 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepCNN: Micro-sized, Mighty Models for Wakeword Detection
Jun 04, 2024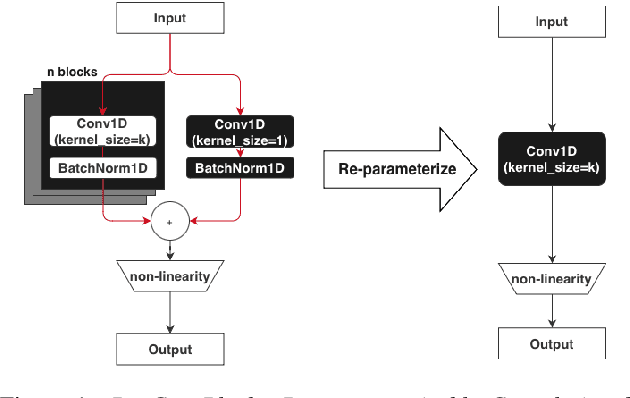

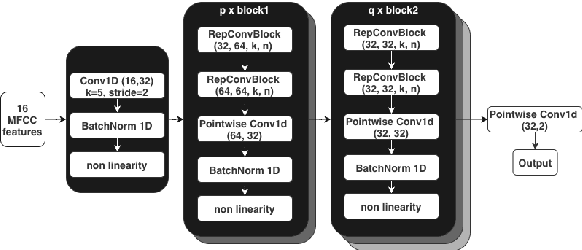

Always-on machine learning models require a very low memory and compute footprint. Their restricted parameter count limits the model's capacity to learn, and the effectiveness of the usual training algorithms to find the best parameters. Here we show that a small convolutional model can be better trained by first refactoring its computation into a larger redundant multi-branched architecture. Then, for inference, we algebraically re-parameterize the trained model into the single-branched form with fewer parameters for a lower memory footprint and compute cost. Using this technique, we show that our always-on wake-word detector model, RepCNN, provides a good trade-off between latency and accuracy during inference. RepCNN re-parameterized models are 43% more accurate than a uni-branch convolutional model while having the same runtime. RepCNN also meets the accuracy of complex architectures like BC-ResNet, while having 2x lesser peak memory usage and 10x faster runtime.
HEiMDaL: Highly Efficient Method for Detection and Localization of wake-words
Oct 26, 2022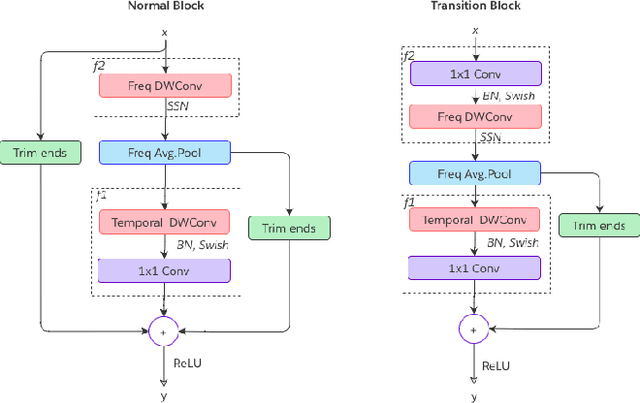
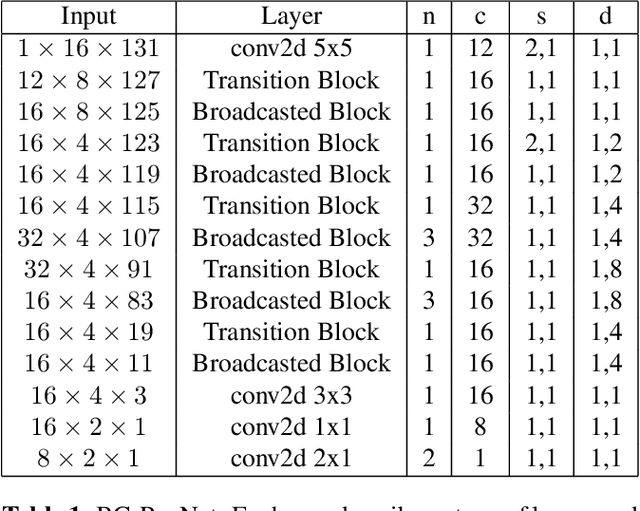
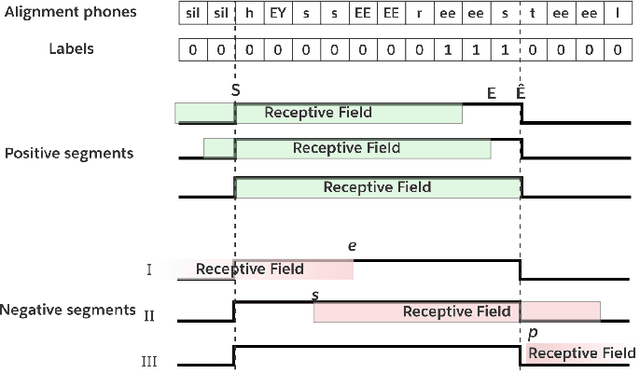

Streaming keyword spotting is a widely used solution for activating voice assistants. Deep Neural Networks with Hidden Markov Model (DNN-HMM) based methods have proven to be efficient and widely adopted in this space, primarily because of the ability to detect and identify the start and end of the wake-up word at low compute cost. However, such hybrid systems suffer from loss metric mismatch when the DNN and HMM are trained independently. Sequence discriminative training cannot fully mitigate the loss-metric mismatch due to the inherent Markovian style of the operation. We propose an low footprint CNN model, called HEiMDaL, to detect and localize keywords in streaming conditions. We introduce an alignment-based classification loss to detect the occurrence of the keyword along with an offset loss to predict the start of the keyword. HEiMDaL shows 73% reduction in detection metrics along with equivalent localization accuracy and with the same memory footprint as existing DNN-HMM style models for a given wake-word.