 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopTalk: A System for Conversational Faceted Search
Sep 02, 2021


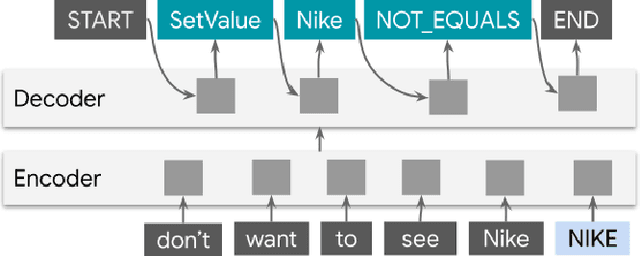
We present ShopTalk, a multi-turn conversational faceted search system for shopping that is designed to handle large and complex schemas that are beyond the scope of state of the art slot-filling systems. ShopTalk decouples dialog management from fulfillment, thereby allowing the dialog understanding system to be domain-agnostic and not tied to the particular shopping application. The dialog understanding system consists of a deep-learned Contextual Language Understanding module, which interprets user utterances, and a primarily rules-based Dialog-State Tracker (DST), which updates the dialog state and formulates search requests intended for the fulfillment engine. The interface between the two modules consists of a minimal set of domain-agnostic "intent operators," which instruct the DST on how to update the dialog state. ShopTalk was deployed in 2020 on the Google Assistant for Shopping searches.
ReadTwice: Reading Very Large Documents with Memories
May 11, 2021

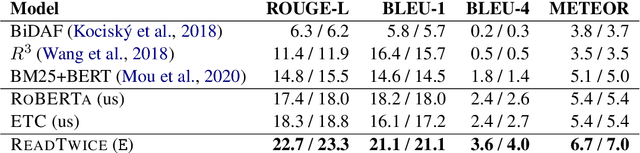
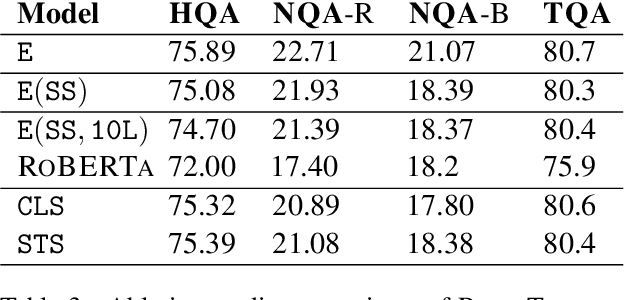
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.
FNet: Mixing Tokens with Fourier Transforms
May 09, 2021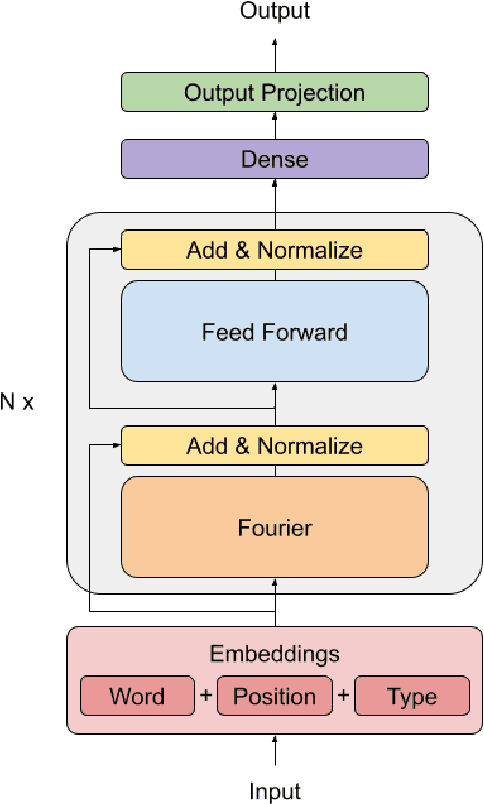

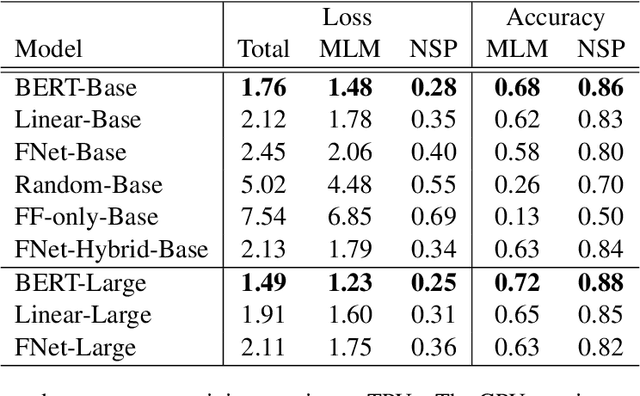
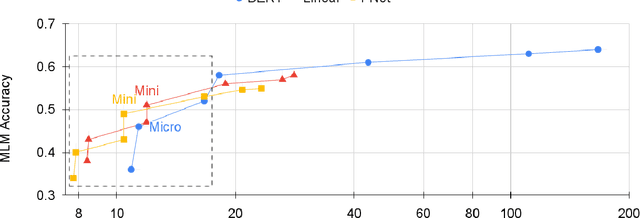
We show that Transformer encoder architectures can be massively sped up, with limited accuracy costs, by replacing the self-attention sublayers with simple linear transformations that "mix" input tokens. These linear transformations, along with simple nonlinearities in feed-forward layers, are sufficient to model semantic relationships in several text classification tasks. Perhaps most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder with a standard, unparameterized Fourier Transform achieves 92% of the accuracy of BERT on the GLUE benchmark, but pre-trains and runs up to seven times faster on GPUs and twice as fast on TPUs. The resulting model, which we name FNet, scales very efficiently to long inputs, matching the accuracy of the most accurate "efficient" Transformers on the Long Range Arena benchmark, but training and running faster across all sequence lengths on GPUs and relatively shorter sequence lengths on TPUs. Finally, FNet has a light memory footprint and is particularly efficient at smaller model sizes: for a fixed speed and accuracy budget, small FNet models outperform Transformer counterparts.
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

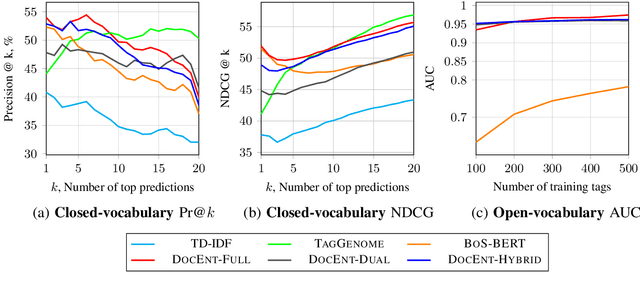
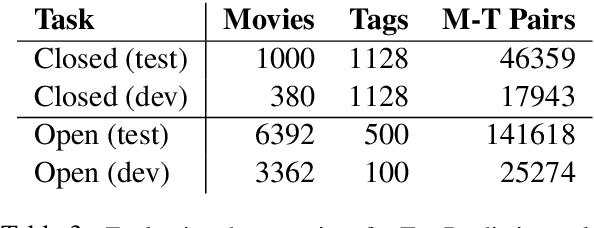
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.