 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment has a Fantasia Problem
Apr 23, 2026Modern AI assistants are trained to follow instructions, implicitly assuming that users can clearly articulate their goals and the kind of assistance they need. Decades of behavioral research, however, show that people often engage with AI systems before their goals are fully formed. When AI systems treat prompts as complete expressions of intent, they can appear to be useful or convenient, but not necessarily aligned with the users' needs. We call these failures Fantasia interactions. We argue that Fantasia interactions demand a rethinking of alignment research: rather than treating users as rational oracles, AI should provide cognitive support by actively helping users form and refine their intent through time. This requires an interdisciplinary approach that bridges machine learning, interface design, and behavioral science. We synthesize insights from these fields to characterize the mechanisms and failures of Fantasia interactions. We then show why existing interventions are insufficient, and propose a research agenda for designing and evaluating AI systems that better help humans navigate uncertainty in their tasks.
* 9 pages, 2 figures
Creo: From One-Shot Image Generation to Progressive, Co-Creative Ideation
Apr 15, 2026Text-to-image (T2I) systems enable rapid generation of high-fidelity imagery but are misaligned with how visual ideas develop. T2I systems generate outputs that make implicit visual decisions on behalf of the user, often introduce fine-grained details that can anchor users prematurely and limit their ability to keep options open early on, and cause unintended changes during editing that are difficult to correct and reduce users' sense of control. To address these concerns, we present Creo, a multi-stage T2I system that scaffolds image generation by progressing from rough sketches to high-resolution outputs, exposing intermediary abstractions where users can make incremental changes. Sketch-like abstractions invite user editing and allow users to keep design options open when ideas are still forming due to their provisional nature. Each stage in Creo can be modified with manual changes and AI-assisted operations, enabling fine-grained, step-wise control through a locking mechanism that preserves prior decisions so subsequent edits affect only specified regions or attributes. Users remain in the loop, making and verifying decisions across stages, while the system applies diffs instead of regenerating full images, reducing drift as fidelity increases. A comparative study with a one-shot baseline shows that participants felt stronger ownership over Creo outputs, as they were able to trace their decisions in building up the image. Furthermore, embedding-based analysis indicates that Creo outputs are less homogeneous than one-shot results. These findings suggest that multi-stage generation, combined with intermediate control and decision locking, is a key design principle for improving controllability, user agency, creativity, and output diversity in generative systems.
Online Reasoning Calibration: Test-Time Training Enables Generalizable Conformal LLM Reasoning
Apr 01, 2026While test-time scaling has enabled large language models to solve highly difficult tasks, state-of-the-art results come at exorbitant compute costs. These inefficiencies can be attributed to the miscalibration of post-trained language models, and the lack of calibration in popular sampling techniques. Here, we present Online Reasoning Calibration (ORCA), a framework for calibrating the sampling process that draws upon conformal prediction and test-time training. Specifically, we introduce a meta-learning procedure that updates the calibration module for each input. This allows us to provide valid confidence estimates under distributional shift, e.g. in thought patterns that occur across different stages of reasoning, or in prompt distributions between model development and deployment. ORCA not only provides theoretical guarantees on conformal risks, but also empirically shows higher efficiency and generalization across different reasoning tasks. At risk level $δ=0.1$, ORCA improves Qwen2.5-32B efficiency on in-distribution tasks with savings up to 47.5% with supervised labels and 40.7% with self-consistency labels. Under zero-shot out-of-domain settings, it improves MATH-500 savings from 24.8% of the static calibration baseline to 67.0% while maintaining a low empirical error rate, and the same trend holds across model families and downstream benchmarks. Our code is publicly available at https://github.com/wzekai99/ORCA.
From Cross-Validation to SURE: Asymptotic Risk of Tuned Regularized Estimators
Mar 20, 2026We derive the asymptotic risk function of regularized empirical risk minimization (ERM) estimators tuned by $n$-fold cross-validation (CV). The out-of-sample prediction loss of such estimators converges in distribution to the squared-error loss (risk function) of shrinkage estimators in the normal means model, tuned by Stein's unbiased risk estimate (SURE). This risk function provides a more fine-grained picture of predictive performance than uniform bounds on worst-case regret, which are common in learning theory: it quantifies how risk varies with the true parameter. As key intermediate steps, we show that (i) $n$-fold CV converges uniformly to SURE, and (ii) while SURE typically has multiple local minima, its global minimum is generically well separated. Well-separation ensures that uniform convergence of CV to SURE translates into convergence of the tuning parameter chosen by CV to that chosen by SURE.
Efficient and accurate steering of Large Language Models through attention-guided feature learning
Jan 30, 2026Steering, or direct manipulation of internal activations to guide LLM responses toward specific semantic concepts, is emerging as a promising avenue for both understanding how semantic concepts are stored within LLMs and advancing LLM capabilities. Yet, existing steering methods are remarkably brittle, with seemingly non-steerable concepts becoming completely steerable based on subtle algorithmic choices in how concept-related features are extracted. In this work, we introduce an attention-guided steering framework that overcomes three core challenges associated with steering: (1) automatic selection of relevant token embeddings for extracting concept-related features; (2) accounting for heterogeneity of concept-related features across LLM activations; and (3) identification of layers most relevant for steering. Across a steering benchmark of 512 semantic concepts, our framework substantially improved steering over previous state-of-the-art (nearly doubling the number of successfully steered concepts) across model architectures and sizes (up to 70 billion parameter models). Furthermore, we use our framework to shed light on the distribution of concept-specific features across LLM layers. Overall, our framework opens further avenues for developing efficient, highly-scalable fine-tuning algorithms for industry-scale LLMs.
UCD: Unlearning in LLMs via Contrastive Decoding
Jun 12, 2025Machine unlearning aims to remove specific information, e.g. sensitive or undesirable content, from large language models (LLMs) while preserving overall performance. We propose an inference-time unlearning algorithm that uses contrastive decoding, leveraging two auxiliary smaller models, one trained without the forget set and one trained with it, to guide the outputs of the original model using their difference during inference. Our strategy substantially improves the tradeoff between unlearning effectiveness and model utility. We evaluate our approach on two unlearning benchmarks, TOFU and MUSE. Results show notable gains in both forget quality and retained performance in comparison to prior approaches, suggesting that incorporating contrastive decoding can offer an efficient, practical avenue for unlearning concepts in large-scale models.
Layered Unlearning for Adversarial Relearning
May 14, 2025Our goal is to understand how post-training methods, such as fine-tuning, alignment, and unlearning, modify language model behavior and representations. We are particularly interested in the brittle nature of these modifications that makes them easy to bypass through prompt engineering or relearning. Recent results suggest that post-training induces shallow context-dependent ``circuits'' that suppress specific response patterns. This could be one explanation for the brittleness of post-training. To test this hypothesis, we design an unlearning algorithm, Layered Unlearning (LU), that creates distinct inhibitory mechanisms for a growing subset of the data. By unlearning the first $i$ folds while retaining the remaining $k - i$ at the $i$th of $k$ stages, LU limits the ability of relearning on a subset of data to recover the full dataset. We evaluate LU through a combination of synthetic and large language model (LLM) experiments. We find that LU improves robustness to adversarial relearning for several different unlearning methods. Our results contribute to the state-of-the-art of machine unlearning and provide insight into the effect of post-training updates.
High-accuracy sampling from constrained spaces with the Metropolis-adjusted Preconditioned Langevin Algorithm
Dec 24, 2024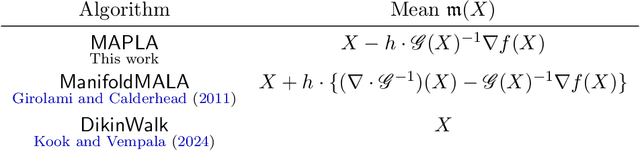
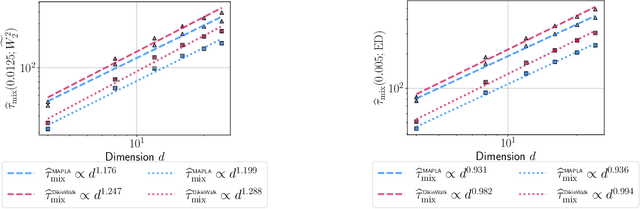

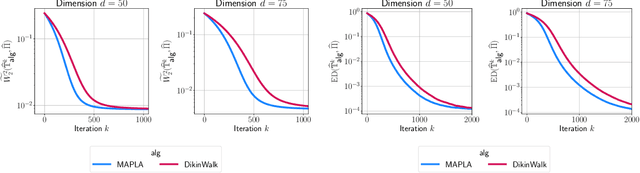
In this work, we propose a first-order sampling method called the Metropolis-adjusted Preconditioned Langevin Algorithm for approximate sampling from a target distribution whose support is a proper convex subset of $\mathbb{R}^{d}$. Our proposed method is the result of applying a Metropolis-Hastings filter to the Markov chain formed by a single step of the preconditioned Langevin algorithm with a metric $\mathscr{G}$, and is motivated by the natural gradient descent algorithm for optimisation. We derive non-asymptotic upper bounds for the mixing time of this method for sampling from target distributions whose potentials are bounded relative to $\mathscr{G}$, and for exponential distributions restricted to the support. Our analysis suggests that if $\mathscr{G}$ satisfies stronger notions of self-concordance introduced in Kook and Vempala (2024), then these mixing time upper bounds have a strictly better dependence on the dimension than when is merely self-concordant. We also provide numerical experiments that demonstrates the practicality of our proposed method. Our method is a high-accuracy sampler due to the polylogarithmic dependence on the error tolerance in our mixing time upper bounds.
Faster Machine Unlearning via Natural Gradient Descent
Jul 11, 2024



We address the challenge of efficiently and reliably deleting data from machine learning models trained using Empirical Risk Minimization (ERM), a process known as machine unlearning. To avoid retraining models from scratch, we propose a novel algorithm leveraging Natural Gradient Descent (NGD). Our theoretical framework ensures strong privacy guarantees for convex models, while a practical Min/Max optimization algorithm is developed for non-convex models. Comprehensive evaluations show significant improvements in privacy, computational efficiency, and generalization compared to state-of-the-art methods, advancing both the theoretical and practical aspects of machine unlearning.
Mean-field underdamped Langevin dynamics and its spacetime discretization
Jan 17, 2024

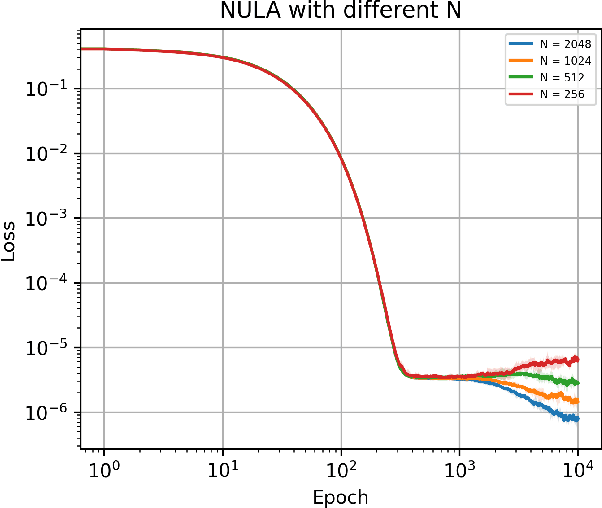

We propose a new method called the N-particle underdamped Langevin algorithm for optimizing a special class of non-linear functionals defined over the space of probability measures. Examples of problems with this formulation include training mean-field neural networks, maximum mean discrepancy minimization and kernel Stein discrepancy minimization. Our algorithm is based on a novel spacetime discretization of the mean-field underdamped Langevin dynamics, for which we provide a new, fast mixing guarantee. In addition, we demonstrate that our algorithm converges globally in total variation distance, bridging the theoretical gap between the dynamics and its practical implementation.