 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLM Reasoning Enhances Personalized Recommender Systems
Jul 22, 2024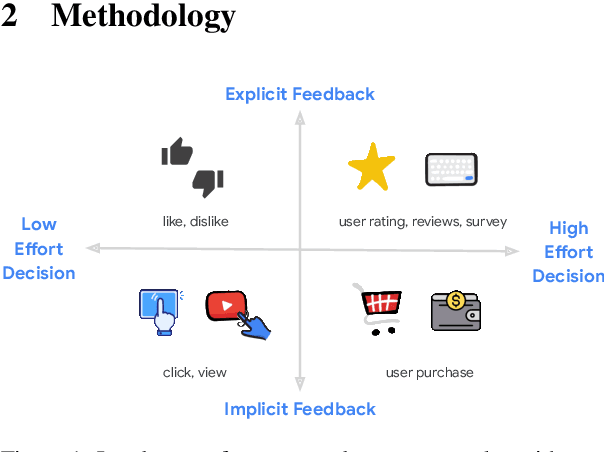



Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.
The Extrapolation Power of Implicit Models
Jul 19, 2024

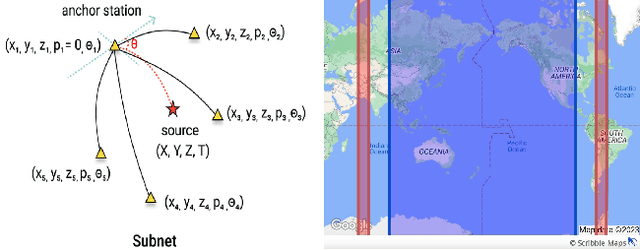
In this paper, we investigate the extrapolation capabilities of implicit deep learning models in handling unobserved data, where traditional deep neural networks may falter. Implicit models, distinguished by their adaptability in layer depth and incorporation of feedback within their computational graph, are put to the test across various extrapolation scenarios: out-of-distribution, geographical, and temporal shifts. Our experiments consistently demonstrate significant performance advantage with implicit models. Unlike their non-implicit counterparts, which often rely on meticulous architectural design for each task, implicit models demonstrate the ability to learn complex model structures without the need for task-specific design, highlighting their robustness in handling unseen data.
State-driven Implicit Modeling for Sparsity and Robustness in Neural Networks
Sep 19, 2022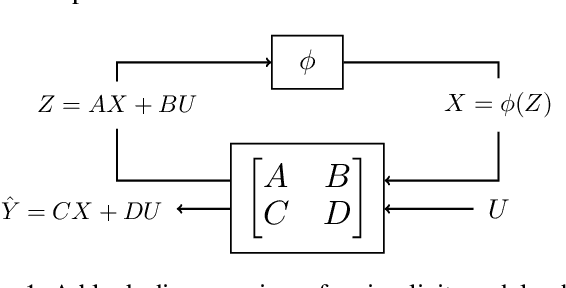
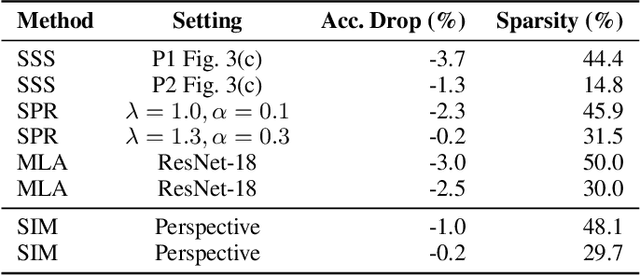
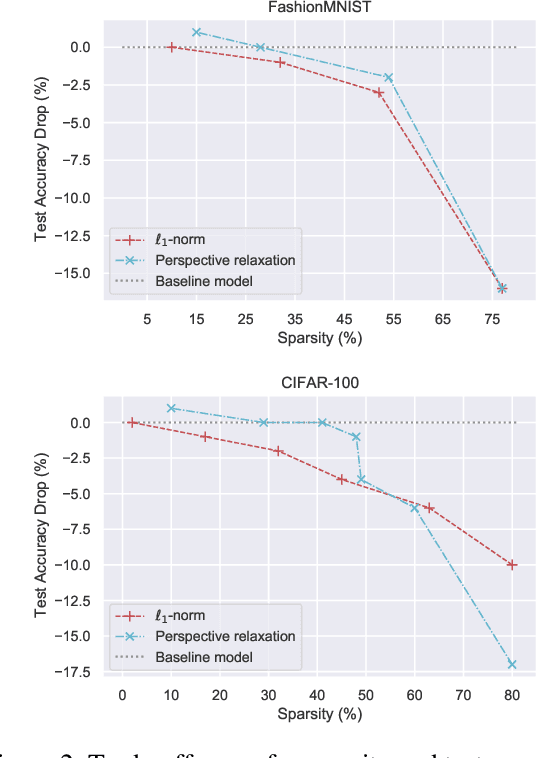
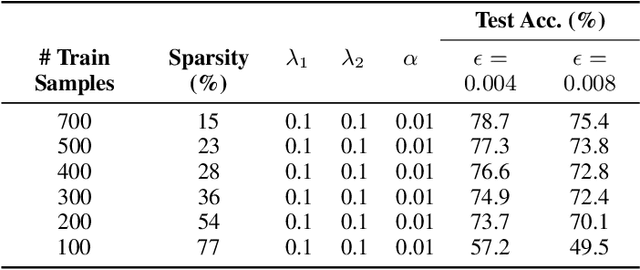
Implicit models are a general class of learning models that forgo the hierarchical layer structure typical in neural networks and instead define the internal states based on an ``equilibrium'' equation, offering competitive performance and reduced memory consumption. However, training such models usually relies on expensive implicit differentiation for backward propagation. In this work, we present a new approach to training implicit models, called State-driven Implicit Modeling (SIM), where we constrain the internal states and outputs to match that of a baseline model, circumventing costly backward computations. The training problem becomes convex by construction and can be solved in a parallel fashion, thanks to its decomposable structure. We demonstrate how the SIM approach can be applied to significantly improve sparsity (parameter reduction) and robustness of baseline models trained on FashionMNIST and CIFAR-100 datasets.
Sparse Optimization for Unsupervised Extractive Summarization of Long Documents with the Frank-Wolfe Algorithm
Aug 19, 2022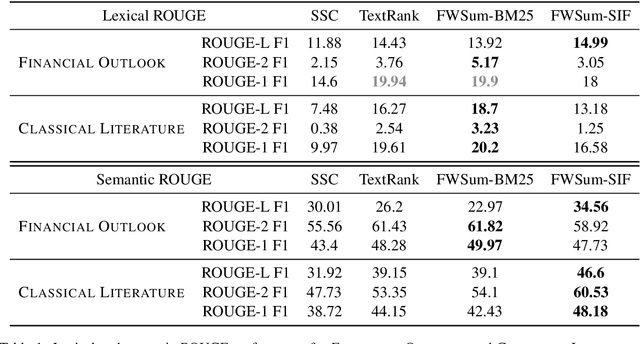
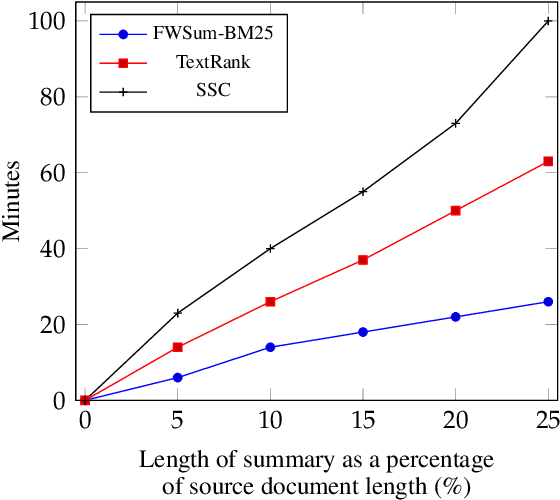
We address the problem of unsupervised extractive document summarization, especially for long documents. We model the unsupervised problem as a sparse auto-regression one and approximate the resulting combinatorial problem via a convex, norm-constrained problem. We solve it using a dedicated Frank-Wolfe algorithm. To generate a summary with $k$ sentences, the algorithm only needs to execute $\approx k$ iterations, making it very efficient. We explain how to avoid explicit calculation of the full gradient and how to include sentence embedding information. We evaluate our approach against two other unsupervised methods using both lexical (standard) ROUGE scores, as well as semantic (embedding-based) ones. Our method achieves better results with both datasets and works especially well when combined with embeddings for highly paraphrased summaries.
Style Control for Schema-Guided Natural Language Generation
Sep 24, 2021

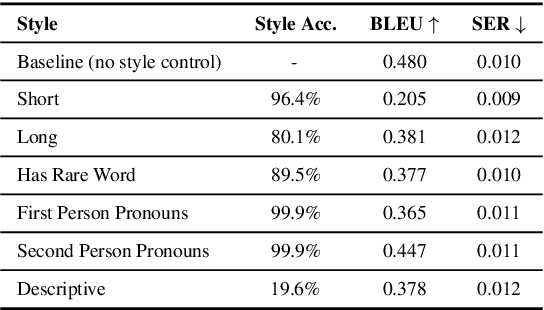

Natural Language Generation (NLG) for task-oriented dialogue systems focuses on communicating specific content accurately, fluently, and coherently. While these attributes are crucial for a successful dialogue, it is also desirable to simultaneously accomplish specific stylistic goals, such as response length, point-of-view, descriptiveness, sentiment, formality, and empathy. In this work, we focus on stylistic control and evaluation for schema-guided NLG, with joint goals of achieving both semantic and stylistic control. We experiment in detail with various controlled generation methods for large pretrained language models: specifically, conditional training, guided fine-tuning, and guided decoding. We discuss their advantages and limitations, and evaluate them with a broad range of automatic and human evaluation metrics. Our results show that while high style accuracy and semantic correctness are easier to achieve for more lexically-defined styles with conditional training, stylistic control is also achievable for more semantically complex styles using discriminator-based guided decoding methods. The results also suggest that methods that are more scalable (with less hyper-parameters tuning) and that disentangle content generation and stylistic variations are more effective at achieving semantic correctness and style accuracy.
Text Analytics for Resilience-Enabled Extreme EventsReconnaissance
Nov 26, 2020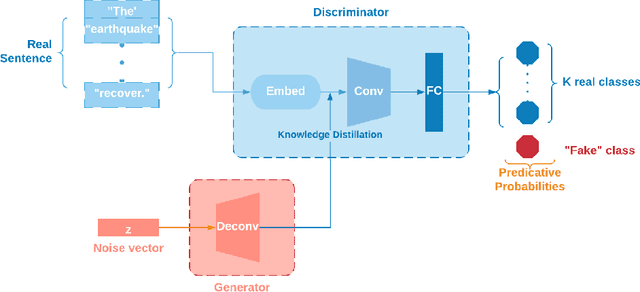
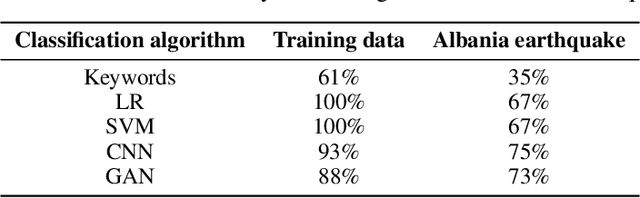
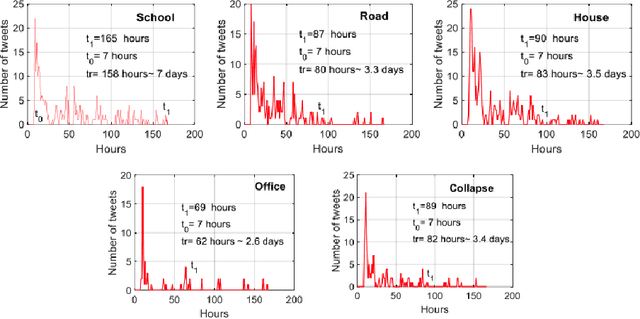

Post-hazard reconnaissance for natural disasters (e.g., earthquakes) is important for understanding the performance of the built environment, speeding up the recovery, enhancing resilience and making informed decisions related to current and future hazards. Natural language processing (NLP) is used in this study for the purposes of increasing the accuracy and efficiency of natural hazard reconnaissance through automation. The study particularly focuses on (1) automated data (news and social media) collection hosted by the Pacific Earthquake Engineering Research (PEER) Center server, (2) automatic generation of reconnaissance reports, and (3) use of social media to extract post-hazard information such as the recovery time. Obtained results are encouraging for further development and wider usage of various NLP methods in natural hazard reconnaissance.