Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealFormer: Transformer Likes Residual Attention
Paper and Code
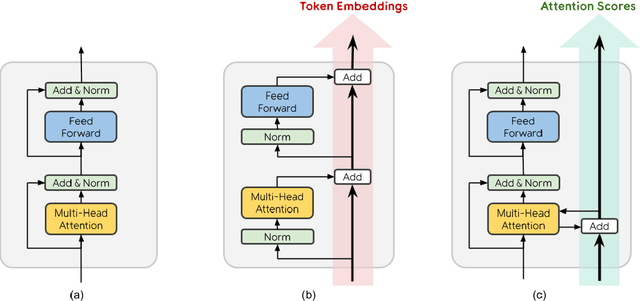
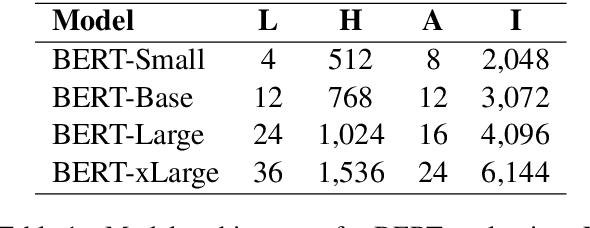
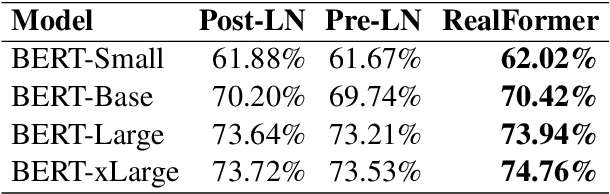
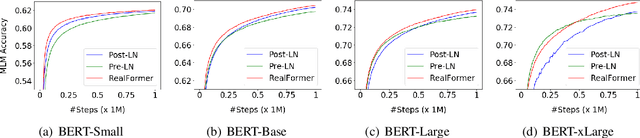
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple Residual Attention Layer Transformer architecture that significantly outperforms canonical Transformers on a spectrum of tasks including Masked Language Modeling, GLUE, and SQuAD. Qualitatively, RealFormer is easy to implement and requires minimal hyper-parameter tuning. It also stabilizes training and leads to models with sparser attentions. Code will be open-sourced upon paper acceptance.
* 13 pages, 8 figures
View paper on