 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Calibration in Deep Metric Learning With Cross-Example Softmax
Paper and Code
Nov 17, 2020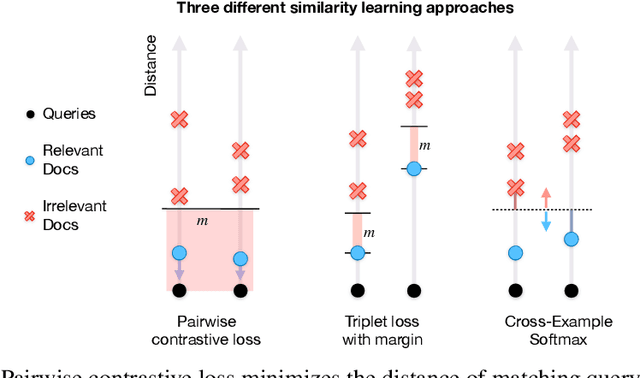
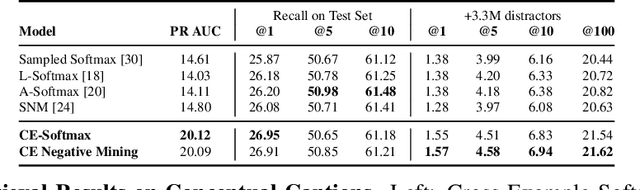
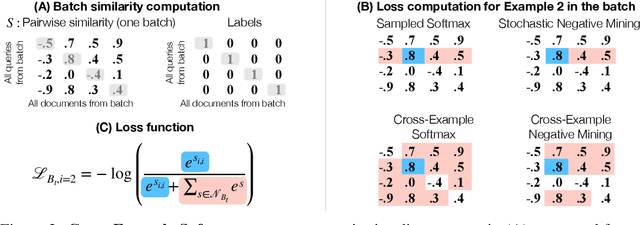
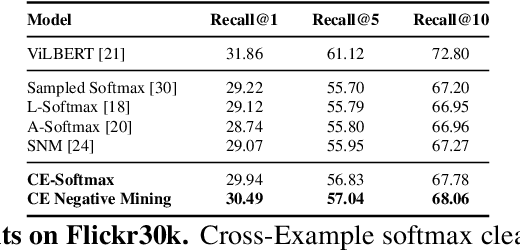
Modern image retrieval systems increasingly rely on the use of deep neural networks to learn embedding spaces in which distance encodes the relevance between a given query and image. In this setting, existing approaches tend to emphasize one of two properties. Triplet-based methods capture top-$k$ relevancy, where all top-$k$ scoring documents are assumed to be relevant to a given query Pairwise contrastive models capture threshold relevancy, where all documents scoring higher than some threshold are assumed to be relevant. In this paper, we propose Cross-Example Softmax which combines the properties of top-$k$ and threshold relevancy. In each iteration, the proposed loss encourages all queries to be closer to their matching images than all queries are to all non-matching images. This leads to a globally more calibrated similarity metric and makes distance more interpretable as an absolute measure of relevance. We further introduce Cross-Example Negative Mining, in which each pair is compared to the hardest negative comparisons across the entire batch. Empirically, we show in a series of experiments on Conceptual Captions and Flickr30k, that the proposed method effectively improves global calibration and also retrieval performance.