 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepCNN: Micro-sized, Mighty Models for Wakeword Detection
Paper and Code
Jun 04, 2024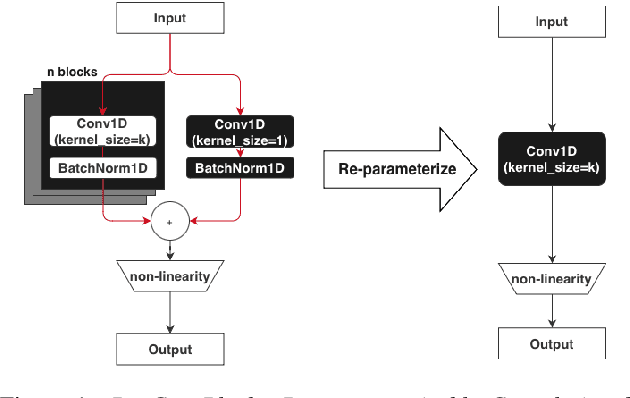

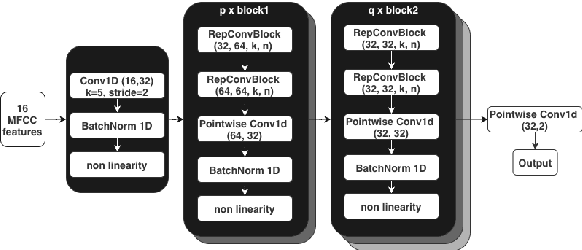

Always-on machine learning models require a very low memory and compute footprint. Their restricted parameter count limits the model's capacity to learn, and the effectiveness of the usual training algorithms to find the best parameters. Here we show that a small convolutional model can be better trained by first refactoring its computation into a larger redundant multi-branched architecture. Then, for inference, we algebraically re-parameterize the trained model into the single-branched form with fewer parameters for a lower memory footprint and compute cost. Using this technique, we show that our always-on wake-word detector model, RepCNN, provides a good trade-off between latency and accuracy during inference. RepCNN re-parameterized models are 43% more accurate than a uni-branch convolutional model while having the same runtime. RepCNN also meets the accuracy of complex architectures like BC-ResNet, while having 2x lesser peak memory usage and 10x faster runtime.