 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotVL: Human-Centric Highlight Frame Retrieval via Language Queries
Dec 17, 2024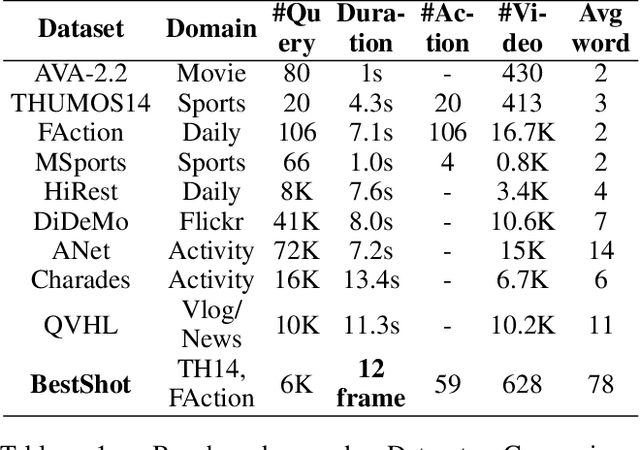

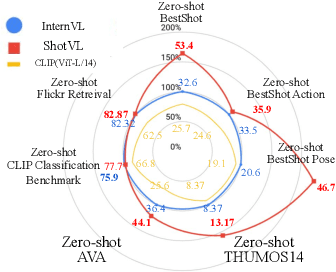
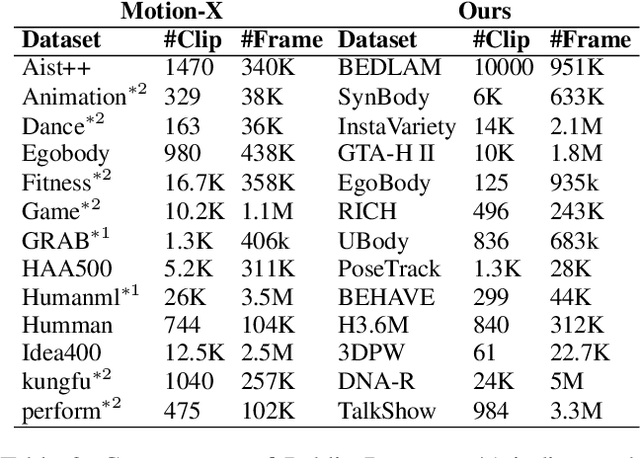
Existing works on human-centric video understanding typically focus on analyzing specific moment or entire videos. However, many applications require higher precision at the frame level. In this work, we propose a novel task, BestShot, which aims to locate highlight frames within human-centric videos via language queries. This task demands not only a deep semantic comprehension of human actions but also precise temporal localization. To support this task, we introduce the BestShot Benchmark. %The benchmark is meticulously constructed by combining human detection and tracking, potential frame selection based on human judgment, and detailed textual descriptions crafted by human input to ensure precision. The benchmark is meticulously constructed by combining human-annotated highlight frames, detailed textual descriptions and duration labeling. These descriptions encompass three critical elements: (1) Visual content; (2) Fine-grained action; and (3) Human Pose Description. Together, these elements provide the necessary precision to identify the exact highlight frames in videos. To tackle this problem, we have collected two distinct datasets: (i) ShotGPT4o Dataset, which is algorithmically generated by GPT-4o and (ii) Image-SMPLText Dataset, a dataset with large-scale and accurate per-frame pose description leveraging PoseScript and existing pose estimation datasets. Based on these datasets, we present a strong baseline model, ShotVL, fine-tuned from InternVL, specifically for BestShot. We highlight the impressive zero-shot capabilities of our model and offer comparative analyses with existing SOTA models. ShotVL demonstrates a significant 52% improvement over InternVL on the BestShot Benchmark and a notable 57% improvement on the THUMOS14 Benchmark, all while maintaining the SOTA performance in general image classification and retrieval.
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
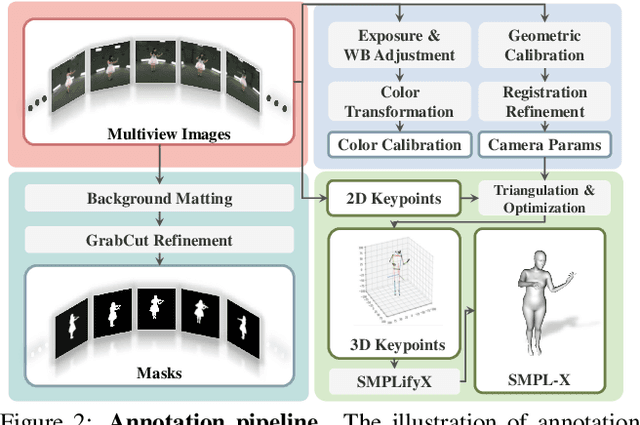
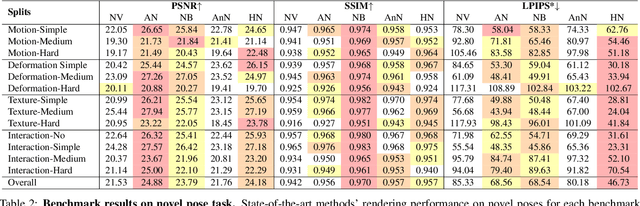

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023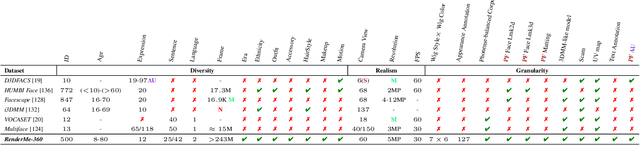
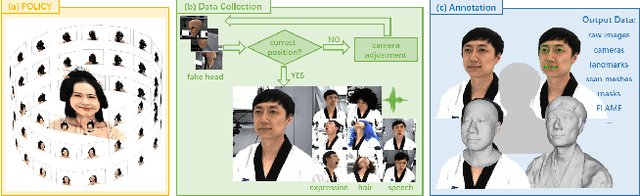


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.
Simulating Fluids in Real-World Still Images
Apr 24, 2022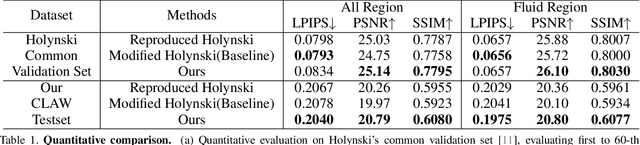
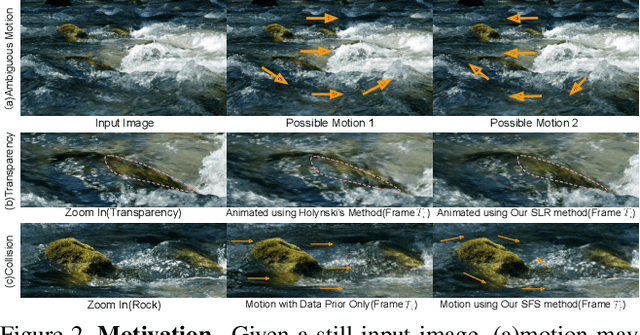
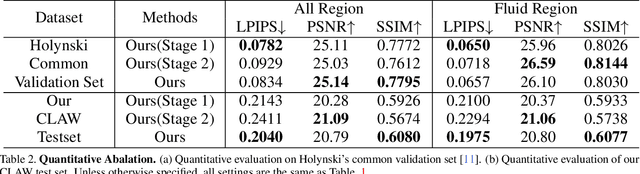
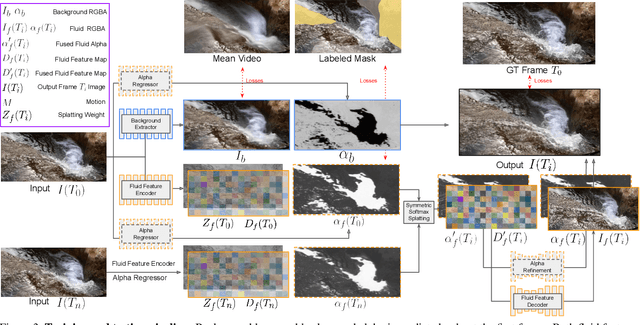
In this work, we tackle the problem of real-world fluid animation from a still image. The key of our system is a surface-based layered representation deriving from video decomposition, where the scene is decoupled into a surface fluid layer and an impervious background layer with corresponding transparencies to characterize the composition of the two layers. The animated video can be produced by warping only the surface fluid layer according to the estimation of fluid motions and recombining it with the background. In addition, we introduce surface-only fluid simulation, a $2.5D$ fluid calculation version, as a replacement for motion estimation. Specifically, we leverage the triangular mesh based on a monocular depth estimator to represent the fluid surface layer and simulate the motion in the physics-based framework with the inspiration of the classic theory of the hybrid Lagrangian-Eulerian method, along with a learnable network so as to adapt to complex real-world image textures. We demonstrate the effectiveness of the proposed system through comparison with existing methods in both standard objective metrics and subjective ranking scores. Extensive experiments not only indicate our method's competitive performance for common fluid scenes but also better robustness and reasonability under complex transparent fluid scenarios. Moreover, as the proposed surface-based layer representation and surface-only fluid simulation naturally disentangle the scene, interactive editing such as adding objects to the river and texture replacing could be easily achieved with realistic results.