 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion Models are Secretly Good at Visual In-Context Learning
Aug 13, 2025Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) -- the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These approaches involve specialized training and/or additional data that complicate the process and limit its generalizability. In this work, we show that off-the-shelf Stable Diffusion models can be repurposed for visual in-context learning (V-ICL). Specifically, we formulate an in-place attention re-computation within the self-attention layers of the Stable Diffusion architecture that explicitly incorporates context between the query and example prompts. Without any additional fine-tuning, we show that this repurposed Stable Diffusion model is able to adapt to six different tasks: foreground segmentation, single object detection, semantic segmentation, keypoint detection, edge detection, and colorization. For example, the proposed approach improves the mean intersection over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by 8.9% and 3.2% over recent methods such as Visual Prompting and IMProv, respectively. Additionally, we show that the proposed method is able to effectively leverage multiple prompts through ensembling to infer the task better and further improve the performance.
Adaptive Weight Decay: On The Fly Weight Decay Tuning for Improving Robustness
Sep 30, 2022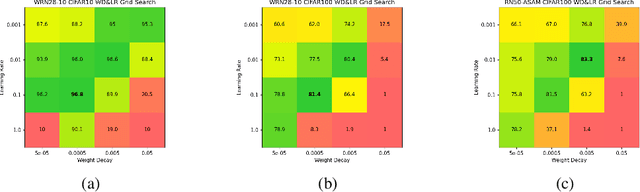


We introduce adaptive weight decay, which automatically tunes the hyper-parameter for weight decay during each training iteration. For classification problems, we propose changing the value of the weight decay hyper-parameter on the fly based on the strength of updates from the classification loss (i.e., gradient of cross-entropy), and the regularization loss (i.e., $\ell_2$-norm of the weights). We show that this simple modification can result in large improvements in adversarial robustness -- an area which suffers from robust overfitting -- without requiring extra data. Specifically, our reformulation results in 20% relative robustness improvement for CIFAR-100, and 10% relative robustness improvement on CIFAR-10 comparing to traditional weight decay. In addition, this method has other desirable properties, such as less sensitivity to learning rate, and smaller weight norms, which the latter contributes to robustness to overfitting to label noise, and pruning.