 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
Jan 30, 2026Understanding how transformer components operate in LLMs is important, as it is at the core of recent technological advances in artificial intelligence. In this work, we revisit the challenges associated with interpretability of feed-forward modules (FFNs) and propose MemoryLLM, which aims to decouple FFNs from self-attention and enables us to study the decoupled FFNs as context-free token-wise neural retrieval memory. In detail, we investigate how input tokens access memory locations within FFN parameters and the importance of FFN memory across different downstream tasks. MemoryLLM achieves context-free FFNs by training them in isolation from self-attention directly using the token embeddings. This approach allows FFNs to be pre-computed as token-wise lookups (ToLs), enabling on-demand transfer between VRAM and storage, additionally enhancing inference efficiency. We also introduce Flex-MemoryLLM, positioning it between a conventional transformer design and MemoryLLM. This architecture bridges the performance gap caused by training FFNs with context-free token-wise embeddings.
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Jul 16, 2025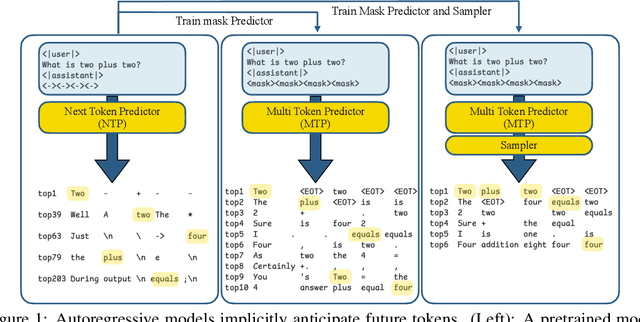
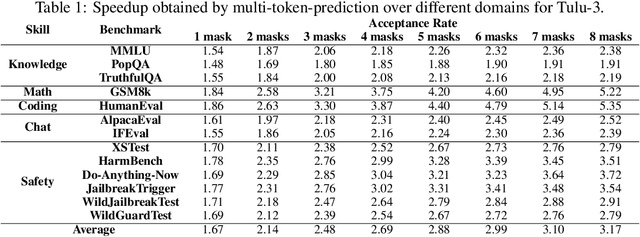
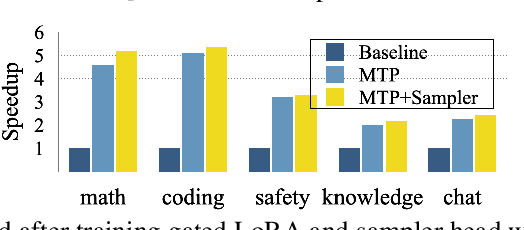
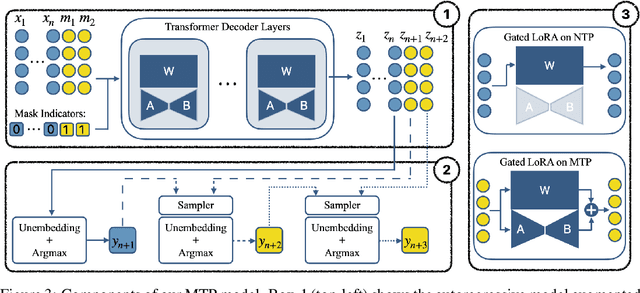
Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
SPD: Sync-Point Drop for efficient tensor parallelism of Large Language Models
Feb 28, 2025With the rapid expansion in the scale of large language models (LLMs), enabling efficient distributed inference across multiple computing units has become increasingly critical. However, communication overheads from popular distributed inference techniques such as Tensor Parallelism pose a significant challenge to achieve scalability and low latency. Therefore, we introduce a novel optimization technique, Sync-Point Drop (SPD), to reduce communication overheads in tensor parallelism by selectively dropping synchronization on attention outputs. In detail, we first propose a block design that allows execution to proceed without communication through SPD. Second, we apply different SPD strategies to attention blocks based on their sensitivity to the model accuracy. The proposed methods effectively alleviate communication bottlenecks while minimizing accuracy degradation during LLM inference, offering a scalable solution for diverse distributed environments: SPD offered about 20% overall inference latency reduction with < 1% accuracy regression for LLaMA2-70B inference over 8 GPUs.
An Efficient and Streaming Audio Visual Active Speaker Detection System
Sep 13, 2024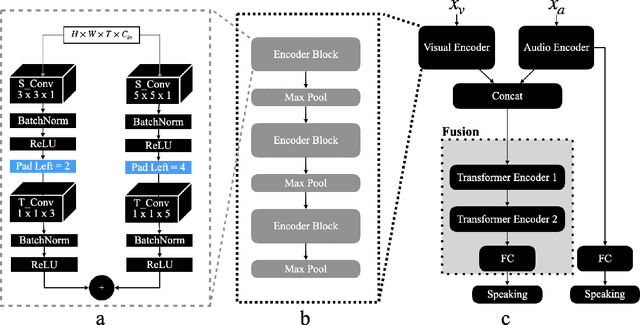


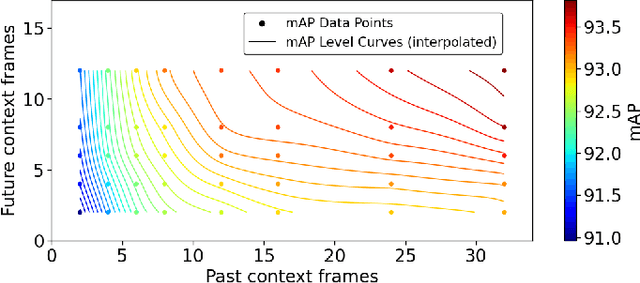
This paper delves into the challenging task of Active Speaker Detection (ASD), where the system needs to determine in real-time whether a person is speaking or not in a series of video frames. While previous works have made significant strides in improving network architectures and learning effective representations for ASD, a critical gap exists in the exploration of real-time system deployment. Existing models often suffer from high latency and memory usage, rendering them impractical for immediate applications. To bridge this gap, we present two scenarios that address the key challenges posed by real-time constraints. First, we introduce a method to limit the number of future context frames utilized by the ASD model. By doing so, we alleviate the need for processing the entire sequence of future frames before a decision is made, significantly reducing latency. Second, we propose a more stringent constraint that limits the total number of past frames the model can access during inference. This tackles the persistent memory issues associated with running streaming ASD systems. Beyond these theoretical frameworks, we conduct extensive experiments to validate our approach. Our results demonstrate that constrained transformer models can achieve performance comparable to or even better than state-of-the-art recurrent models, such as uni-directional GRUs, with a significantly reduced number of context frames. Moreover, we shed light on the temporal memory requirements of ASD systems, revealing that larger past context has a more profound impact on accuracy than future context. When profiling on a CPU we find that our efficient architecture is memory bound by the amount of past context it can use and that the compute cost is negligible as compared to the memory cost.
RepCNN: Micro-sized, Mighty Models for Wakeword Detection
Jun 04, 2024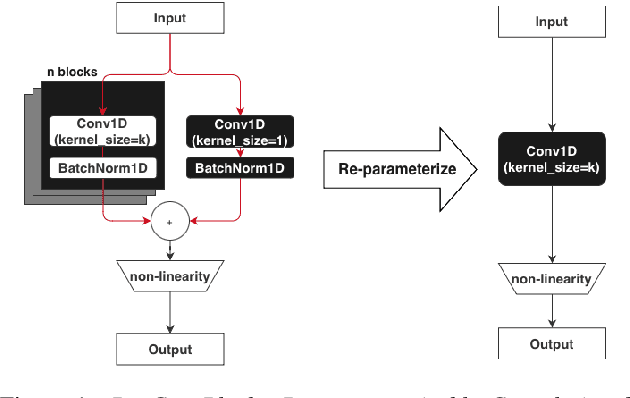

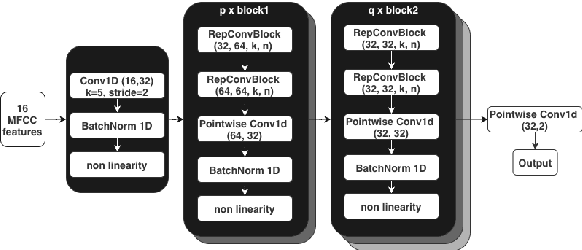

Always-on machine learning models require a very low memory and compute footprint. Their restricted parameter count limits the model's capacity to learn, and the effectiveness of the usual training algorithms to find the best parameters. Here we show that a small convolutional model can be better trained by first refactoring its computation into a larger redundant multi-branched architecture. Then, for inference, we algebraically re-parameterize the trained model into the single-branched form with fewer parameters for a lower memory footprint and compute cost. Using this technique, we show that our always-on wake-word detector model, RepCNN, provides a good trade-off between latency and accuracy during inference. RepCNN re-parameterized models are 43% more accurate than a uni-branch convolutional model while having the same runtime. RepCNN also meets the accuracy of complex architectures like BC-ResNet, while having 2x lesser peak memory usage and 10x faster runtime.
Streaming Anchor Loss: Augmenting Supervision with Temporal Significance
Oct 09, 2023Streaming neural network models for fast frame-wise responses to various speech and sensory signals are widely adopted on resource-constrained platforms. Hence, increasing the learning capacity of such streaming models (i.e., by adding more parameters) to improve the predictive power may not be viable for real-world tasks. In this work, we propose a new loss, Streaming Anchor Loss (SAL), to better utilize the given learning capacity by encouraging the model to learn more from essential frames. More specifically, our SAL and its focal variations dynamically modulate the frame-wise cross entropy loss based on the importance of the corresponding frames so that a higher loss penalty is assigned for frames within the temporal proximity of semantically critical events. Therefore, our loss ensures that the model training focuses on predicting the relatively rare but task-relevant frames. Experimental results with standard lightweight convolutional and recurrent streaming networks on three different speech based detection tasks demonstrate that SAL enables the model to learn the overall task more effectively with improved accuracy and latency, without any additional data, model parameters, or architectural changes.
R^2: Range Regularization for Model Compression and Quantization
Mar 14, 2023



Model parameter regularization is a widely used technique to improve generalization, but also can be used to shape the weight distributions for various purposes. In this work, we shed light on how weight regularization can assist model quantization and compression techniques, and then propose range regularization (R^2) to further boost the quality of model optimization by focusing on the outlier prevention. By effectively regulating the minimum and maximum weight values from a distribution, we mold the overall distribution into a tight shape so that model compression and quantization techniques can better utilize their limited numeric representation powers. We introduce L-inf regularization, its extension margin regularization and a new soft-min-max regularization to be used as a regularization loss during full-precision model training. Coupled with state-of-the-art quantization and compression techniques, models trained with R^2 perform better on an average, specifically at lower bit weights with 16x compression ratio. We also demonstrate that R^2 helps parameter constrained models like MobileNetV1 achieve significant improvement of around 8% for 2 bit quantization and 7% for 1 bit compression.
HEiMDaL: Highly Efficient Method for Detection and Localization of wake-words
Oct 26, 2022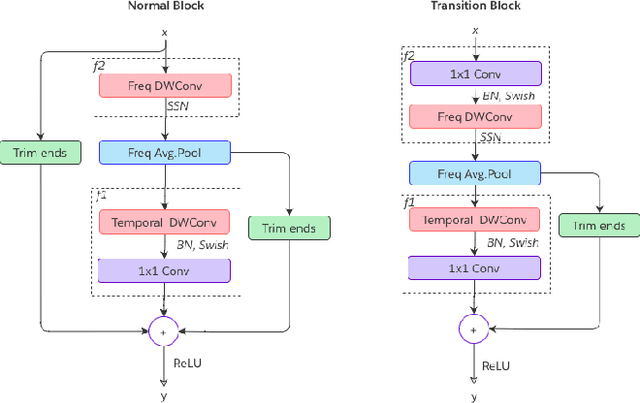
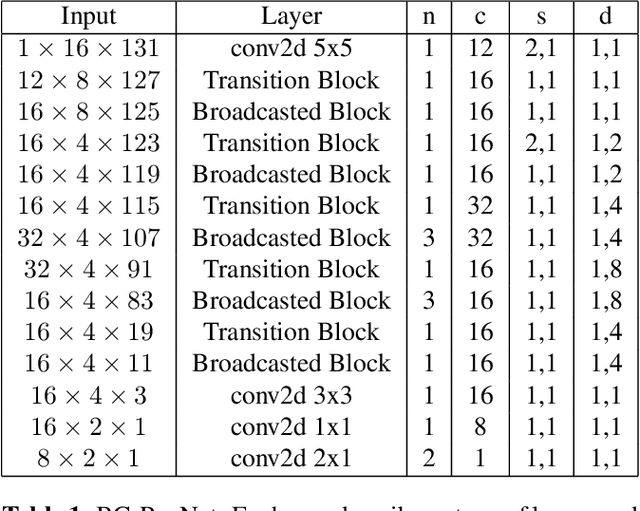
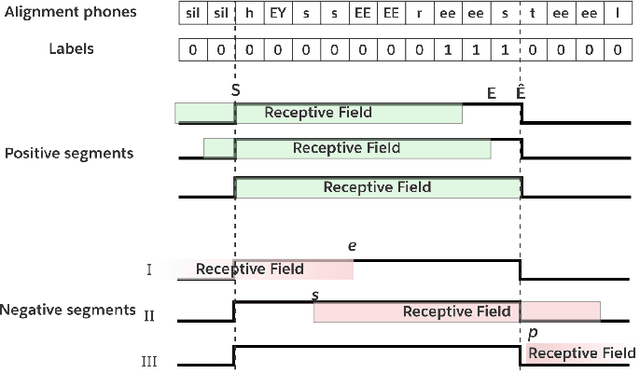

Streaming keyword spotting is a widely used solution for activating voice assistants. Deep Neural Networks with Hidden Markov Model (DNN-HMM) based methods have proven to be efficient and widely adopted in this space, primarily because of the ability to detect and identify the start and end of the wake-up word at low compute cost. However, such hybrid systems suffer from loss metric mismatch when the DNN and HMM are trained independently. Sequence discriminative training cannot fully mitigate the loss-metric mismatch due to the inherent Markovian style of the operation. We propose an low footprint CNN model, called HEiMDaL, to detect and localize keywords in streaming conditions. We introduce an alignment-based classification loss to detect the occurrence of the keyword along with an offset loss to predict the start of the keyword. HEiMDaL shows 73% reduction in detection metrics along with equivalent localization accuracy and with the same memory footprint as existing DNN-HMM style models for a given wake-word.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
Optimize what matters: Training DNN-HMM Keyword Spotting Model Using End Metric
Nov 02, 2020

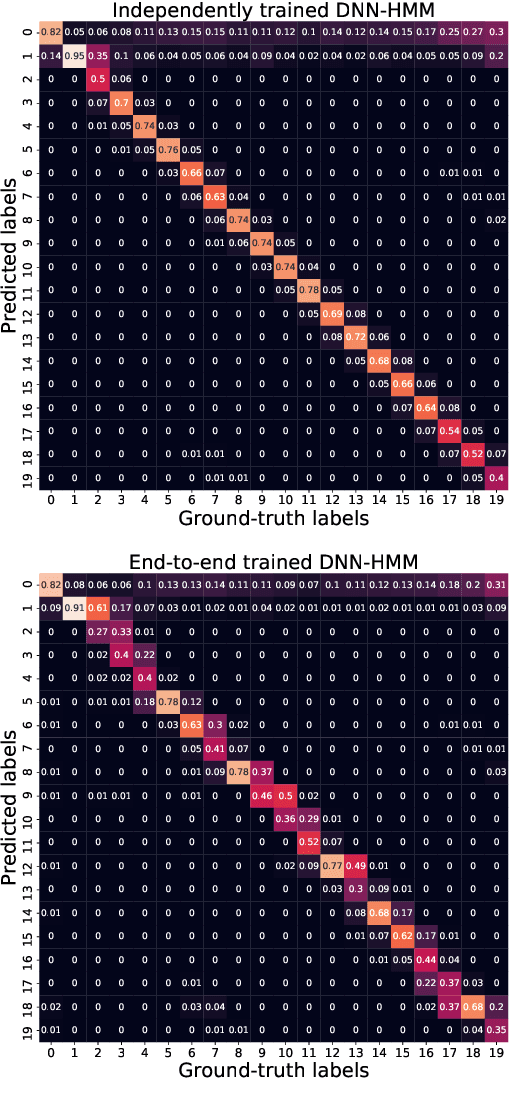
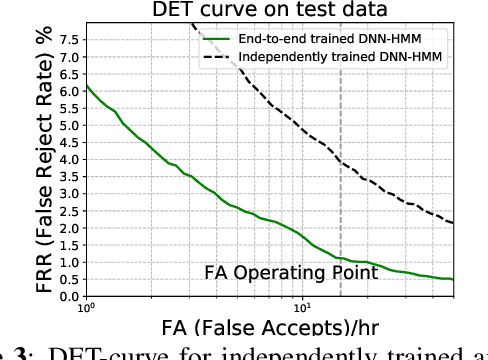
Deep Neural Network--Hidden Markov Model (DNN-HMM) based methods have been successfully used for many always-on keyword spotting algorithms that detect a wake word to trigger a device. The DNN predicts the state probabilities of a given speech frame, while HMM decoder combines the DNN predictions of multiple speech frames to compute the keyword detection score. The DNN, in prior methods, is trained independent of the HMM parameters to minimize the cross-entropy loss between the predicted and the ground-truth state probabilities. The mis-match between the DNN training loss (cross-entropy) and the end metric (detection score) is the main source of sub-optimal performance for the keyword spotting task. We address this loss-metric mismatch with a novel end-to-end training strategy that learns the DNN parameters by optimizing for the detection score. To this end, we make the HMM decoder (dynamic programming) differentiable and back-propagate through it to maximize the score for the keyword and minimize the scores for non-keyword speech segments. Our method does not require any change in the model architecture or the inference framework; therefore, there is no overhead in run-time memory or compute requirements. Moreover, we show significant reduction in false rejection rate (FRR) at the same false trigger experience (> 70% over independent DNN training).