 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLM Reasoning Enhances Personalized Recommender Systems
Jul 22, 2024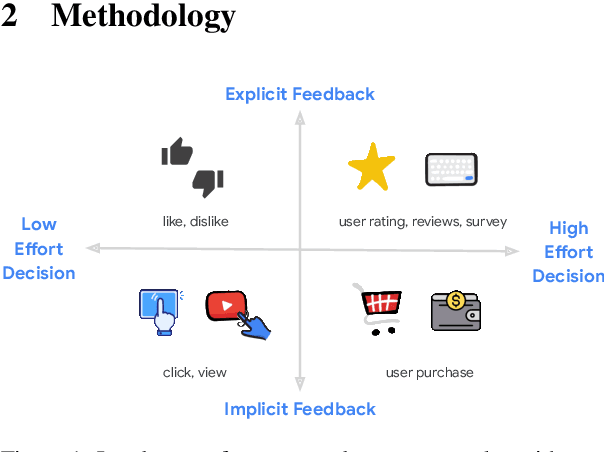



Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.
Hierarchical Target-Attentive Diagnosis Prediction in Heterogeneous Information Networks
Dec 22, 2019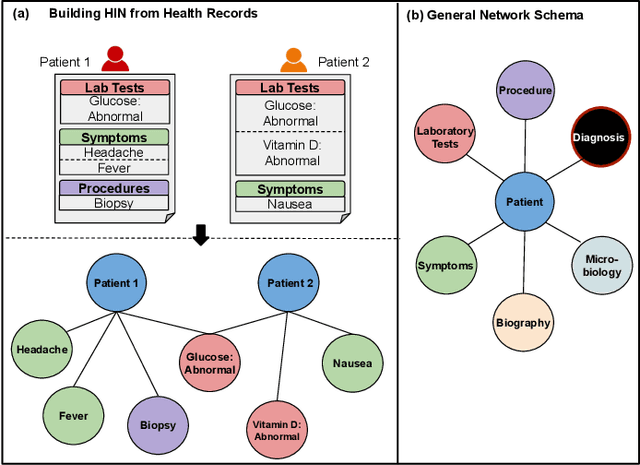
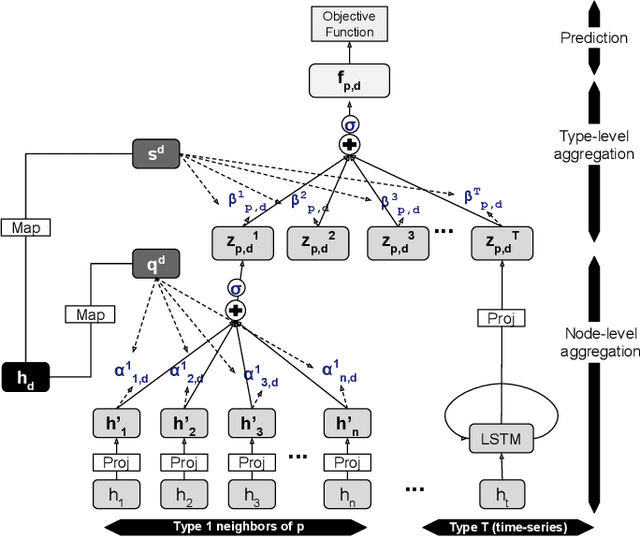
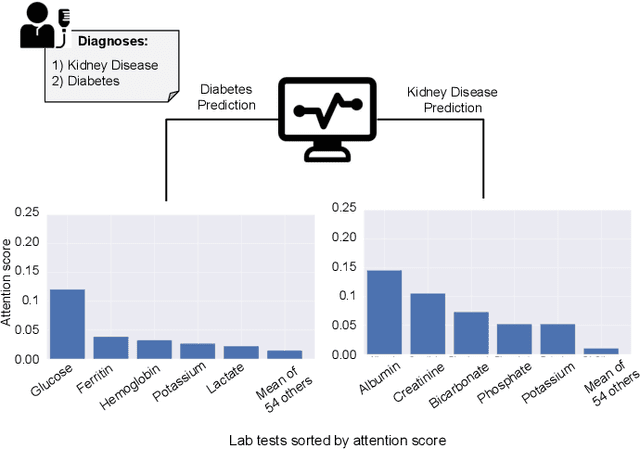

We introduce HTAD, a novel model for diagnosis prediction using Electronic Health Records (EHR) represented as Heterogeneous Information Networks. Recent studies on modeling EHR have shown success in automatically learning representations of the clinical records in order to avoid the need for manual feature selection. However, these representations are often learned and aggregated without specificity for the different possible targets being predicted. Our model introduces a target-aware hierarchical attention mechanism that allows it to learn to attend to the most important clinical records when aggregating their representations for prediction of a diagnosis. We evaluate our model using a publicly available benchmark dataset and demonstrate that the use of target-aware attention significantly improves performance compared to the current state of the art. Additionally, we propose a method for incorporating non-categorical data into our predictions and demonstrate that this technique leads to further performance improvements. Lastly, we demonstrate that the predictions made by our proposed model are easily interpretable.
Unsupervised Prediction of Negative Health Events Ahead of Time
Jan 31, 2019


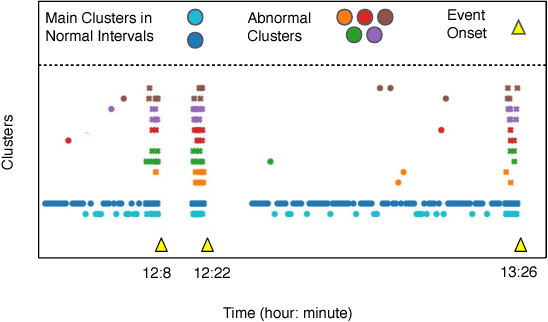
The emergence of continuous health monitoring and the availability of an enormous amount of time series data has provided a great opportunity for the advancement of personal health tracking. In recent years, unsupervised learning methods have drawn special attention of researchers to tackle the sparse annotation of health data and real-time detection of anomalies has been a central problem of interest. However, one problem that has not been well addressed before is the early prediction of forthcoming negative health events. Early signs of an event can introduce subtle and gradual changes in the health signal prior to its onset, detection of which can be invaluable in effective prevention. In this study, we first demonstrate our observations on the shortcoming of widely adopted anomaly detection methods in uncovering the changes prior to a negative health event. We then propose a framework which relies on online clustering of signal segment representations which are automatically learned by a specially designed LSTM auto-encoder. We show the effectiveness of our approach by predicting Bradycardia events in infants using MIT-PICS dataset 1.3 minutes ahead of time with 68\% AUC score on average, using no label supervision. Results of our study can indicate the viability of our approach in the early detection of health events in other applications as well.
HeteroMed: Heterogeneous Information Network for Medical Diagnosis
Apr 22, 2018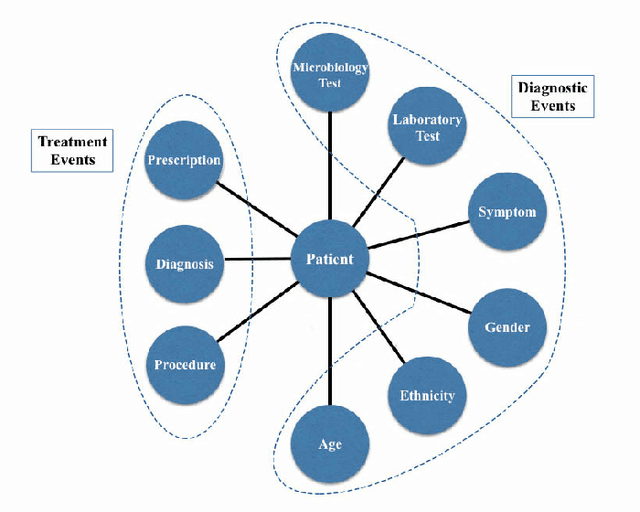

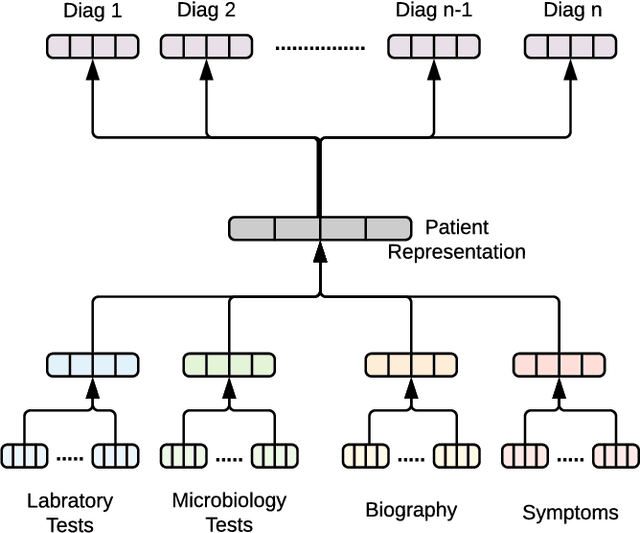

With the recent availability of Electronic Health Records (EHR) and great opportunities they offer for advancing medical informatics, there has been growing interest in mining EHR for improving quality of care. Disease diagnosis due to its sensitive nature, huge costs of error, and complexity has become an increasingly important focus of research in past years. Existing studies model EHR by capturing co-occurrence of clinical events to learn their latent embeddings. However, relations among clinical events carry various semantics and contribute differently to disease diagnosis which gives precedence to a more advanced modeling of heterogeneous data types and relations in EHR data than existing solutions. To address these issues, we represent how high-dimensional EHR data and its rich relationships can be suitably translated into HeteroMed, a heterogeneous information network for robust medical diagnosis. Our modeling approach allows for straightforward handling of missing values and heterogeneity of data. HeteroMed exploits metapaths to capture higher level and semantically important relations contributing to disease diagnosis. Furthermore, it employs a joint embedding framework to tailor clinical event representations to the disease diagnosis goal. To the best of our knowledge, this is the first study to use Heterogeneous Information Network for modeling clinical data and disease diagnosis. Experimental results of our study show superior performance of HeteroMed compared to prior methods in prediction of exact diagnosis codes and general disease cohorts. Moreover, HeteroMed outperforms baseline models in capturing similarities of clinical events which are examined qualitatively through case studies.