 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and accurate steering of Large Language Models through attention-guided feature learning
Jan 30, 2026Steering, or direct manipulation of internal activations to guide LLM responses toward specific semantic concepts, is emerging as a promising avenue for both understanding how semantic concepts are stored within LLMs and advancing LLM capabilities. Yet, existing steering methods are remarkably brittle, with seemingly non-steerable concepts becoming completely steerable based on subtle algorithmic choices in how concept-related features are extracted. In this work, we introduce an attention-guided steering framework that overcomes three core challenges associated with steering: (1) automatic selection of relevant token embeddings for extracting concept-related features; (2) accounting for heterogeneity of concept-related features across LLM activations; and (3) identification of layers most relevant for steering. Across a steering benchmark of 512 semantic concepts, our framework substantially improved steering over previous state-of-the-art (nearly doubling the number of successfully steered concepts) across model architectures and sizes (up to 70 billion parameter models). Furthermore, we use our framework to shed light on the distribution of concept-specific features across LLM layers. Overall, our framework opens further avenues for developing efficient, highly-scalable fine-tuning algorithms for industry-scale LLMs.
Automating Artifact Detection in Video Games
Nov 30, 2020


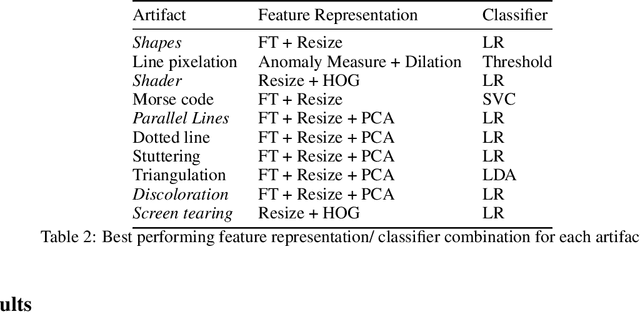
In spite of advances in gaming hardware and software, gameplay is often tainted with graphics errors, glitches, and screen artifacts. This proof of concept study presents a machine learning approach for automated detection of graphics corruptions in video games. Based on a sample of representative screen corruption examples, the model was able to identify 10 of the most commonly occurring screen artifacts with reasonable accuracy. Feature representation of the data included discrete Fourier transforms, histograms of oriented gradients, and graph Laplacians. Various combinations of these features were used to train machine learning models that identify individual classes of graphics corruptions and that later were assembled into a single mixed experts "ensemble" classifier. The ensemble classifier was tested on heldout test sets, and produced an accuracy of 84% on the games it had seen before, and 69% on games it had never seen before.