating methods that utilize foundation models, as even naive integration methods nearly saturate these benchmarks. This result motivated us to curate a new and challenging benchmark for these models. Therefore, we introduce a new benchmark that includes five real-world application-driven datasets, including challenging domains such as aerial and surgical images, and establish baselines. We exploit the inherent connection between classes in application-driven datasets and introduce a novel method, Foundation Object detection Model for the Open world, or FOMO, which identifies unknown objects based on their shared attributes with the base known objects. FOMO has ~3x unknown object mAP compared to baselines on our benchmark. However, our results indicate a significant place for improvement - suggesting a great research opportunity in further scaling object detection methods to real-world domains. Our code and benchmark are available at https://orrzohar.github.io/projects/fomo/.
LOVM: Language-Only Vision Model Selection
Jun 15, 2023Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot settings. However, selecting the best-performing VLM for some downstream applications is non-trivial, as it is dataset and task-dependent. Meanwhile, the exhaustive evaluation of all available VLMs on a novel application is not only time and computationally demanding but also necessitates the collection of a labeled dataset for evaluation. As the number of open-source VLM variants increases, there is a need for an efficient model selection strategy that does not require access to a curated evaluation dataset. This paper proposes a novel task and benchmark for efficiently evaluating VLMs' zero-shot performance on downstream applications without access to the downstream task dataset. Specifically, we introduce a new task LOVM: Language-Only Vision Model Selection, where methods are expected to perform both model selection and performance prediction based solely on a text description of the desired downstream application. We then introduced an extensive LOVM benchmark consisting of ground-truth evaluations of 35 pre-trained VLMs and 23 datasets, where methods are expected to rank the pre-trained VLMs and predict their zero-shot performance.
PROB: Probabilistic Objectness for Open World Object Detection
Dec 02, 2022



Open World Object Detection (OWOD) is a new and challenging computer vision task that bridges the gap between classic object detection (OD) benchmarks and object detection in the real world. In addition to detecting and classifying seen/labeled objects, OWOD algorithms are expected to detect novel/unknown objects - which can be classified and incrementally learned. In standard OD, object proposals not overlapping with a labeled object are automatically classified as background. Therefore, simply applying OD methods to OWOD fails as unknown objects would be predicted as background. The challenge of detecting unknown objects stems from the lack of supervision in distinguishing unknown objects and background object proposals. Previous OWOD methods have attempted to overcome this issue by generating supervision using pseudo-labeling - however, unknown object detection has remained low. Probabilistic/generative models may provide a solution for this challenge. Herein, we introduce a novel probabilistic framework for objectness estimation, where we alternate between probability distribution estimation and objectness likelihood maximization of known objects in the embedded feature space - ultimately allowing us to estimate the objectness probability of different proposals. The resulting Probabilistic Objectness transformer-based open-world detector, PROB, integrates our framework into traditional object detection models, adapting them for the open-world setting. Comprehensive experiments on OWOD benchmarks show that PROB outperforms all existing OWOD methods in both unknown object detection ($\sim 2\times$ unknown recall) and known object detection ($\sim 10\%$ mAP). Our code will be made available upon publication at https://github.com/orrzohar/PROB.