 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReadTwice: Reading Very Large Documents with Memories
Paper and Code


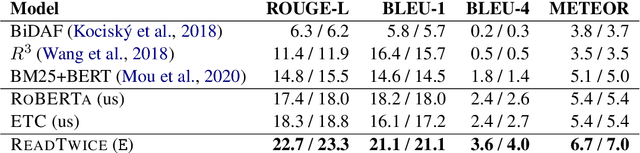
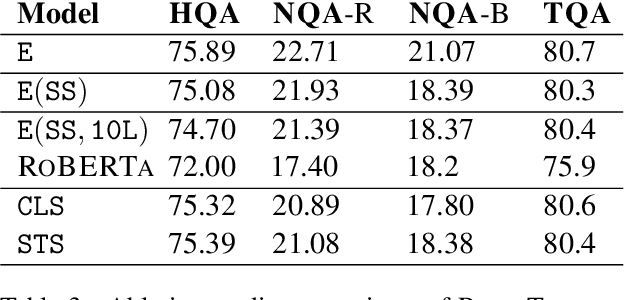
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.