 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Semi-Supervised Generative Adversarial Network for Damage Assessment from Low-Data Imbalanced-Class Regime
Nov 29, 2022In recent years, applying deep learning (DL) to assess structural damages has gained growing popularity in vision-based structural health monitoring (SHM). However, both data deficiency and class-imbalance hinder the wide adoption of DL in practical applications of SHM. Common mitigation strategies include transfer learning, over-sampling, and under-sampling, yet these ad-hoc methods only provide limited performance boost that varies from one case to another. In this work, we introduce one variant of the Generative Adversarial Network (GAN), named the balanced semi-supervised GAN (BSS-GAN). It adopts the semi-supervised learning concept and applies balanced-batch sampling in training to resolve low-data and imbalanced-class problems. A series of computer experiments on concrete cracking and spalling classification were conducted under the low-data imbalanced-class regime with limited computing power. The results show that the BSS-GAN is able to achieve better damage detection in terms of recall and $F_\beta$ score than other conventional methods, indicating its state-of-the-art performance.
Sample-efficient Quantum Born Machine through Coding Rate Reduction
Nov 14, 2022The quantum circuit Born machine (QCBM) is a quantum physics inspired implicit generative model naturally suitable for learning binary images, with a potential advantage of modeling discrete distributions that are hard to simulate classically. As data samples are generated quantum-mechanically, QCBMs encompass a unique optimization landscape. However, pioneering works on QCBMs do not consider the practical scenario where only small batch sizes are allowed during training. QCBMs trained with a statistical two-sample test objective in the image space require large amounts of projective measurements to approximate the model distribution well, unpractical for large-scale quantum systems due to the exponential scaling of the probability space. QCBMs trained adversarially against a deep neural network discriminator are proof-of-concept models that face mode collapse. In this work we investigate practical learning of QCBMs. We use the information-theoretic \textit{Maximal Coding Rate Reduction} (MCR$^2$) metric as a second moment matching tool and study its effect on mode collapse in QCBMs. We compute the sampling based gradient of MCR$^2$ with respect to quantum circuit parameters with or without an explicit feature mapping. We experimentally show that matching up to the second moment alone is not sufficient for training the quantum generator, but when combined with the class probability estimation loss, MCR$^2$ is able to resist mode collapse. In addition, we show that adversarially trained neural network kernel for infinite moment matching is also effective against mode collapse. On the Bars and Stripes dataset, our proposed techniques alleviate mode collapse to a larger degree than previous QCBM training schemes, moving one step closer towards practicality and scalability.
Revisiting Sparse Convolutional Model for Visual Recognition
Oct 24, 2022



Despite strong empirical performance for image classification, deep neural networks are often regarded as ``black boxes'' and they are difficult to interpret. On the other hand, sparse convolutional models, which assume that a signal can be expressed by a linear combination of a few elements from a convolutional dictionary, are powerful tools for analyzing natural images with good theoretical interpretability and biological plausibility. However, such principled models have not demonstrated competitive performance when compared with empirically designed deep networks. This paper revisits the sparse convolutional modeling for image classification and bridges the gap between good empirical performance (of deep learning) and good interpretability (of sparse convolutional models). Our method uses differentiable optimization layers that are defined from convolutional sparse coding as drop-in replacements of standard convolutional layers in conventional deep neural networks. We show that such models have equally strong empirical performance on CIFAR-10, CIFAR-100, and ImageNet datasets when compared to conventional neural networks. By leveraging stable recovery property of sparse modeling, we further show that such models can be much more robust to input corruptions as well as adversarial perturbations in testing through a simple proper trade-off between sparse regularization and data reconstruction terms. Source code can be found at https://github.com/Delay-Xili/SDNet.
Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction
Nov 12, 2021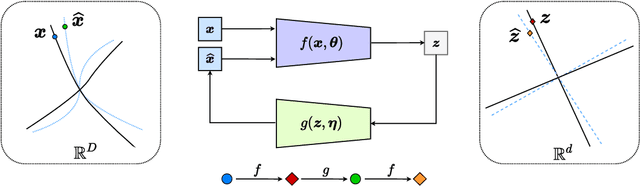
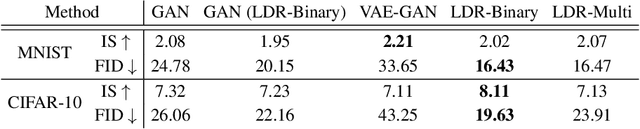
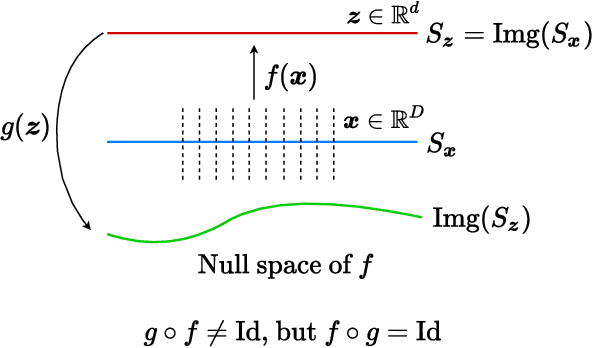
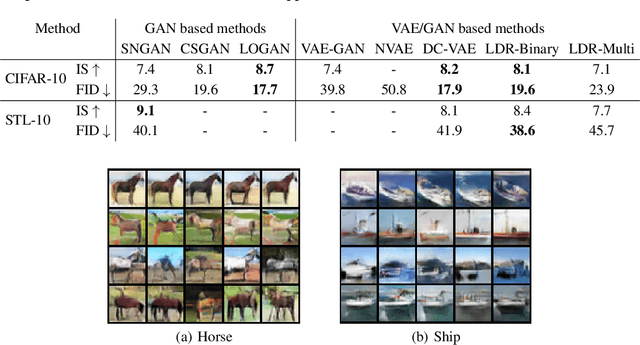
This work proposes a new computational framework for learning an explicit generative model for real-world datasets. In particular we propose to learn {\em a closed-loop transcription} between a multi-class multi-dimensional data distribution and a { linear discriminative representation (LDR)} in the feature space that consists of multiple independent multi-dimensional linear subspaces. In particular, we argue that the optimal encoding and decoding mappings sought can be formulated as the equilibrium point of a {\em two-player minimax game between the encoder and decoder}. A natural utility function for this game is the so-called {\em rate reduction}, a simple information-theoretic measure for distances between mixtures of subspace-like Gaussians in the feature space. Our formulation draws inspiration from closed-loop error feedback from control systems and avoids expensive evaluating and minimizing approximated distances between arbitrary distributions in either the data space or the feature space. To a large extent, this new formulation unifies the concepts and benefits of Auto-Encoding and GAN and naturally extends them to the settings of learning a {\em both discriminative and generative} representation for multi-class and multi-dimensional real-world data. Our extensive experiments on many benchmark imagery datasets demonstrate tremendous potential of this new closed-loop formulation: under fair comparison, visual quality of the learned decoder and classification performance of the encoder is competitive and often better than existing methods based on GAN, VAE, or a combination of both. We notice that the so learned features of different classes are explicitly mapped onto approximately {\em independent principal subspaces} in the feature space; and diverse visual attributes within each class are modeled by the {\em independent principal components} within each subspace.
Text Analytics for Resilience-Enabled Extreme EventsReconnaissance
Nov 26, 2020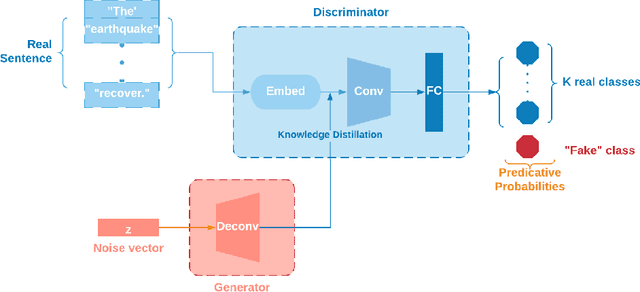
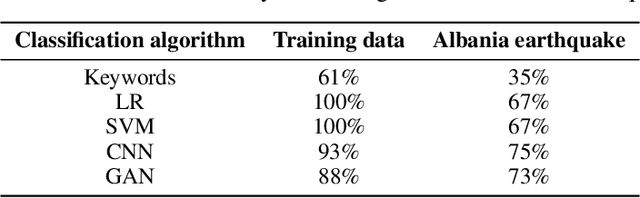
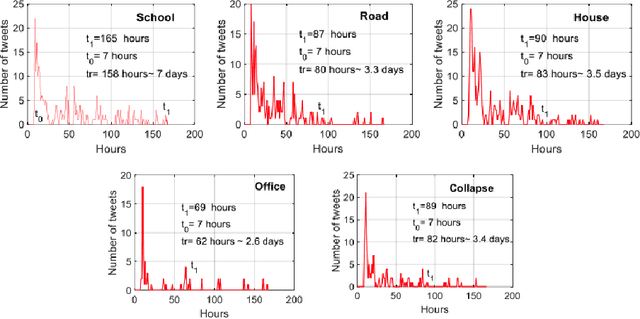

Post-hazard reconnaissance for natural disasters (e.g., earthquakes) is important for understanding the performance of the built environment, speeding up the recovery, enhancing resilience and making informed decisions related to current and future hazards. Natural language processing (NLP) is used in this study for the purposes of increasing the accuracy and efficiency of natural hazard reconnaissance through automation. The study particularly focuses on (1) automated data (news and social media) collection hosted by the Pacific Earthquake Engineering Research (PEER) Center server, (2) automatic generation of reconnaissance reports, and (3) use of social media to extract post-hazard information such as the recovery time. Obtained results are encouraging for further development and wider usage of various NLP methods in natural hazard reconnaissance.