 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
Feb 26, 2026Generative retrieval has emerged as a powerful paradigm for LLM-based recommendation. However, industrial recommender systems often benefit from restricting the output space to a constrained subset of items based on business logic (e.g. enforcing content freshness or product category), which standard autoregressive decoding cannot natively support. Moreover, existing constrained decoding methods that make use of prefix trees (Tries) incur severe latency penalties on hardware accelerators (TPUs/GPUs). In this work, we introduce STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding), an efficient and scalable constrained decoding technique designed specifically for high-throughput LLM-based generative retrieval on TPUs/GPUs. By flattening the prefix tree into a static Compressed Sparse Row (CSR) matrix, we transform irregular tree traversals into fully vectorized sparse matrix operations, unlocking massive efficiency gains on hardware accelerators. We deploy STATIC on a large-scale industrial video recommendation platform serving billions of users. STATIC produces significant product metric impact with minimal latency overhead (0.033 ms per step and 0.25% of inference time), achieving a 948x speedup over a CPU trie implementation and a 47-1033x speedup over a hardware-accelerated binary-search baseline. Furthermore, the runtime overhead of STATIC remains extremely low across a wide range of practical configurations. To the best of our knowledge, STATIC enables the first production-scale deployment of strictly constrained generative retrieval. In addition, evaluation on academic benchmarks demonstrates that STATIC can considerably improve cold-start performance for generative retrieval. Our code is available at https://github.com/youtube/static-constraint-decoding.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
Online Matching: A Real-time Bandit System for Large-scale Recommendations
Jul 29, 2023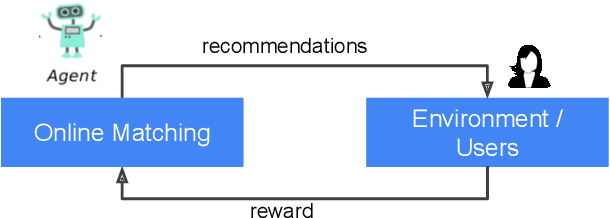


The last decade has witnessed many successes of deep learning-based models for industry-scale recommender systems. These models are typically trained offline in a batch manner. While being effective in capturing users' past interactions with recommendation platforms, batch learning suffers from long model-update latency and is vulnerable to system biases, making it hard to adapt to distribution shift and explore new items or user interests. Although online learning-based approaches (e.g., multi-armed bandits) have demonstrated promising theoretical results in tackling these challenges, their practical real-time implementation in large-scale recommender systems remains limited. First, the scalability of online approaches in servicing a massive online traffic while ensuring timely updates of bandit parameters poses a significant challenge. Additionally, exploring uncertainty in recommender systems can easily result in unfavorable user experience, highlighting the need for devising intricate strategies that effectively balance the trade-off between exploitation and exploration. In this paper, we introduce Online Matching: a scalable closed-loop bandit system learning from users' direct feedback on items in real time. We present a hybrid "offline + online" approach for constructing this system, accompanied by a comprehensive exposition of the end-to-end system architecture. We propose Diag-LinUCB -- a novel extension of the LinUCB algorithm -- to enable distributed updates of bandits parameter in a scalable and timely manner. We conduct live experiments in YouTube and show that Online Matching is able to enhance the capabilities of fresh content discovery and item exploration in the present platform.
Deep Partial Multiplex Network Embedding
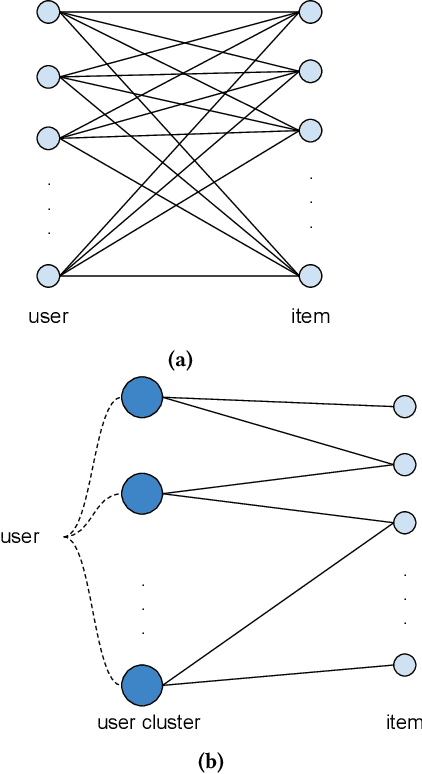
Mar 05, 2022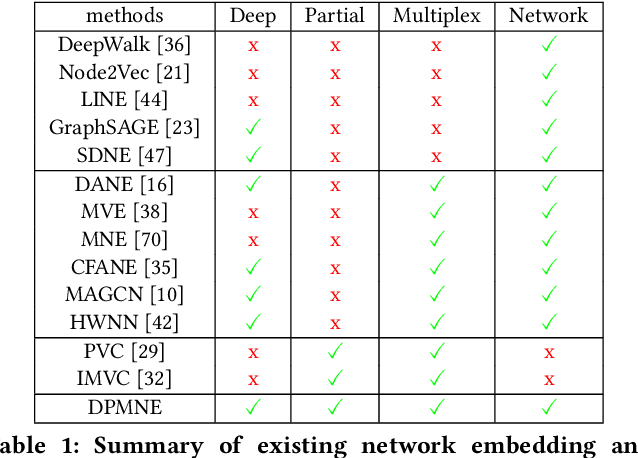
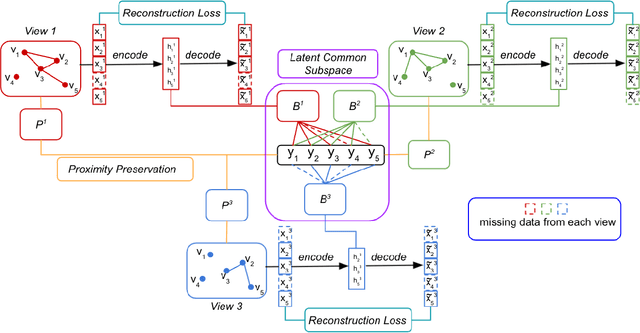
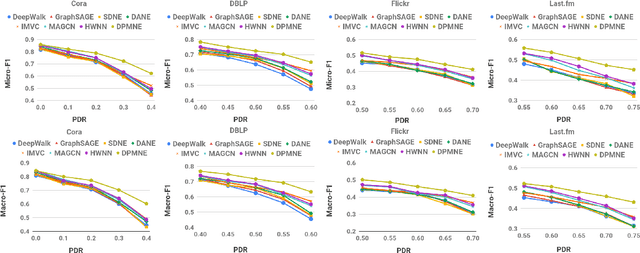
Network embedding is an effective technique to learn the low-dimensional representations of nodes in networks. Real-world networks are usually with multiplex or having multi-view representations from different relations. Recently, there has been increasing interest in network embedding on multiplex data. However, most existing multiplex approaches assume that the data is complete in all views. But in real applications, it is often the case that each view suffers from the missing of some data and therefore results in partial multiplex data. In this paper, we present a novel Deep Partial Multiplex Network Embedding approach to deal with incomplete data. In particular, the network embeddings are learned by simultaneously minimizing the deep reconstruction loss with the autoencoder neural network, enforcing the data consistency across views via common latent subspace learning, and preserving the data topological structure within the same network through graph Laplacian. We further prove the orthogonal invariant property of the learned embeddings and connect our approach with the binary embedding techniques. Experiments on four multiplex benchmarks demonstrate the superior performance of the proposed approach over several state-of-the-art methods on node classification, link prediction and clustering tasks.
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

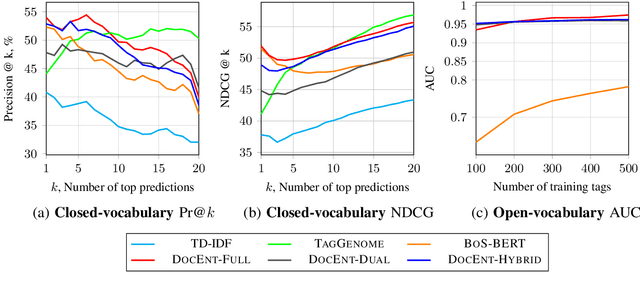
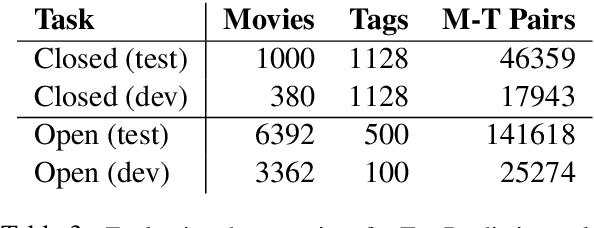
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.
RealFormer: Transformer Likes Residual Attention
Dec 23, 2020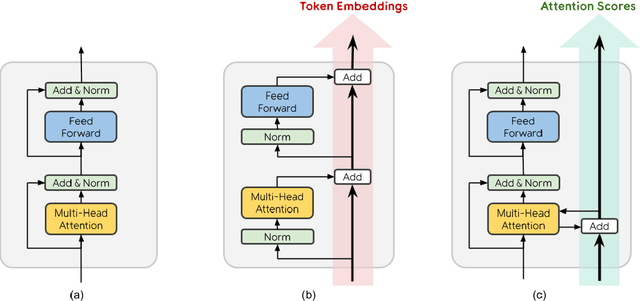
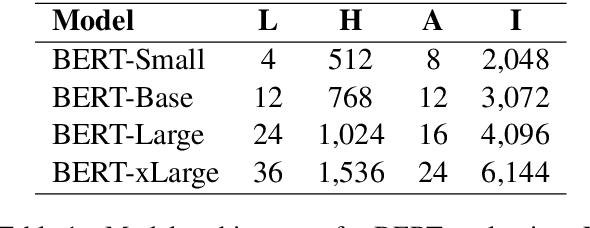
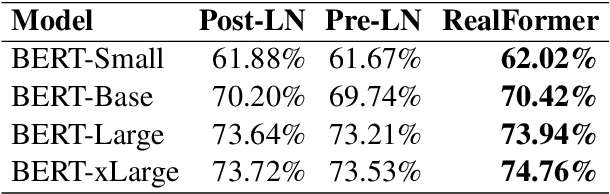
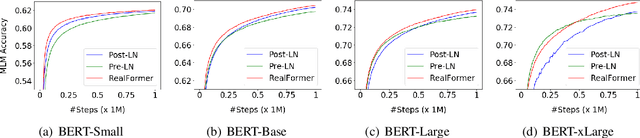
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple Residual Attention Layer Transformer architecture that significantly outperforms canonical Transformers on a spectrum of tasks including Masked Language Modeling, GLUE, and SQuAD. Qualitatively, RealFormer is easy to implement and requires minimal hyper-parameter tuning. It also stabilizes training and leads to models with sparser attentions. Code will be open-sourced upon paper acceptance.
Graph Convolutional Neural Networks for Web-Scale Recommender Systems
Jun 06, 2018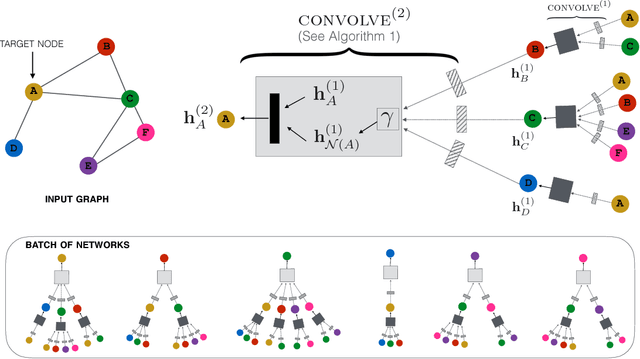


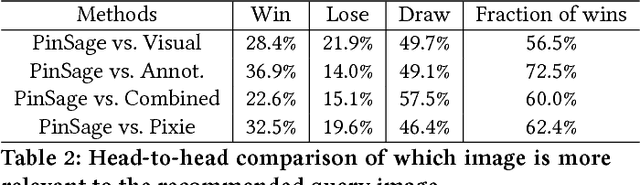
Recent advancements in deep neural networks for graph-structured data have led to state-of-the-art performance on recommender system benchmarks. However, making these methods practical and scalable to web-scale recommendation tasks with billions of items and hundreds of millions of users remains a challenge. Here we describe a large-scale deep recommendation engine that we developed and deployed at Pinterest. We develop a data-efficient Graph Convolutional Network (GCN) algorithm PinSage, which combines efficient random walks and graph convolutions to generate embeddings of nodes (i.e., items) that incorporate both graph structure as well as node feature information. Compared to prior GCN approaches, we develop a novel method based on highly efficient random walks to structure the convolutions and design a novel training strategy that relies on harder-and-harder training examples to improve robustness and convergence of the model. We also develop an efficient MapReduce model inference algorithm to generate embeddings using a trained model. We deploy PinSage at Pinterest and train it on 7.5 billion examples on a graph with 3 billion nodes representing pins and boards, and 18 billion edges. According to offline metrics, user studies and A/B tests, PinSage generates higher-quality recommendations than comparable deep learning and graph-based alternatives. To our knowledge, this is the largest application of deep graph embeddings to date and paves the way for a new generation of web-scale recommender systems based on graph convolutional architectures.
Learning Compatibility Across Categories for Heterogeneous Item Recommendation
Sep 29, 2016

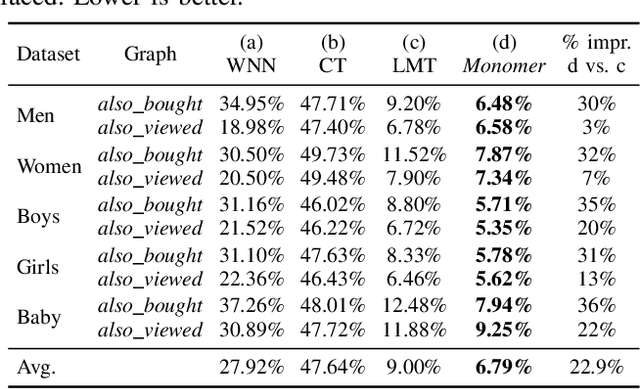
Identifying relationships between items is a key task of an online recommender system, in order to help users discover items that are functionally complementary or visually compatible. In domains like clothing recommendation, this task is particularly challenging since a successful system should be capable of handling a large corpus of items, a huge amount of relationships among them, as well as the high-dimensional and semantically complicated features involved. Furthermore, the human notion of "compatibility" to capture goes beyond mere similarity: For two items to be compatible---whether jeans and a t-shirt, or a laptop and a charger---they should be similar in some ways, but systematically different in others. In this paper we propose a novel method, Monomer, to learn complicated and heterogeneous relationships between items in product recommendation settings. Recently, scalable methods have been developed that address this task by learning similarity metrics on top of the content of the products involved. Here our method relaxes the metricity assumption inherent in previous work and models multiple localized notions of 'relatedness,' so as to uncover ways in which related items should be systematically similar, and systematically different. Quantitatively, we show that our system achieves state-of-the-art performance on large-scale compatibility prediction tasks, especially in cases where there is substantial heterogeneity between related items. Qualitatively, we demonstrate that richer notions of compatibility can be learned that go beyond similarity, and that our model can make effective recommendations of heterogeneous content.
Vista: A Visually, Socially, and Temporally-aware Model for Artistic Recommendation
Jul 15, 2016
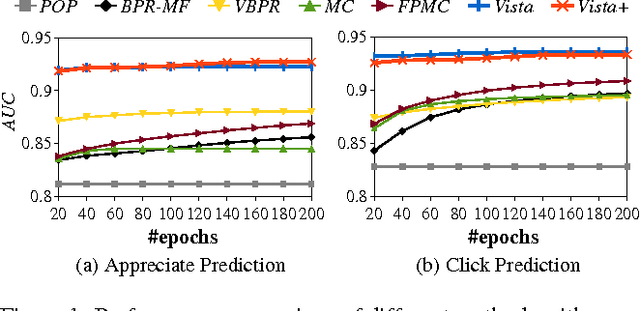


Understanding users' interactions with highly subjective content---like artistic images---is challenging due to the complex semantics that guide our preferences. On the one hand one has to overcome `standard' recommender systems challenges, such as dealing with large, sparse, and long-tailed datasets. On the other, several new challenges present themselves, such as the need to model content in terms of its visual appearance, or even social dynamics, such as a preference toward a particular artist that is independent of the art they create. In this paper we build large-scale recommender systems to model the dynamics of a vibrant digital art community, Behance, consisting of tens of millions of interactions (clicks and `appreciates') of users toward digital art. Methodologically, our main contributions are to model (a) rich content, especially in terms of its visual appearance; (b) temporal dynamics, in terms of how users prefer `visually consistent' content within and across sessions; and (c) social dynamics, in terms of how users exhibit preferences both towards certain art styles, as well as the artists themselves.
Sherlock: Sparse Hierarchical Embeddings for Visually-aware One-class Collaborative Filtering
Apr 20, 2016

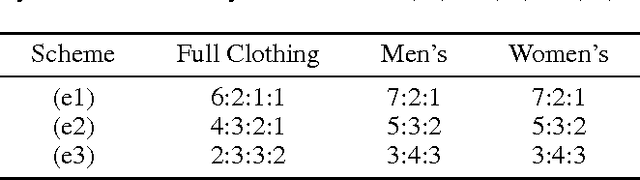
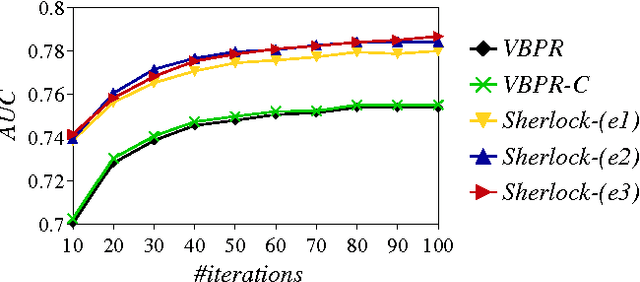
Building successful recommender systems requires uncovering the underlying dimensions that describe the properties of items as well as users' preferences toward them. In domains like clothing recommendation, explaining users' preferences requires modeling the visual appearance of the items in question. This makes recommendation especially challenging, due to both the complexity and subtlety of people's 'visual preferences,' as well as the scale and dimensionality of the data and features involved. Ultimately, a successful model should be capable of capturing considerable variance across different categories and styles, while still modeling the commonalities explained by `global' structures in order to combat the sparsity (e.g. cold-start), variability, and scale of real-world datasets. Here, we address these challenges by building such structures to model the visual dimensions across different product categories. With a novel hierarchical embedding architecture, our method accounts for both high-level (colorfulness, darkness, etc.) and subtle (e.g. casualness) visual characteristics simultaneously.