 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Convex Polyhedra Optimization from Multi-view Images
Jul 22, 2024This paper presents a novel approach for the differentiable rendering of convex polyhedra, addressing the limitations of recent methods that rely on implicit field supervision. Our technique introduces a strategy that combines non-differentiable computation of hyperplane intersection through duality transform with differentiable optimization for vertex positioning with three-plane intersection, enabling gradient-based optimization without the need for 3D implicit fields. This allows for efficient shape representation across a range of applications, from shape parsing to compact mesh reconstruction. This work not only overcomes the challenges of previous approaches but also sets a new standard for representing shapes with convex polyhedra.
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
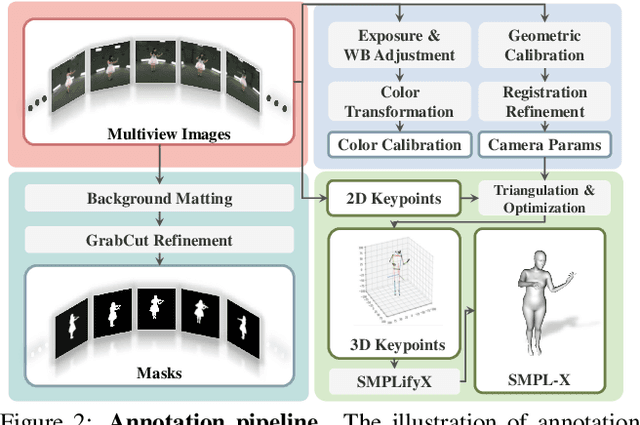
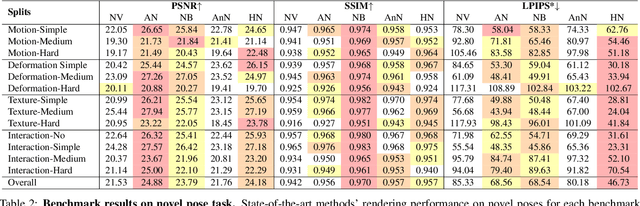

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/
ExtrudeNet: Unsupervised Inverse Sketch-and-Extrude for Shape Parsing
Sep 30, 2022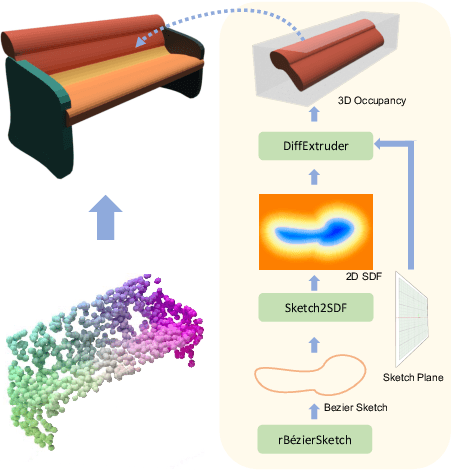

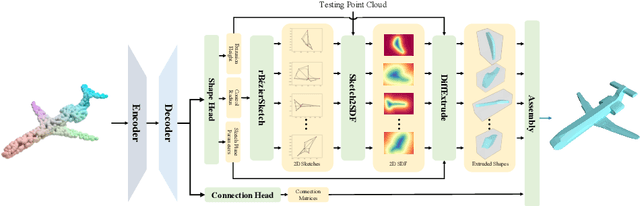

Sketch-and-extrude is a common and intuitive modeling process in computer aided design. This paper studies the problem of learning the shape given in the form of point clouds by inverse sketch-and-extrude. We present ExtrudeNet, an unsupervised end-to-end network for discovering sketch and extrude from point clouds. Behind ExtrudeNet are two new technical components: 1) an effective representation for sketch and extrude, which can model extrusion with freeform sketches and conventional cylinder and box primitives as well; and 2) a numerical method for computing the signed distance field which is used in the network learning. This is the first attempt that uses machine learning to reverse engineer the sketch-and-extrude modeling process of a shape in an unsupervised fashion. ExtrudeNet not only outputs a compact, editable and interpretable representation of the shape that can be seamlessly integrated into modern CAD software, but also aligns with the standard CAD modeling process facilitating various editing applications, which distinguishes our work from existing shape parsing research. Code is released at https://github.com/kimren227/ExtrudeNet.
Monocular 3D Object Reconstruction with GAN Inversion
Jul 20, 2022
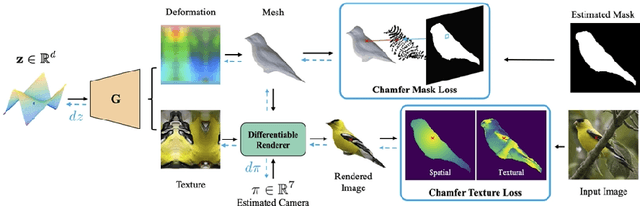

Recovering a textured 3D mesh from a monocular image is highly challenging, particularly for in-the-wild objects that lack 3D ground truths. In this work, we present MeshInversion, a novel framework to improve the reconstruction by exploiting the generative prior of a 3D GAN pre-trained for 3D textured mesh synthesis. Reconstruction is achieved by searching for a latent space in the 3D GAN that best resembles the target mesh in accordance with the single view observation. Since the pre-trained GAN encapsulates rich 3D semantics in terms of mesh geometry and texture, searching within the GAN manifold thus naturally regularizes the realness and fidelity of the reconstruction. Importantly, such regularization is directly applied in the 3D space, providing crucial guidance of mesh parts that are unobserved in the 2D space. Experiments on standard benchmarks show that our framework obtains faithful 3D reconstructions with consistent geometry and texture across both observed and unobserved parts. Moreover, it generalizes well to meshes that are less commonly seen, such as the extended articulation of deformable objects. Code is released at https://github.com/junzhezhang/mesh-inversion
HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Apr 28, 2022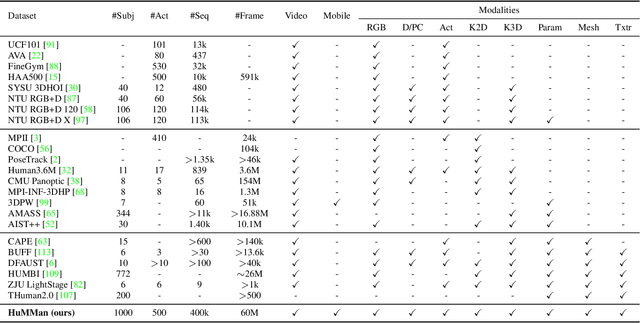
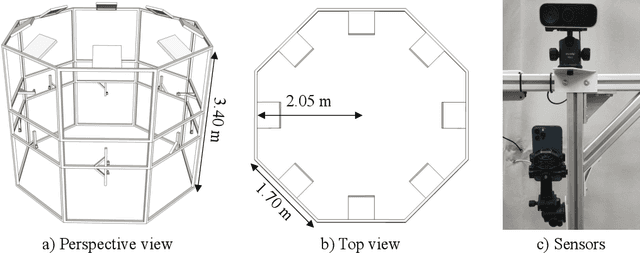

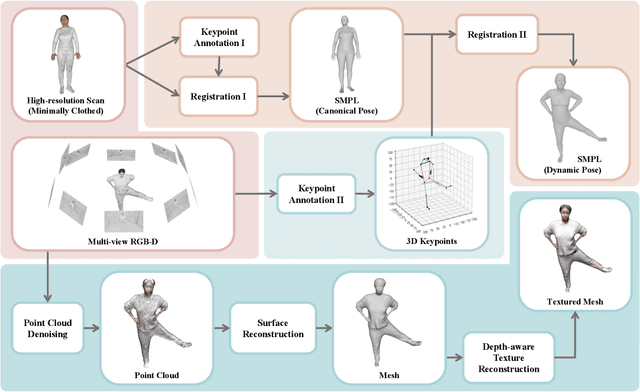
4D human sensing and modeling are fundamental tasks in vision and graphics with numerous applications. With the advances of new sensors and algorithms, there is an increasing demand for more versatile datasets. In this work, we contribute HuMMan, a large-scale multi-modal 4D human dataset with 1000 human subjects, 400k sequences and 60M frames. HuMMan has several appealing properties: 1) multi-modal data and annotations including color images, point clouds, keypoints, SMPL parameters, and textured meshes; 2) popular mobile device is included in the sensor suite; 3) a set of 500 actions, designed to cover fundamental movements; 4) multiple tasks such as action recognition, pose estimation, parametric human recovery, and textured mesh reconstruction are supported and evaluated. Extensive experiments on HuMMan voice the need for further study on challenges such as fine-grained action recognition, dynamic human mesh reconstruction, point cloud-based parametric human recovery, and cross-device domain gaps.
Playing for 3D Human Recovery
Oct 14, 2021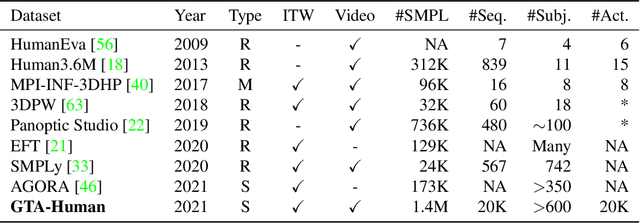

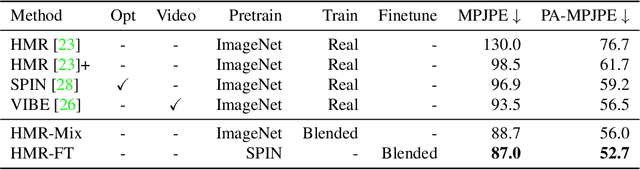
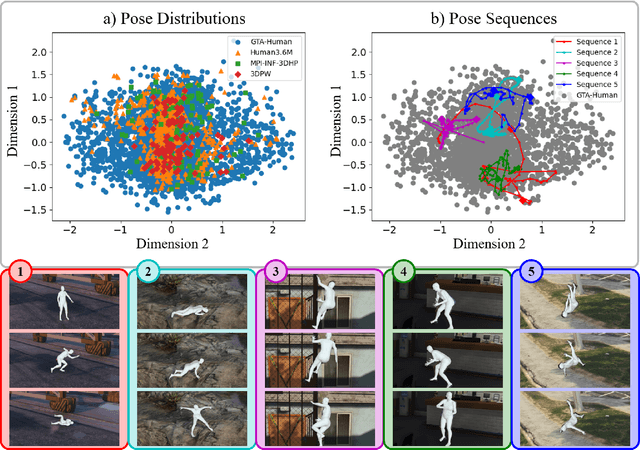
Image- and video-based 3D human recovery (i.e. pose and shape estimation) have achieved substantial progress. However, due to the prohibitive cost of motion capture, existing datasets are often limited in scale and diversity, which hinders the further development of more powerful models. In this work, we obtain massive human sequences as well as their 3D ground truths by playing video games. Specifically, we contribute, GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine. With a rich set of subjects, actions, and scenarios, GTA-Human serves as both an effective training source. Notably, the "unreasonable effectiveness of data" phenomenon is validated in 3D human recovery using our game-playing data. A simple frame-based baseline trained on GTA-Human already outperforms more sophisticated methods by a large margin; for video-based methods, GTA-Human demonstrates superiority over even the in-domain training set. We extend our study to larger models to observe the same consistent improvements, and the study on supervision signals suggests the rich collection of SMPL annotations is key. Furthermore, equipped with the diverse annotations in GTA-Human, we systematically investigate the performance of various methods under a wide spectrum of real-world variations, e.g. camera angles, poses, and occlusions. We hope our work could pave way for scaling up 3D human recovery to the real world.
CSG-Stump: A Learning Friendly CSG-Like Representation for Interpretable Shape Parsing
Aug 25, 2021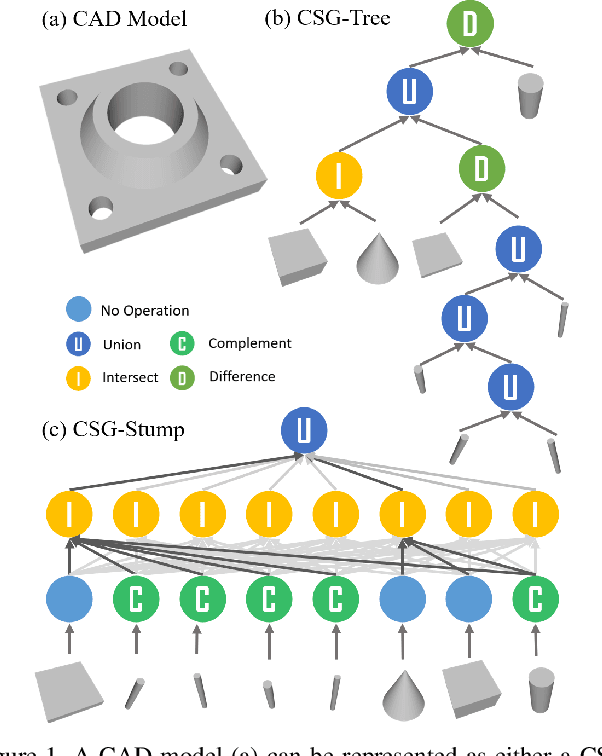

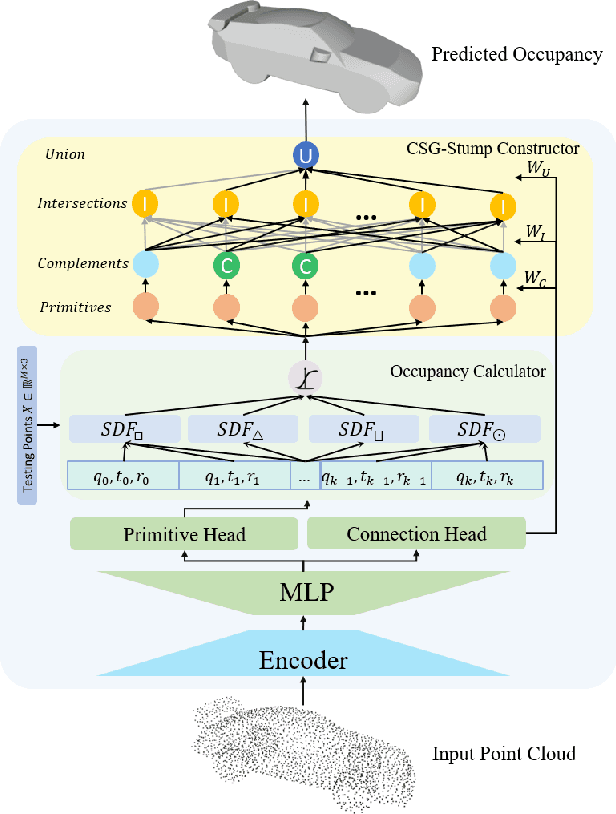
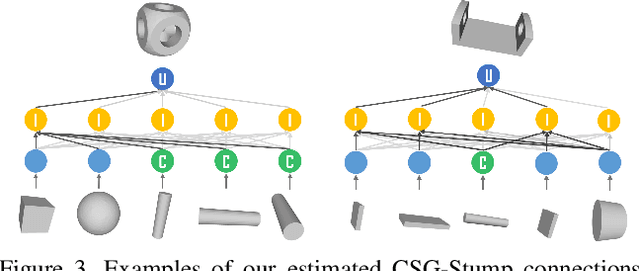
Generating an interpretable and compact representation of 3D shapes from point clouds is an important and challenging problem. This paper presents CSG-Stump Net, an unsupervised end-to-end network for learning shapes from point clouds and discovering the underlying constituent modeling primitives and operations as well. At the core is a three-level structure called {\em CSG-Stump}, consisting of a complement layer at the bottom, an intersection layer in the middle, and a union layer at the top. CSG-Stump is proven to be equivalent to CSG in terms of representation, therefore inheriting the interpretable, compact and editable nature of CSG while freeing from CSG's complex tree structures. Particularly, the CSG-Stump has a simple and regular structure, allowing neural networks to give outputs of a constant dimensionality, which makes itself deep-learning friendly. Due to these characteristics of CSG-Stump, CSG-Stump Net achieves superior results compared to previous CSG-based methods and generates much more appealing shapes, as confirmed by extensive experiments. Project page: https://kimren227.github.io/projects/CSGStump/
MessyTable: Instance Association in Multiple Camera Views
Jul 29, 2020


We present an interesting and challenging dataset that features a large number of scenes with messy tables captured from multiple camera views. Each scene in this dataset is highly complex, containing multiple object instances that could be identical, stacked and occluded by other instances. The key challenge is to associate all instances given the RGB image of all views. The seemingly simple task surprisingly fails many popular methods or heuristics that we assume good performance in object association. The dataset challenges existing methods in mining subtle appearance differences, reasoning based on contexts, and fusing appearance with geometric cues for establishing an association. We report interesting findings with some popular baselines, and discuss how this dataset could help inspire new problems and catalyse more robust formulations to tackle real-world instance association problems. Project page: $\href{https://caizhongang.github.io/projects/MessyTable/}{\text{MessyTable}}$
Leveraging Temporal Information for 3D Detection and Domain Adaptation
Jun 30, 2020
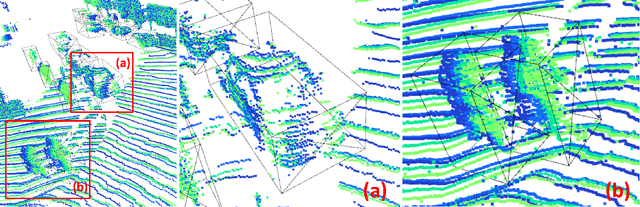

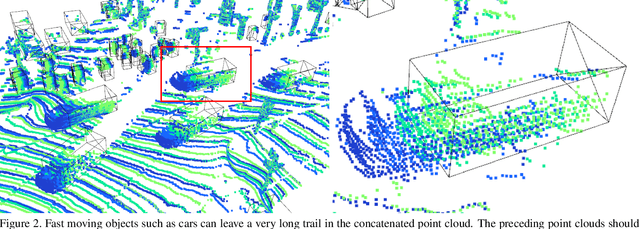
Ever since the prevalent use of the LiDARs in autonomous driving, tremendous improvements have been made to the learning on the point clouds. However, recent progress largely focuses on detecting objects in a single 360-degree sweep, without extensively exploring the temporal information. In this report, we describe a simple way to pass such information in the learning pipeline by adding timestamps to the point clouds, which shows consistent improvements across all three classes.