 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying for 3D Human Recovery
Paper and Code
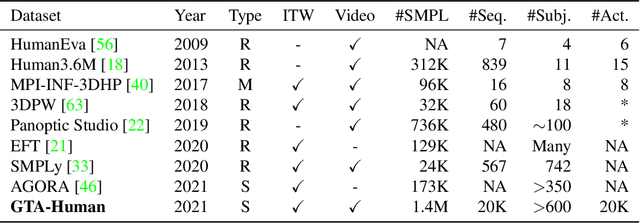

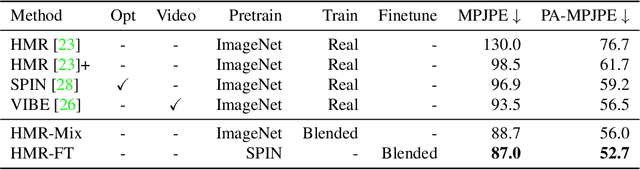
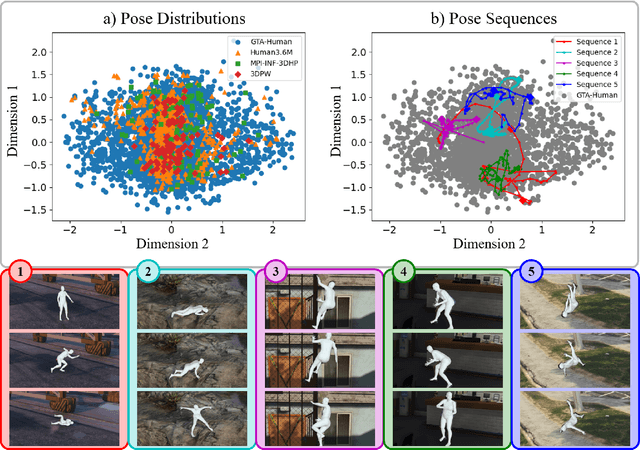
Image- and video-based 3D human recovery (i.e. pose and shape estimation) have achieved substantial progress. However, due to the prohibitive cost of motion capture, existing datasets are often limited in scale and diversity, which hinders the further development of more powerful models. In this work, we obtain massive human sequences as well as their 3D ground truths by playing video games. Specifically, we contribute, GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine. With a rich set of subjects, actions, and scenarios, GTA-Human serves as both an effective training source. Notably, the "unreasonable effectiveness of data" phenomenon is validated in 3D human recovery using our game-playing data. A simple frame-based baseline trained on GTA-Human already outperforms more sophisticated methods by a large margin; for video-based methods, GTA-Human demonstrates superiority over even the in-domain training set. We extend our study to larger models to observe the same consistent improvements, and the study on supervision signals suggests the rich collection of SMPL annotations is key. Furthermore, equipped with the diverse annotations in GTA-Human, we systematically investigate the performance of various methods under a wide spectrum of real-world variations, e.g. camera angles, poses, and occlusions. We hope our work could pave way for scaling up 3D human recovery to the real world.