 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Anchor Loss: Augmenting Supervision with Temporal Significance
Oct 09, 2023Streaming neural network models for fast frame-wise responses to various speech and sensory signals are widely adopted on resource-constrained platforms. Hence, increasing the learning capacity of such streaming models (i.e., by adding more parameters) to improve the predictive power may not be viable for real-world tasks. In this work, we propose a new loss, Streaming Anchor Loss (SAL), to better utilize the given learning capacity by encouraging the model to learn more from essential frames. More specifically, our SAL and its focal variations dynamically modulate the frame-wise cross entropy loss based on the importance of the corresponding frames so that a higher loss penalty is assigned for frames within the temporal proximity of semantically critical events. Therefore, our loss ensures that the model training focuses on predicting the relatively rare but task-relevant frames. Experimental results with standard lightweight convolutional and recurrent streaming networks on three different speech based detection tasks demonstrate that SAL enables the model to learn the overall task more effectively with improved accuracy and latency, without any additional data, model parameters, or architectural changes.
A Critical Review of Recurrent Neural Networks for Sequence Learning
Oct 17, 2015
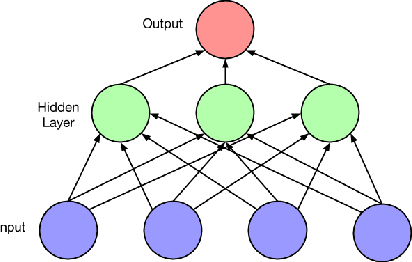
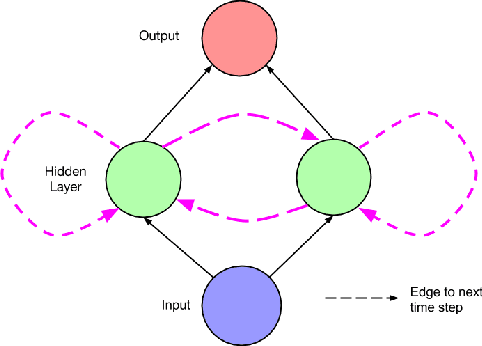
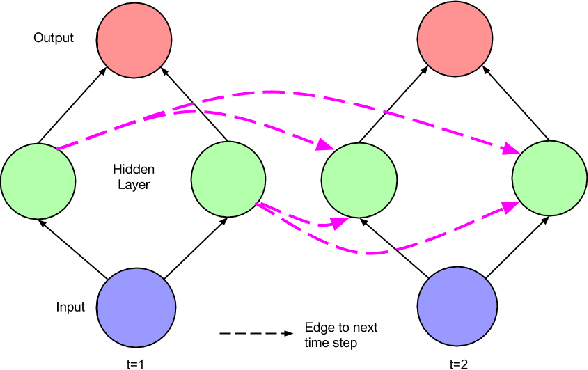
Countless learning tasks require dealing with sequential data. Image captioning, speech synthesis, and music generation all require that a model produce outputs that are sequences. In other domains, such as time series prediction, video analysis, and musical information retrieval, a model must learn from inputs that are sequences. Interactive tasks, such as translating natural language, engaging in dialogue, and controlling a robot, often demand both capabilities. Recurrent neural networks (RNNs) are connectionist models that capture the dynamics of sequences via cycles in the network of nodes. Unlike standard feedforward neural networks, recurrent networks retain a state that can represent information from an arbitrarily long context window. Although recurrent neural networks have traditionally been difficult to train, and often contain millions of parameters, recent advances in network architectures, optimization techniques, and parallel computation have enabled successful large-scale learning with them. In recent years, systems based on long short-term memory (LSTM) and bidirectional (BRNN) architectures have demonstrated ground-breaking performance on tasks as varied as image captioning, language translation, and handwriting recognition. In this survey, we review and synthesize the research that over the past three decades first yielded and then made practical these powerful learning models. When appropriate, we reconcile conflicting notation and nomenclature. Our goal is to provide a self-contained explication of the state of the art together with a historical perspective and references to primary research.