 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV Prediction for Improved Time to First Token
Oct 10, 2024



Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at https://github.com/apple/corenet/tree/main/projects/kv-prediction .
An Efficient and Streaming Audio Visual Active Speaker Detection System
Sep 13, 2024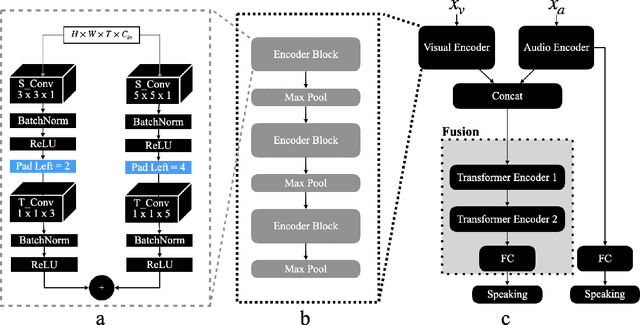


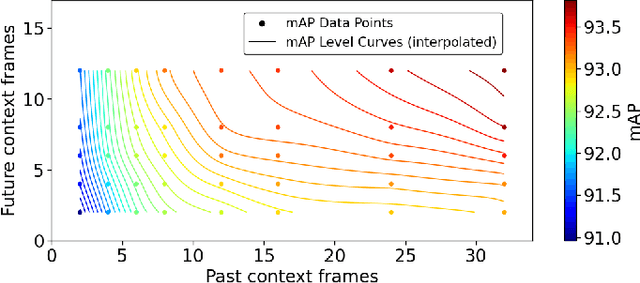
This paper delves into the challenging task of Active Speaker Detection (ASD), where the system needs to determine in real-time whether a person is speaking or not in a series of video frames. While previous works have made significant strides in improving network architectures and learning effective representations for ASD, a critical gap exists in the exploration of real-time system deployment. Existing models often suffer from high latency and memory usage, rendering them impractical for immediate applications. To bridge this gap, we present two scenarios that address the key challenges posed by real-time constraints. First, we introduce a method to limit the number of future context frames utilized by the ASD model. By doing so, we alleviate the need for processing the entire sequence of future frames before a decision is made, significantly reducing latency. Second, we propose a more stringent constraint that limits the total number of past frames the model can access during inference. This tackles the persistent memory issues associated with running streaming ASD systems. Beyond these theoretical frameworks, we conduct extensive experiments to validate our approach. Our results demonstrate that constrained transformer models can achieve performance comparable to or even better than state-of-the-art recurrent models, such as uni-directional GRUs, with a significantly reduced number of context frames. Moreover, we shed light on the temporal memory requirements of ASD systems, revealing that larger past context has a more profound impact on accuracy than future context. When profiling on a CPU we find that our efficient architecture is memory bound by the amount of past context it can use and that the compute cost is negligible as compared to the memory cost.
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
Diffusion Models as Masked Audio-Video Learners
Oct 05, 2023



Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
Layer-Wise Data-Free CNN Compression
Nov 18, 2020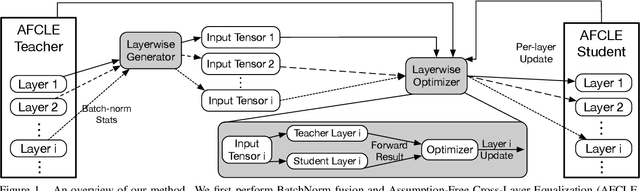
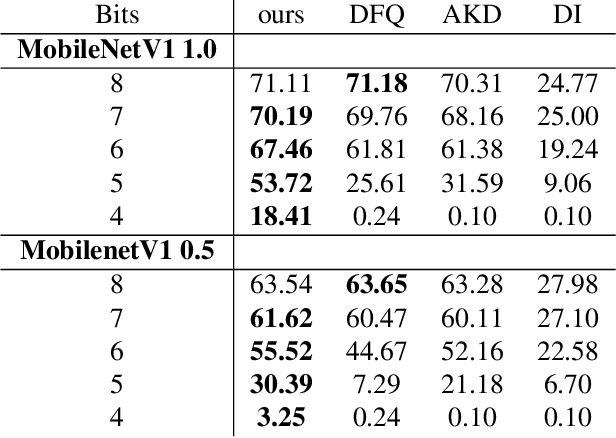
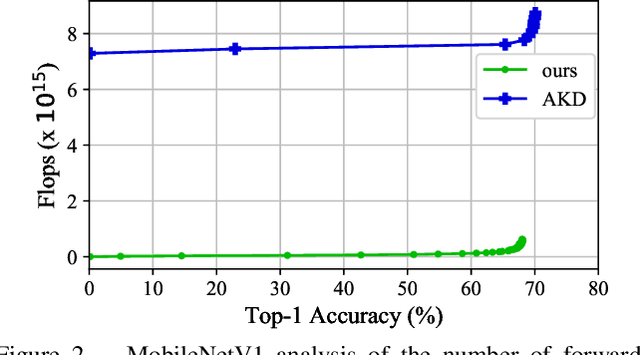
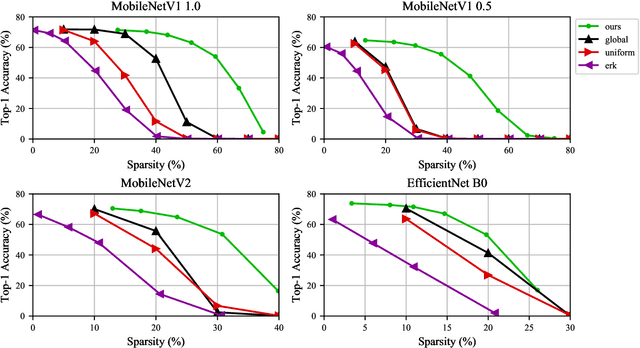
We present an efficient method for compressing a trained neural network without using any data. Our data-free method requires 14x-450x fewer FLOPs than comparable state-of-the-art methods. We break the problem of data-free network compression into a number of independent layer-wise compressions. We show how to efficiently generate layer-wise training data, and how to precondition the network to maintain accuracy during layer-wise compression. We show state-of-the-art performance on MobileNetV1 for data-free low-bit-width quantization. We also show state-of-the-art performance on data-free pruning of EfficientNet B0 when combining our method with end-to-end generative methods.