 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
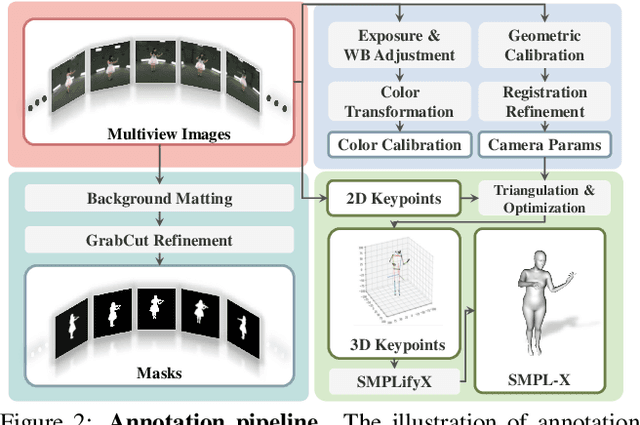
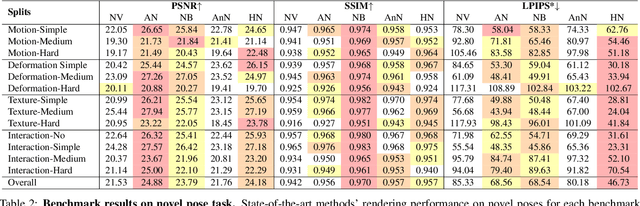

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023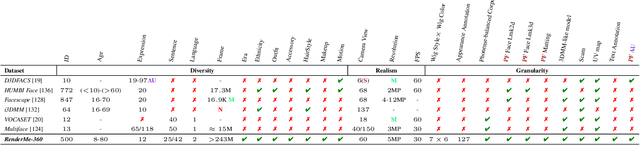
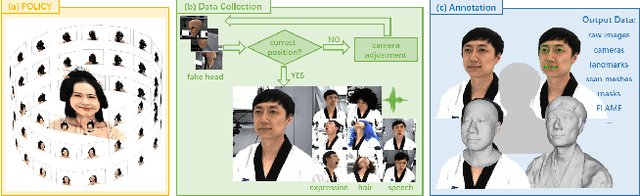


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


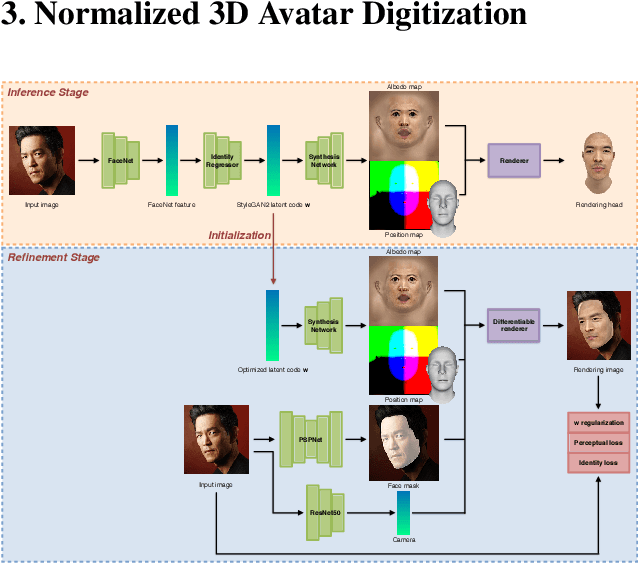
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.