 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONE-SHOT: Compositional Human-Environment Video Synthesis via Spatial-Decoupled Motion Injection and Hybrid Context Integration
Apr 01, 2026Recent advances in Video Foundation Models (VFMs) have revolutionized human-centric video synthesis, yet fine-grained and independent editing of subjects and scenes remains a critical challenge. Recent attempts to incorporate richer environment control through rigid 3D geometric compositions often encounter a stark trade-off between precise control and generative flexibility. Furthermore, the heavy 3D pre-processing still limits practical scalability. In this paper, we propose ONE-SHOT, a parameter-efficient framework for compositional human-environment video generation. Our key insight is to factorize the generative process into disentangled signals. Specifically, we introduce a canonical-space injection mechanism that decouples human dynamics from environmental cues via cross-attention. We also propose Dynamic-Grounded-RoPE, a novel positional embedding strategy that establishes spatial correspondences between disparate spatial domains without any heuristic 3D alignments. To support long-horizon synthesis, we introduce a Hybrid Context Integration mechanism to maintain subject and scene consistency across minute-level generations. Experiments demonstrate that our method significantly outperforms state-of-the-art methods, offering superior structural control and creative diversity for video synthesis. Our project has been available on: https://martayang.github.io/ONE-SHOT/.
InterDyad: Interactive Dyadic Speech-to-Video Generation by Querying Intermediate Visual Guidance
Mar 24, 2026Despite progress in speech-to-video synthesis, existing methods often struggle to capture cross-individual dependencies and provide fine-grained control over reactive behaviors in dyadic settings. To address these challenges, we propose InterDyad, a framework that enables naturalistic interactive dynamics synthesis via querying structural motion guidance. Specifically, we first design an Interactivity Injector that achieves video reenactment based on identity-agnostic motion priors extracted from reference videos. Building upon this, we introduce a MetaQuery-based modality alignment mechanism to bridge the gap between conversational audio and these motion priors. By leveraging a Multimodal Large Language Model (MLLM), our framework is able to distill linguistic intent from audio to dictate the precise timing and appropriateness of reactions. To further improve lip-sync quality under extreme head poses, we propose Role-aware Dyadic Gaussian Guidance (RoDG) for enhanced lip-synchronization and spatial consistency. Finally, we introduce a dedicated evaluation suite with novelly designed metrics to quantify dyadic interaction. Comprehensive experiments demonstrate that InterDyad significantly outperforms state-of-the-art methods in producing natural and contextually grounded two-person interactions. Please refer to our project page for demo videos: https://interdyad.github.io/.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025
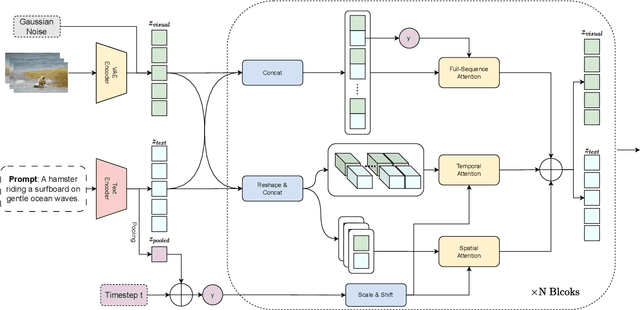
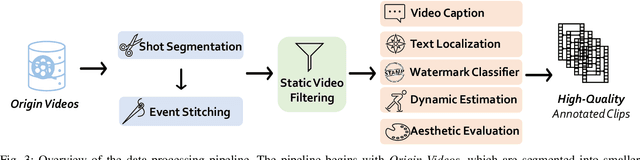
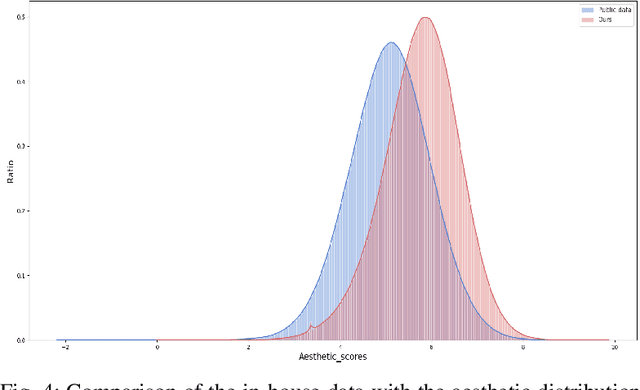
We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
TimeWalker: Personalized Neural Space for Lifelong Head Avatars
Dec 03, 2024



We present TimeWalker, a novel framework that models realistic, full-scale 3D head avatars of a person on lifelong scale. Unlike current human head avatar pipelines that capture identity at the momentary level(e.g., instant photography or short videos), TimeWalker constructs a person's comprehensive identity from unstructured data collection over his/her various life stages, offering a paradigm to achieve full reconstruction and animation of that person at different moments of life. At the heart of TimeWalker's success is a novel neural parametric model that learns personalized representation with the disentanglement of shape, expression, and appearance across ages. Central to our methodology are the concepts of two aspects: (1) We track back to the principle of modeling a person's identity in an additive combination of average head representation in the canonical space, and moment-specific head attribute representations driven from a set of neural head basis. To learn the set of head basis that could represent the comprehensive head variations in a compact manner, we propose a Dynamic Neural Basis-Blending Module (Dynamo). It dynamically adjusts the number and blend weights of neural head bases, according to both shared and specific traits of the target person over ages. (2) Dynamic 2D Gaussian Splatting (DNA-2DGS), an extension of Gaussian splatting representation, to model head motion deformations like facial expressions without losing the realism of rendering and reconstruction. DNA-2DGS includes a set of controllable 2D oriented planar Gaussian disks that utilize the priors from parametric model, and move/rotate with the change of expression. Through extensive experimental evaluations, we show TimeWalker's ability to reconstruct and animate avatars across decoupled dimensions with realistic rendering effects, demonstrating a way to achieve personalized 'time traveling' in a breeze.
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023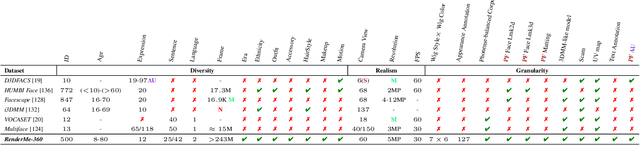
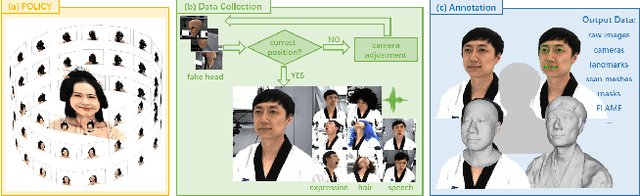


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.