 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERA: Soft-Verified Efficient Repository Agents
Jan 28, 2026Open-weight coding agents should hold a fundamental advantage over closed-source systems: they can be specialized to private codebases, encoding repository-specific information directly in their weights. Yet the cost and complexity of training has kept this advantage theoretical. We show it is now practical. We present Soft-Verified Efficient Repository Agents (SERA), an efficient method for training coding agents that enables the rapid and cheap creation of agents specialized to private codebases. Using only supervised finetuning (SFT), SERA achieves state-of-the-art results among fully open-source (open data, method, code) models while matching the performance of frontier open-weight models like Devstral-Small-2. Creating SERA models is 26x cheaper than reinforcement learning and 57x cheaper than previous synthetic data methods to reach equivalent performance. Our method, Soft Verified Generation (SVG), generates thousands of trajectories from a single code repository. Combined with cost-efficiency, this enables specialization to private codebases. Beyond repository specialization, we apply SVG to a larger corpus of codebases, generating over 200,000 synthetic trajectories. We use this dataset to provide detailed analysis of scaling laws, ablations, and confounding factors for training coding agents. Overall, we believe our work will greatly accelerate research on open coding agents and showcase the advantage of open-source models that can specialize to private codebases. We release SERA as the first model in Ai2's Open Coding Agents series, along with all our code, data, and Claude Code integration to support the research community.
An Efficient and Streaming Audio Visual Active Speaker Detection System
Sep 13, 2024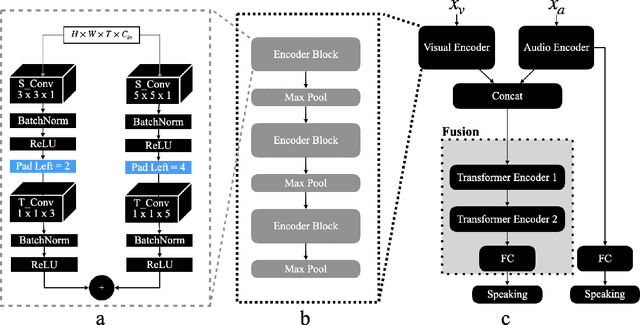


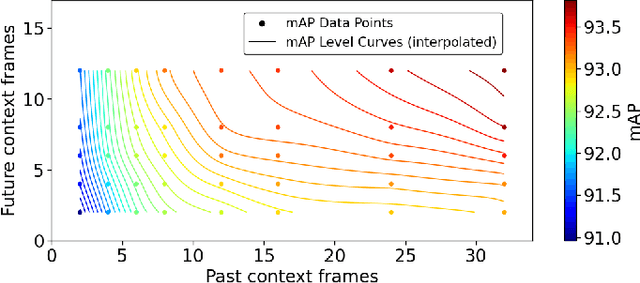
This paper delves into the challenging task of Active Speaker Detection (ASD), where the system needs to determine in real-time whether a person is speaking or not in a series of video frames. While previous works have made significant strides in improving network architectures and learning effective representations for ASD, a critical gap exists in the exploration of real-time system deployment. Existing models often suffer from high latency and memory usage, rendering them impractical for immediate applications. To bridge this gap, we present two scenarios that address the key challenges posed by real-time constraints. First, we introduce a method to limit the number of future context frames utilized by the ASD model. By doing so, we alleviate the need for processing the entire sequence of future frames before a decision is made, significantly reducing latency. Second, we propose a more stringent constraint that limits the total number of past frames the model can access during inference. This tackles the persistent memory issues associated with running streaming ASD systems. Beyond these theoretical frameworks, we conduct extensive experiments to validate our approach. Our results demonstrate that constrained transformer models can achieve performance comparable to or even better than state-of-the-art recurrent models, such as uni-directional GRUs, with a significantly reduced number of context frames. Moreover, we shed light on the temporal memory requirements of ASD systems, revealing that larger past context has a more profound impact on accuracy than future context. When profiling on a CPU we find that our efficient architecture is memory bound by the amount of past context it can use and that the compute cost is negligible as compared to the memory cost.