 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision
Paper and Code
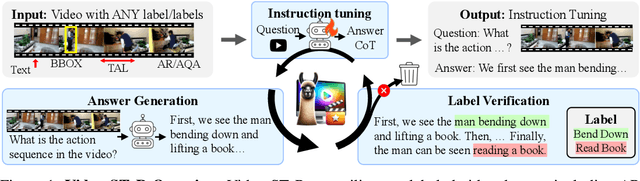



The performance of Large Vision Language Models (LVLMs) is dependent on the size and quality of their training datasets. Existing video instruction tuning datasets lack diversity as they are derived by prompting large language models with video captions to generate question-answer pairs, and are therefore mostly descriptive. Meanwhile, many labeled video datasets with diverse labels and supervision exist - however, we find that their integration into LVLMs is non-trivial. Herein, we present Video Self-Training with augmented Reasoning (Video-STaR), the first video self-training approach. Video-STaR allows the utilization of any labeled video dataset for video instruction tuning. In Video-STaR, an LVLM cycles between instruction generation and finetuning, which we show (I) improves general video understanding and (II) adapts LVLMs to novel downstream tasks with existing supervision. During generation, an LVLM is prompted to propose an answer. The answers are then filtered only to those that contain the original video labels, and the LVLM is then re-trained on the generated dataset. By only training on generated answers that contain the correct video labels, Video-STaR utilizes these existing video labels as weak supervision for video instruction tuning. Our results demonstrate that Video-STaR-enhanced LVLMs exhibit improved performance in (I) general video QA, where TempCompass performance improved by 10%, and (II) on downstream tasks, where Video-STaR improved Kinetics700-QA accuracy by 20% and action quality assessment on FineDiving by 15%.