 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion Models are Secretly Good at Visual In-Context Learning
Aug 13, 2025Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) -- the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These approaches involve specialized training and/or additional data that complicate the process and limit its generalizability. In this work, we show that off-the-shelf Stable Diffusion models can be repurposed for visual in-context learning (V-ICL). Specifically, we formulate an in-place attention re-computation within the self-attention layers of the Stable Diffusion architecture that explicitly incorporates context between the query and example prompts. Without any additional fine-tuning, we show that this repurposed Stable Diffusion model is able to adapt to six different tasks: foreground segmentation, single object detection, semantic segmentation, keypoint detection, edge detection, and colorization. For example, the proposed approach improves the mean intersection over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by 8.9% and 3.2% over recent methods such as Visual Prompting and IMProv, respectively. Additionally, we show that the proposed method is able to effectively leverage multiple prompts through ensembling to infer the task better and further improve the performance.
What do Vision Transformers Learn? A Visual Exploration
Dec 13, 2022



Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging. In this paper, we first address the obstacles to performing visualizations on ViTs. Assisted by these solutions, we observe that neurons in ViTs trained with language model supervision (e.g., CLIP) are activated by semantic concepts rather than visual features. We also explore the underlying differences between ViTs and CNNs, and we find that transformers detect image background features, just like their convolutional counterparts, but their predictions depend far less on high-frequency information. On the other hand, both architecture types behave similarly in the way features progress from abstract patterns in early layers to concrete objects in late layers. In addition, we show that ViTs maintain spatial information in all layers except the final layer. In contrast to previous works, we show that the last layer most likely discards the spatial information and behaves as a learned global pooling operation. Finally, we conduct large-scale visualizations on a wide range of ViT variants, including DeiT, CoaT, ConViT, PiT, Swin, and Twin, to validate the effectiveness of our method.
Adaptive Weight Decay: On The Fly Weight Decay Tuning for Improving Robustness
Sep 30, 2022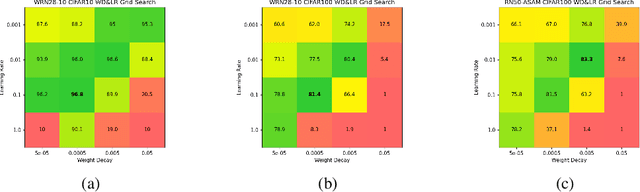

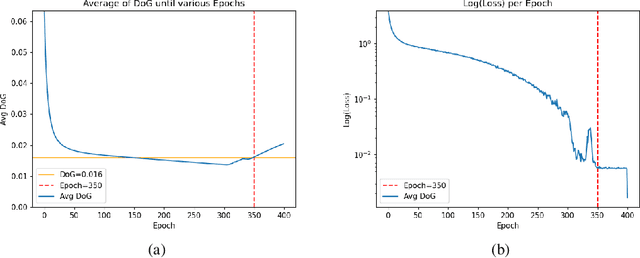

We introduce adaptive weight decay, which automatically tunes the hyper-parameter for weight decay during each training iteration. For classification problems, we propose changing the value of the weight decay hyper-parameter on the fly based on the strength of updates from the classification loss (i.e., gradient of cross-entropy), and the regularization loss (i.e., $\ell_2$-norm of the weights). We show that this simple modification can result in large improvements in adversarial robustness -- an area which suffers from robust overfitting -- without requiring extra data. Specifically, our reformulation results in 20% relative robustness improvement for CIFAR-100, and 10% relative robustness improvement on CIFAR-10 comparing to traditional weight decay. In addition, this method has other desirable properties, such as less sensitivity to learning rate, and smaller weight norms, which the latter contributes to robustness to overfitting to label noise, and pruning.
Plug-In Inversion: Model-Agnostic Inversion for Vision with Data Augmentations
Jan 31, 2022



Existing techniques for model inversion typically rely on hard-to-tune regularizers, such as total variation or feature regularization, which must be individually calibrated for each network in order to produce adequate images. In this work, we introduce Plug-In Inversion, which relies on a simple set of augmentations and does not require excessive hyper-parameter tuning. Under our proposed augmentation-based scheme, the same set of augmentation hyper-parameters can be used for inverting a wide range of image classification models, regardless of input dimensions or the architecture. We illustrate the practicality of our approach by inverting Vision Transformers (ViTs) and Multi-Layer Perceptrons (MLPs) trained on the ImageNet dataset, tasks which to the best of our knowledge have not been successfully accomplished by any previous works.
DP-InstaHide: Provably Defusing Poisoning and Backdoor Attacks with Differentially Private Data Augmentations
Mar 02, 2021Data poisoning and backdoor attacks manipulate training data to induce security breaches in a victim model. These attacks can be provably deflected using differentially private (DP) training methods, although this comes with a sharp decrease in model performance. The InstaHide method has recently been proposed as an alternative to DP training that leverages supposed privacy properties of the mixup augmentation, although without rigorous guarantees. In this work, we show that strong data augmentations, such as mixup and random additive noise, nullify poison attacks while enduring only a small accuracy trade-off. To explain these finding, we propose a training method, DP-InstaHide, which combines the mixup regularizer with additive noise. A rigorous analysis of DP-InstaHide shows that mixup does indeed have privacy advantages, and that training with k-way mixup provably yields at least k times stronger DP guarantees than a naive DP mechanism. Because mixup (as opposed to noise) is beneficial to model performance, DP-InstaHide provides a mechanism for achieving stronger empirical performance against poisoning attacks than other known DP methods.
Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy Tradeoff
Nov 18, 2020


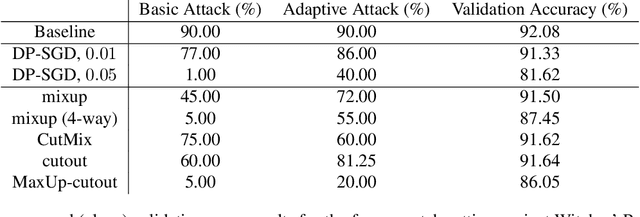
Data poisoning and backdoor attacks manipulate victim models by maliciously modifying training data. In light of this growing threat, a recent survey of industry professionals revealed heightened fear in the private sector regarding data poisoning. Many previous defenses against poisoning either fail in the face of increasingly strong attacks, or they significantly degrade performance. However, we find that strong data augmentations, such as mixup and CutMix, can significantly diminish the threat of poisoning and backdoor attacks without trading off performance. We further verify the effectiveness of this simple defense against adaptive poisoning methods, and we compare to baselines including the popular differentially private SGD (DP-SGD) defense. In the context of backdoors, CutMix greatly mitigates the attack while simultaneously increasing validation accuracy by 9%.
Towards Accurate Quantization and Pruning via Data-free Knowledge Transfer
Oct 14, 2020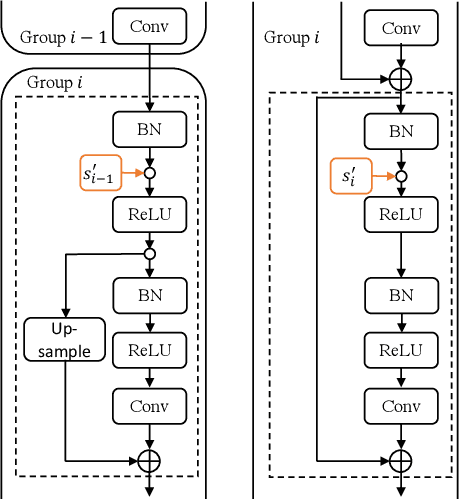
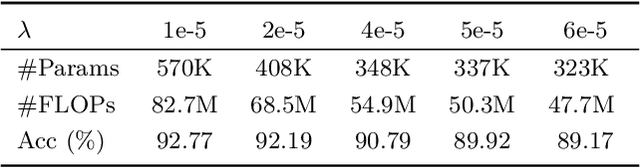
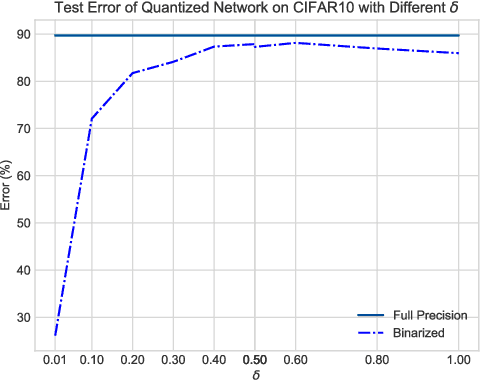
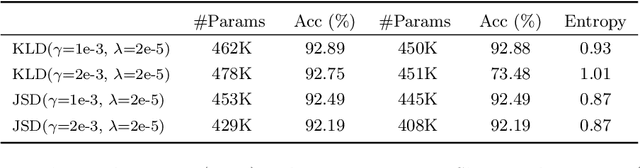
When large scale training data is available, one can obtain compact and accurate networks to be deployed in resource-constrained environments effectively through quantization and pruning. However, training data are often protected due to privacy concerns and it is challenging to obtain compact networks without data. We study data-free quantization and pruning by transferring knowledge from trained large networks to compact networks. Auxiliary generators are simultaneously and adversarially trained with the targeted compact networks to generate synthetic inputs that maximize the discrepancy between the given large network and its quantized or pruned version. We show theoretically that the alternating optimization for the underlying minimax problem converges under mild conditions for pruning and quantization. Our data-free compact networks achieve competitive accuracy to networks trained and fine-tuned with training data. Our quantized and pruned networks achieve good performance while being more compact and lightweight. Further, we demonstrate that the compact structure and corresponding initialization from the Lottery Ticket Hypothesis can also help in data-free training.
Breaking certified defenses: Semantic adversarial examples with spoofed robustness certificates
Mar 19, 2020

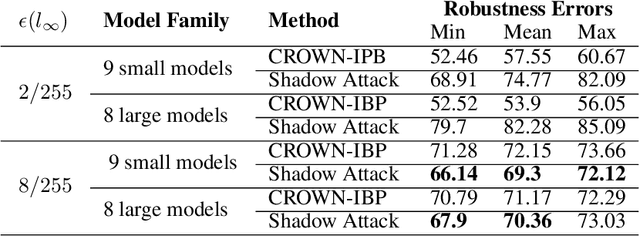

To deflect adversarial attacks, a range of "certified" classifiers have been proposed. In addition to labeling an image, certified classifiers produce (when possible) a certificate guaranteeing that the input image is not an $\ell_p$-bounded adversarial example. We present a new attack that exploits not only the labelling function of a classifier, but also the certificate generator. The proposed method applies large perturbations that place images far from a class boundary while maintaining the imperceptibility property of adversarial examples. The proposed "Shadow Attack" causes certifiably robust networks to mislabel an image and simultaneously produce a "spoofed" certificate of robustness.
Label Smoothing and Logit Squeezing: A Replacement for Adversarial Training?
Oct 25, 2019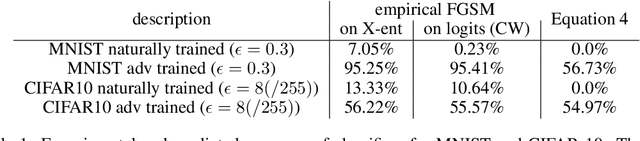
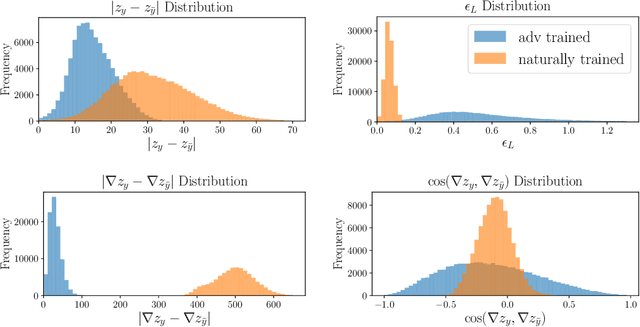
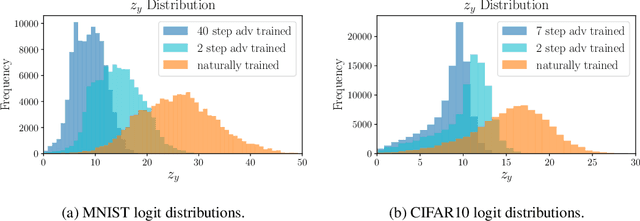
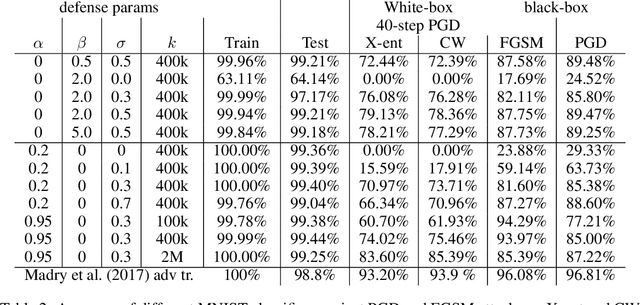
Adversarial training is one of the strongest defenses against adversarial attacks, but it requires adversarial examples to be generated for every mini-batch during optimization. The expense of producing these examples during training often precludes adversarial training from use on complex image datasets. In this study, we explore the mechanisms by which adversarial training improves classifier robustness, and show that these mechanisms can be effectively mimicked using simple regularization methods, including label smoothing and logit squeezing. Remarkably, using these simple regularization methods in combination with Gaussian noise injection, we are able to achieve strong adversarial robustness -- often exceeding that of adversarial training -- using no adversarial examples.
Adversarially robust transfer learning
May 20, 2019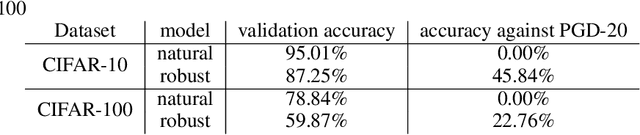
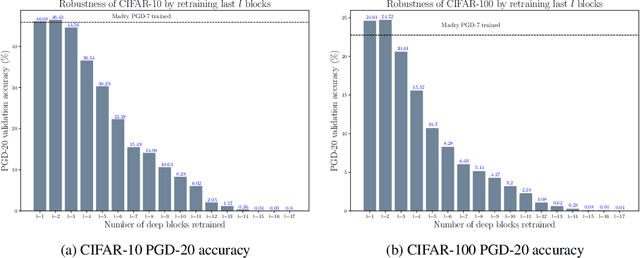
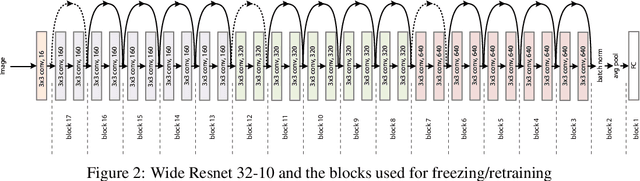
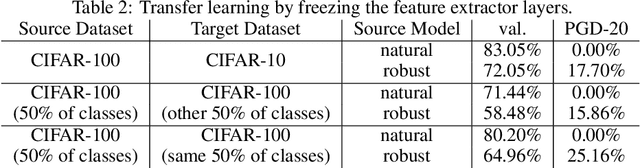
Transfer learning, in which a network is trained on one task and re-purposed on another, is often used to produce neural network classifiers when data is scarce or full-scale training is too costly. When the goal is to produce a model that is not only accurate but also adversarially robust, data scarcity and computational limitations become even more cumbersome. We consider robust transfer learning, in which we transfer not only performance but also robustness from a source model to a target domain. We start by observing that robust networks contain robust feature extractors. By training classifiers on top of these feature extractors, we produce new models that inherit the robustness of their parent networks. We then consider the case of fine-tuning a network by re-training end-to-end in the target domain. When using lifelong learning strategies, this process preserves the robustness of the source network while achieving high accuracy. By using such strategies, it is possible to produce accurate and robust models with little data, and without the cost of adversarial training.