 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Quantization and Pruning via Data-free Knowledge Transfer
Paper and Code
Oct 14, 2020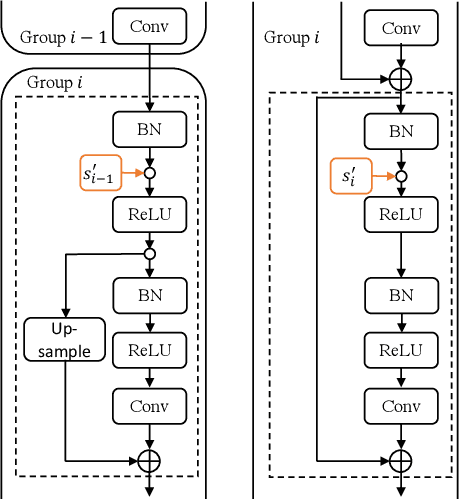
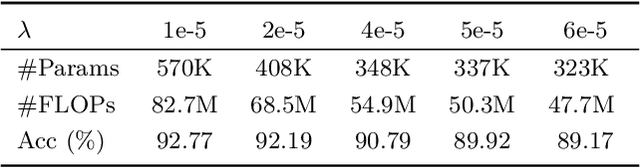
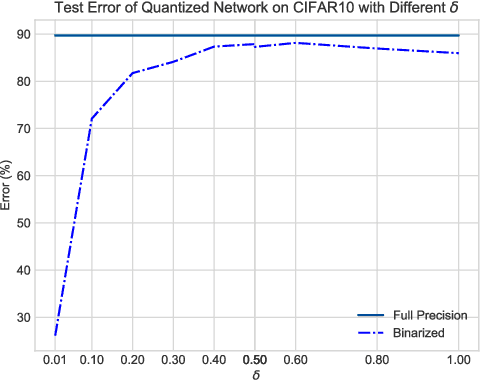
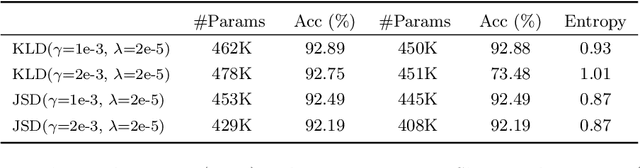
When large scale training data is available, one can obtain compact and accurate networks to be deployed in resource-constrained environments effectively through quantization and pruning. However, training data are often protected due to privacy concerns and it is challenging to obtain compact networks without data. We study data-free quantization and pruning by transferring knowledge from trained large networks to compact networks. Auxiliary generators are simultaneously and adversarially trained with the targeted compact networks to generate synthetic inputs that maximize the discrepancy between the given large network and its quantized or pruned version. We show theoretically that the alternating optimization for the underlying minimax problem converges under mild conditions for pruning and quantization. Our data-free compact networks achieve competitive accuracy to networks trained and fine-tuned with training data. Our quantized and pruned networks achieve good performance while being more compact and lightweight. Further, we demonstrate that the compact structure and corresponding initialization from the Lottery Ticket Hypothesis can also help in data-free training.