 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
Aug 18, 2025


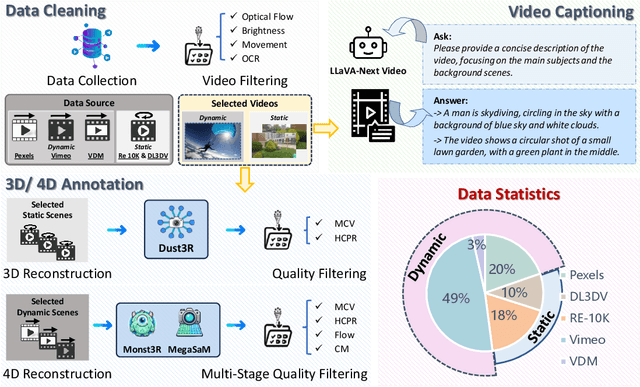
We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) to alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) we introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) we propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for 4D modeling. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX outperforms existing 4D generation methods in efficiency and generalizability, offering a scalable solution for image-to-4D modeling and laying the foundation for generative 4D world models that simulate dynamic scene evolution.
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
Aug 07, 2025



Despite rapid advances in 3D content generation, quality assessment for the generated 3D assets remains challenging. Existing methods mainly rely on image-based metrics and operate solely at the object level, limiting their ability to capture spatial coherence, material authenticity, and high-fidelity local details. 1) To address these challenges, we introduce Hi3DEval, a hierarchical evaluation framework tailored for 3D generative content. It combines both object-level and part-level evaluation, enabling holistic assessments across multiple dimensions as well as fine-grained quality analysis. Additionally, we extend texture evaluation beyond aesthetic appearance by explicitly assessing material realism, focusing on attributes such as albedo, saturation, and metallicness. 2) To support this framework, we construct Hi3DBench, a large-scale dataset comprising diverse 3D assets and high-quality annotations, accompanied by a reliable multi-agent annotation pipeline. We further propose a 3D-aware automated scoring system based on hybrid 3D representations. Specifically, we leverage video-based representations for object-level and material-subject evaluations to enhance modeling of spatio-temporal consistency and employ pretrained 3D features for part-level perception. Extensive experiments demonstrate that our approach outperforms existing image-based metrics in modeling 3D characteristics and achieves superior alignment with human preference, providing a scalable alternative to manual evaluations. The project page is available at https://zyh482.github.io/Hi3DEval/.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025
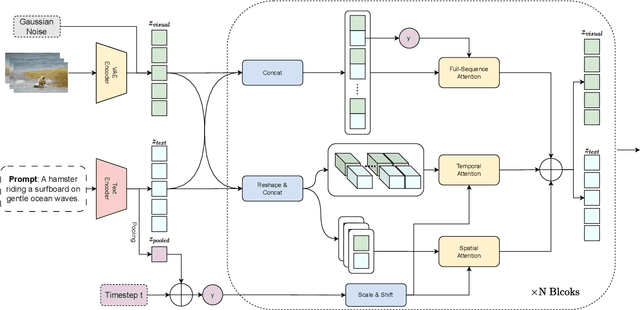
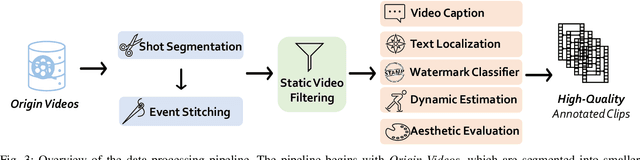
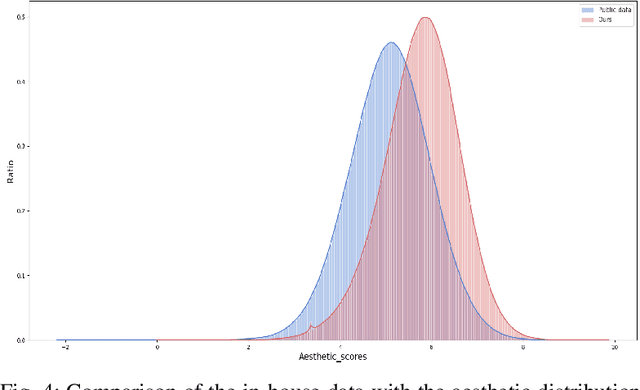
We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
Evading Detection Actively: Toward Anti-Forensics against Forgery Localization
Oct 16, 2023
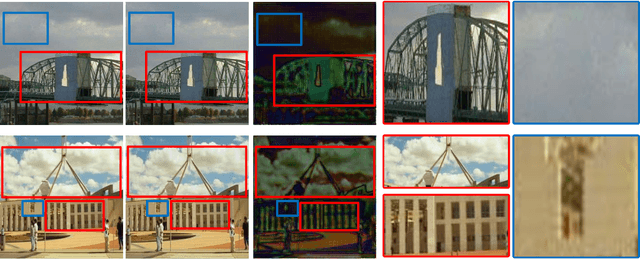
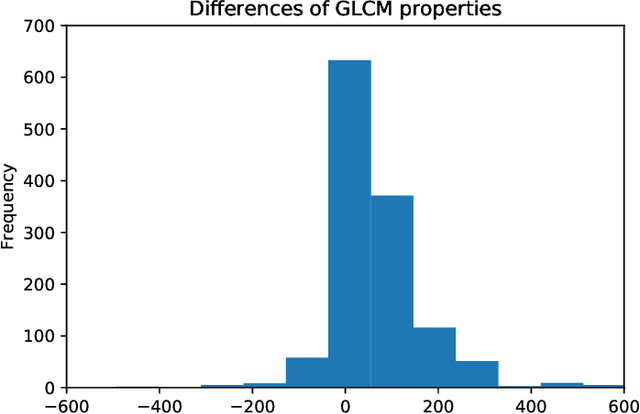

Anti-forensics seeks to eliminate or conceal traces of tampering artifacts. Typically, anti-forensic methods are designed to deceive binary detectors and persuade them to misjudge the authenticity of an image. However, to the best of our knowledge, no attempts have been made to deceive forgery detectors at the pixel level and mis-locate forged regions. Traditional adversarial attack methods cannot be directly used against forgery localization due to the following defects: 1) they tend to just naively induce the target forensic models to flip their pixel-level pristine or forged decisions; 2) their anti-forensics performance tends to be severely degraded when faced with the unseen forensic models; 3) they lose validity once the target forensic models are retrained with the anti-forensics images generated by them. To tackle the three defects, we propose SEAR (Self-supErvised Anti-foRensics), a novel self-supervised and adversarial training algorithm that effectively trains deep-learning anti-forensic models against forgery localization. SEAR sets a pretext task to reconstruct perturbation for self-supervised learning. In adversarial training, SEAR employs a forgery localization model as a supervisor to explore tampering features and constructs a deep-learning concealer to erase corresponding traces. We have conducted largescale experiments across diverse datasets. The experimental results demonstrate that, through the combination of self-supervised learning and adversarial learning, SEAR successfully deceives the state-of-the-art forgery localization methods, as well as tackle the three defects regarding traditional adversarial attack methods mentioned above.
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023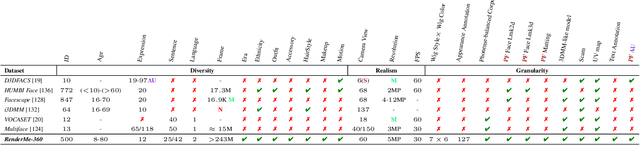
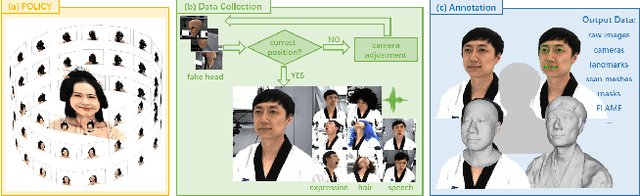


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.
Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis
Jul 11, 2022
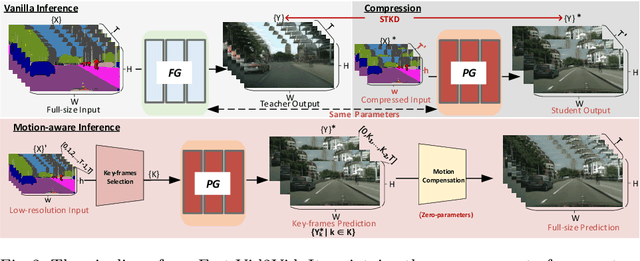
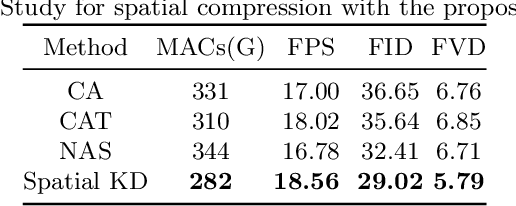
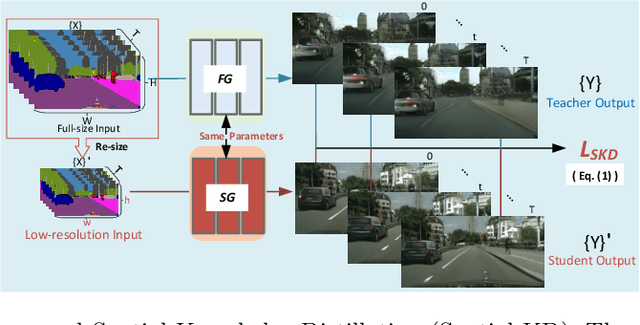
Video-to-Video synthesis (Vid2Vid) has achieved remarkable results in generating a photo-realistic video from a sequence of semantic maps. However, this pipeline suffers from high computational cost and long inference latency, which largely depends on two essential factors: 1) network architecture parameters, 2) sequential data stream. Recently, the parameters of image-based generative models have been significantly compressed via more efficient network architectures. Nevertheless, existing methods mainly focus on slimming network architectures and ignore the size of the sequential data stream. Moreover, due to the lack of temporal coherence, image-based compression is not sufficient for the compression of the video task. In this paper, we present a spatial-temporal compression framework, \textbf{Fast-Vid2Vid}, which focuses on data aspects of generative models. It makes the first attempt at time dimension to reduce computational resources and accelerate inference. Specifically, we compress the input data stream spatially and reduce the temporal redundancy. After the proposed spatial-temporal knowledge distillation, our model can synthesize key-frames using the low-resolution data stream. Finally, Fast-Vid2Vid interpolates intermediate frames by motion compensation with slight latency. On standard benchmarks, Fast-Vid2Vid achieves around real-time performance as 20 FPS and saves around 8x computational cost on a single V100 GPU.
Self-Adversarial Training incorporating Forgery Attention for Image Forgery Localization
Jul 06, 2021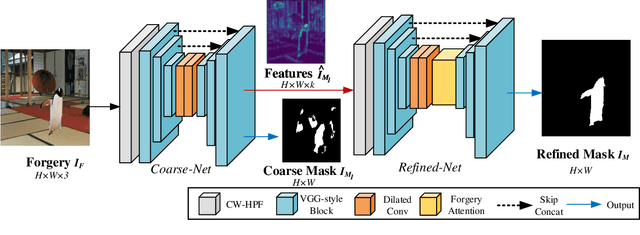
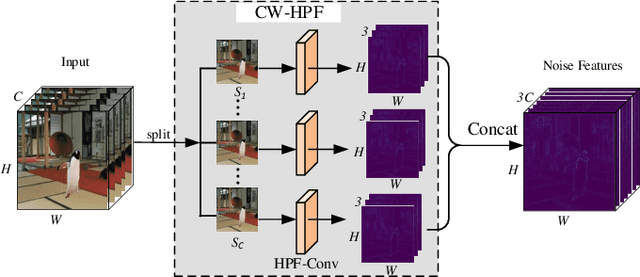
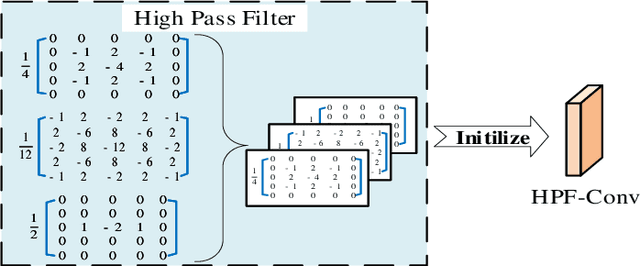
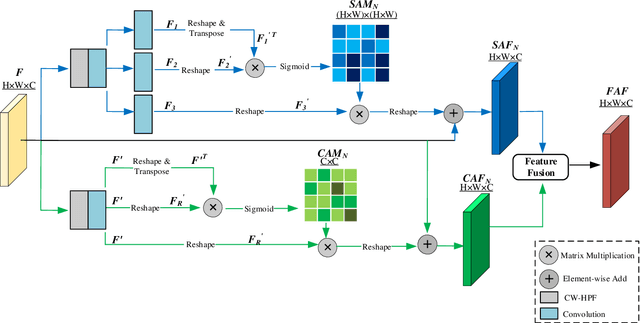
Image editing techniques enable people to modify the content of an image without leaving visual traces and thus may cause serious security risks. Hence the detection and localization of these forgeries become quite necessary and challenging. Furthermore, unlike other tasks with extensive data, there is usually a lack of annotated forged images for training due to annotation difficulties. In this paper, we propose a self-adversarial training strategy and a reliable coarse-to-fine network that utilizes a self-attention mechanism to localize forged regions in forgery images. The self-attention module is based on a Channel-Wise High Pass Filter block (CW-HPF). CW-HPF leverages inter-channel relationships of features and extracts noise features by high pass filters. Based on the CW-HPF, a self-attention mechanism, called forgery attention, is proposed to capture rich contextual dependencies of intrinsic inconsistency extracted from tampered regions. Specifically, we append two types of attention modules on top of CW-HPF respectively to model internal interdependencies in spatial dimension and external dependencies among channels. We exploit a coarse-to-fine network to enhance the noise inconsistency between original and tampered regions. More importantly, to address the issue of insufficient training data, we design a self-adversarial training strategy that expands training data dynamically to achieve more robust performance. Specifically, in each training iteration, we perform adversarial attacks against our network to generate adversarial examples and train our model on them. Extensive experimental results demonstrate that our proposed algorithm steadily outperforms state-of-the-art methods by a clear margin in different benchmark datasets.